Index란?
흔히들 사전의 색인이라 설명하지만 잘 와닿지 않는다. 사전에서 색인을 통해 무언가를 찾아본 경험이 적기 때문일까?
조금 더 쉽게 설명하자면 UP, DOWN 게임을 상상해보면 된다

누군가가 1부터 100까지의 숫자 중 하나를 선택하고 우리는 질문을 통해 그 수를 알아내야 한다고 해보자
크게 두 가지 형태의 질문이 있을 수 있는데
-
1부터 100까지 하나 하나 질문한다.
-
기준을 정해 그 수보다 큰지 작은지 질문한다.
(50보다 큰가요?)
1번 질문은 최악의 경우 100번의 질문을 해야 정답을 알아낼 수 있다. 그런데 2번 질문의 경우 아무리 많이 해도 6~7번의 질문을 통해 정답을 알아낼 수 있다.
이것을 가능하게 하는 것이 Index이고 우리는 데이터베이스 내 검색 효율성 향상을 위해 Index를 사용한다.
어떤 방식으로 구현하는가
Index가 어떤 것인지 알았다면 실제 데이터베이스에서 Index를 어떻게 구성하는지 알아볼 필요가 있다.
Index를 사용함에 있어 선행되어야 하는 요소들이 있는데
- 해당 테이블의 컬럼을 복사한 테이블이 존재해야한다
- 복사된 테이블은 검색을 실행하고자 하는 컬럼을 기준으로 정렬되어야 한다.
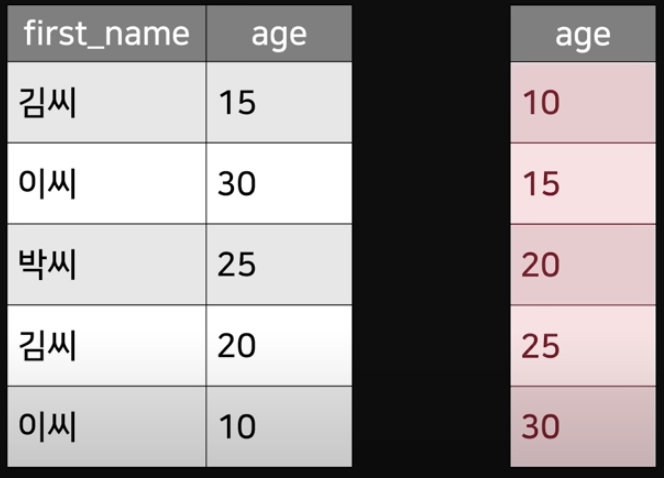
Index는 정렬된 테이블을 기준으로 데이터를 찾기 때문에 정렬이 필수이다.
데이터베이스 내 인덱싱 구조 (Binary Search Tree)
데이터베이스는 Index를 만들 때 이렇듯 Tree 구조를 통해 저장한다.
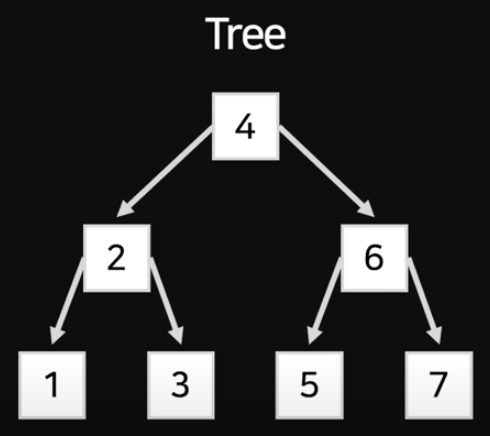
위에서 예시로 들었던 2가지 질문 중 2번 질문과 비슷한 형태인 것을 볼 수 있다.
혹시 더 효율적으로 만들 수는 없을까? (B-tree)
이전 Binary Search Tree에서 검색의 효율성을 더 향상시킬 수 있는 모델이 존재한다. 바로 B-tree다.
B-tree는 기준이 되는 데이터가 담겨있는 노드에 한 가지 데이터만을 담는 것이 아니라 여러 개의 데이터를 담아 검색의 효율성을 향상시킨다.
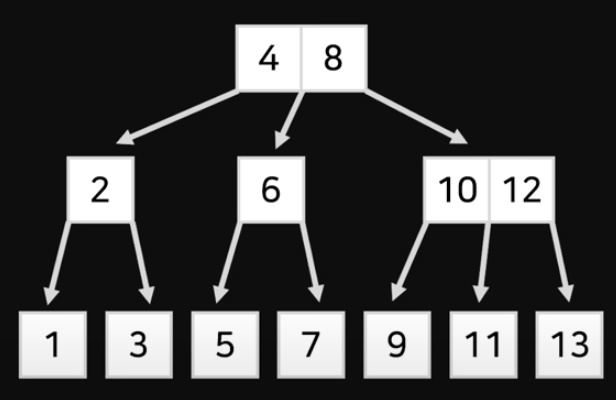
이렇게 B-tree 구조로 인덱스를 만들게 되면 동일한 횟수의 검색으로 더 넓은 범위의 데이터를 검색할 수 있게 된다.
근데 여기서 더 효율적으로 만들 수 없을까? (B+tree)
사실 B-tree도 상당히 효율적으로 보이는데 그보다 더 효율적인 Index 구조가 존재한다는 것이 놀랍기도 하다.
B+tree는 마지막 노드들에만 데이터를 저장해놓고 이를 연결한 후 상위 노드들에는 검색의 가이드만을 제시해놓는 형태이다.
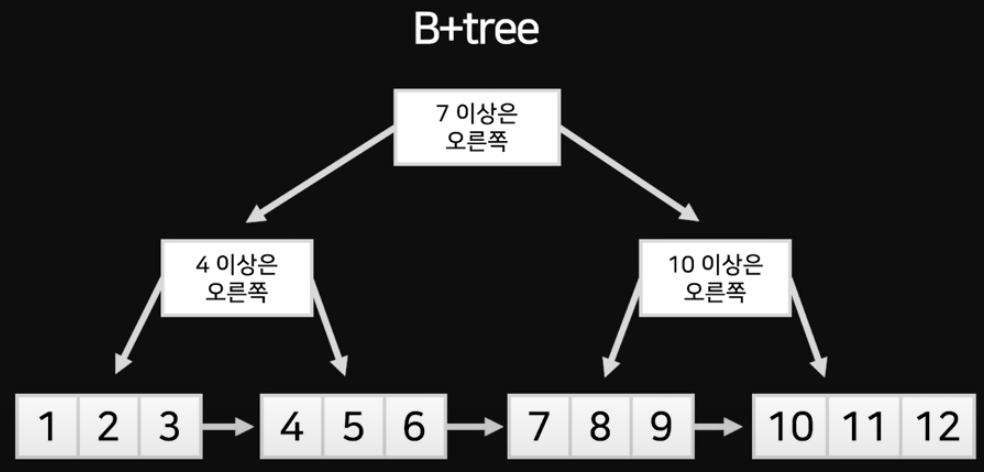
B+tree 구조의 인덱스를 이용하면 범위 검색에 상당히 유용하다.
이전의 인덱스들은 3~8에 해당하는 데이터를 찾을 때 위 아래로 왔다갔다 하며 데이터를 찾아야하지만 B+tree 인덱스는 3만 찾는다면 그 이후로 연결된 데이터를 가져오기만 하면 되기 때문이다.
단점은 없을까?
-
Index는 컬럼을 복사해서 정렬해두는 개념이기 때문에 데이터베이스의 용량을 차지할 수밖에 없다. 그렇기 때문에 검색이 필요하지 않은 테이블은 굳이 Index를 만들지 않아도 된다.
-
기존의 테이블에 데이터가 삽입되거나 수정, 삭제되었을 때 인덱스에도 똑같이 반영을 해주어야 한다. 따라서 성능 하락이 동반될 수 있다.
Index 사용을 통해 데이터베이스 성능을 고려하는 개발자가 되도록 하자
코딩애플님의 Youtube 영상을 참고해 포스팅했습니다.
