서밋 다녀온 후기
AWS Summit Seoul 2024를 다녀오고 후기에 대해서 공유하려고 합니다. 제가 느낀점 위주로 말하는 거니 쉽게 설명하도록 하겠습니다 ! 2023년과 2024년도의 달라진 점에 대해서 주로 작성을 하려합니다. 모든 강연을 보지 않았고 제가 관심있는 분야의 강연만 봤음을 미리 알려드립니다 :)
우아한 형제들, 삼성, 아모레 퍼시픽 강연을 들었지만, 블로그에 작성은 우아한 형제들 내용만 포스팅 하도록 하겠습니다 !
AI한테 서운한일 당함

당신은 오스트리아의 한 마을에서 대장장이 아버지를 따라 철 다루기를 배웠습니다. 남자들의 영역인 대장간에서 끊임없는 노력 끝에 실력을 인정받아 마을에서 가장 유명한 대장장이가 되었고, 그 모습이 초상화로 남게 되었습니다.
ㅋㅋ 닮았나요 ? 다른 분들은 군인, 황제, 마술사, 건축가 이런거 뜨는데 전 왜 대장장이일까
전체 강연 트랜드의 변화
2024년 강연 목록을 받았을 때, 2023년과 느낀점은 확실히 Gen AI가 트랜드구나 싶었습니다. 강연에 대부분 들어가는 AI, 그리고 Gen AI 섹션이 생긴거 보면 확실히 놓칠 수 없는 트랜드였습니다. 그 중에서도 AWS bedrock을 중심으로 세션과 부스가 이루어지는게 AWS에서 만든 생성형 AI인 Bedrock을 상당히 밀고 있다고 느껴졌습니다.
2023년 summit 키워드
- 클라우드 네이티브
- 대규모 트래픽 처리
- 데이터베이스의 활용과 변화
각 기업들이 클라우드 네이티브 서비스들을 사용해서 대규모 트래픽을 견디고 강화하기 위해 어떤 아키텍처를 생각하고 적용시켰는지에 대한 노력과 그 결과물을 발표했고, 트래픽을 견디기 위한 데이터베이스의 구체적인 활용이 돋보였던거 같습니다. 예를 들어, 식당 데이터의 경우 수정이 잘 일어나지 않고, 읽기 위주의 데이터다 보니, 읽기 속도가 빠르고, 성능이 좋은 NoSQL을 사용을 하고, 각 유저 데이터 같은 경우는 각 테이블 별로 종속성이 뛰어나니 RDS를 선택하는 모습이 인상적이었습니다.
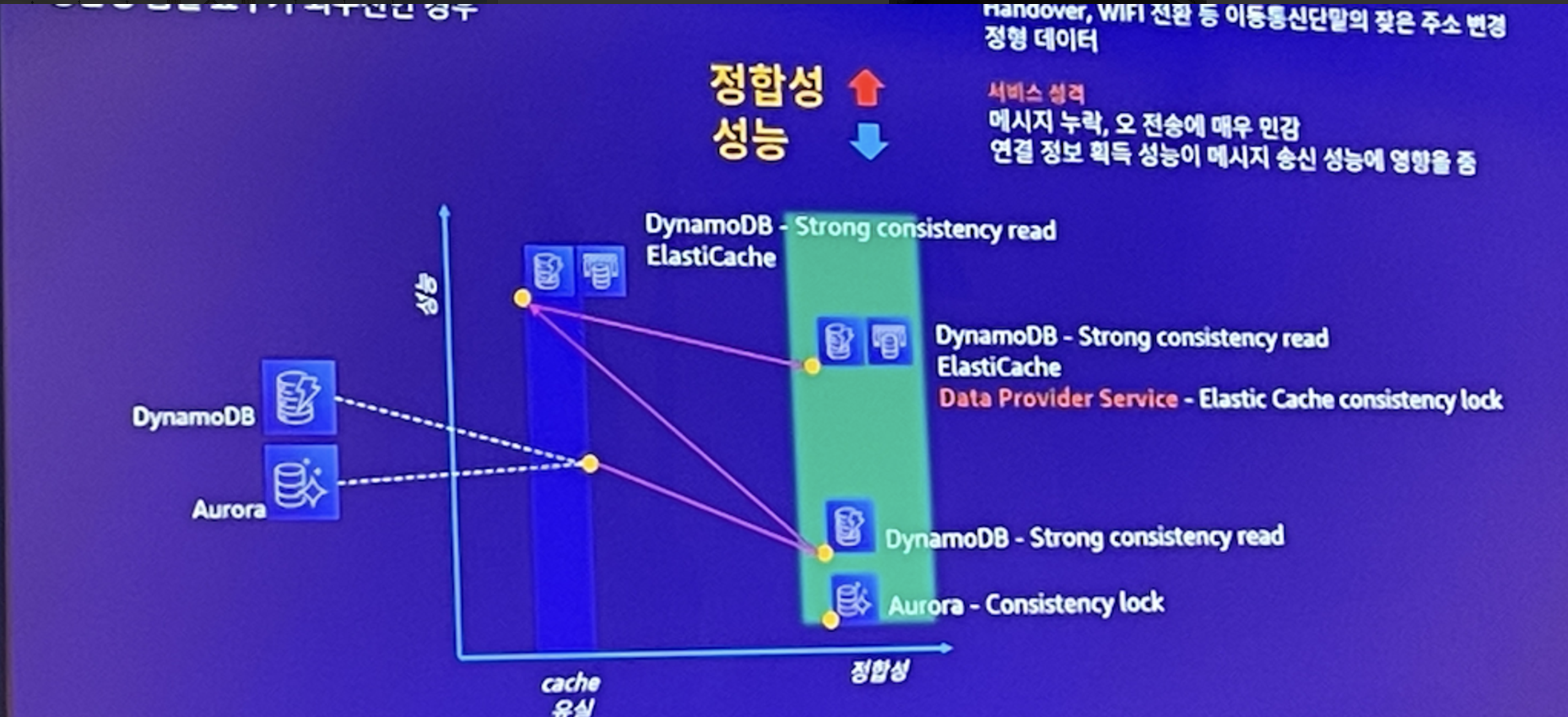
2024년 summit 키워드
- Gen AI
- AI 기반 데이터 분석
- 비용
AI가 독차지했다. 라고 표현해도 무방할 정도로 많은 기업에서 AI를 어떻게 사용했는지, 어떤 고민이 있었는지에 대한 강연이 두드러지고, Gen AI관련 강연은 자리가 없어서 못들어갈 정도로 사람이 붐볐습니다. 그리고 작년과 다르게 눈에 띄게 달라진점은 사람들의 연령대가 확 낮아졌다는 느낌을 받았습니다. 작년엔 대학생이 별로 없고 어른들,, 과장 부장 팀장님들이 오는 느낌이었으면, 이번엔 젊은 사람들이 많이 왔다고 느껴졌습니다.
또한 경기가 안좋아지고, 시장이 침체되는 만큼 비용에 대해서도 꼭 언급하고 넘어갔던거 같습니다. 위너 보겔스 CTO가 작년 라스베이거스 서밋에서 비용과 관련된 내용에 대해서 발표를 했는데 여러분들도 꼭 읽어보셨으면 좋겠습니다. 모든 기술 도입에 있어서는 비용과 성능사이에서 고민을 해야합니다. 비용을 줄인다는 말은 성능에도 영향이 있으니까요. 하지만, 삼성의 재해복구 전략 강연은 들었을 때 느꼈던 거는, 글로벌 서비스를 재해복구 시스템을 구축한다는게 쉽지않았을 텐데, 대게 고민과 생각을 많이한점이 보였고, 비싼거 다 썼다 ㅋㅋ 라고 느꼈습니다.
우아한 형제들 : 데이터 처리도 컨테이너로, 데이터 플렛폼의 혁신

데이터 처리의 어려움
- 인프라 구성
- 다양한 데이터 포멧
- 다양한 프레임워크
- 데이터가 방대해짐
- 비용
컨테이너와 데이터 처리의 결합
컨테이너 기반 이미지 패키징 빠르고 유연한 컴퓨팅 자원 확보 데이터 프로세싱Amazon EMR on EKS : 핵심
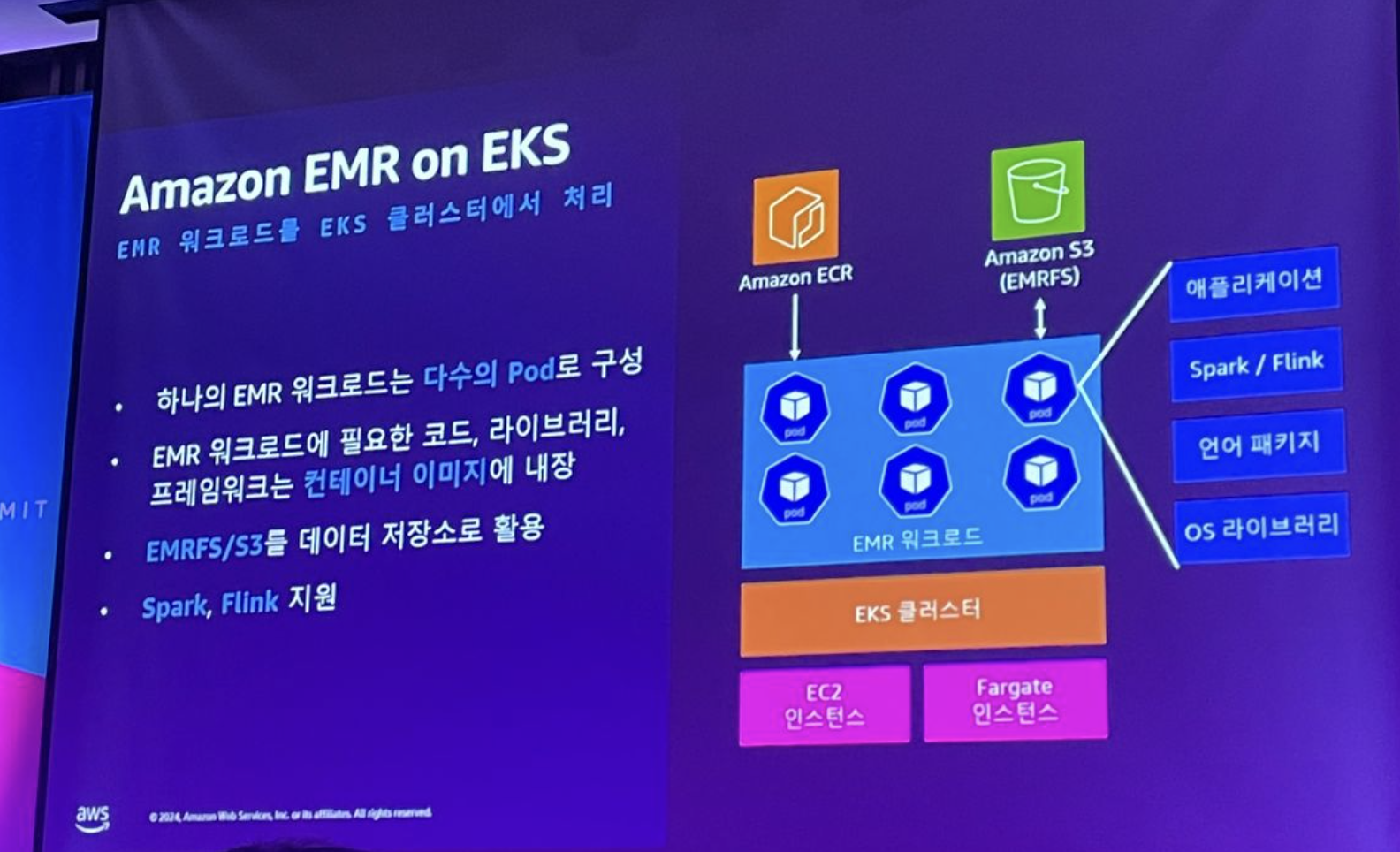
Amazon EMR on EKS란 무엇인가요? - Amazon EMR
- 빠르고 유연한 컴퓨팅 자원 활용
- 카펜터를 활용, On-demand,spot, Graviton 사용
- 워크로드 통합 하나의 EKS 클러스터에서 다양한 EMR 워크로드 처리 가능
Data on EKS
EKS와 AWS 관리형 서비스의 조합으로 데이터 플랫폼 구축
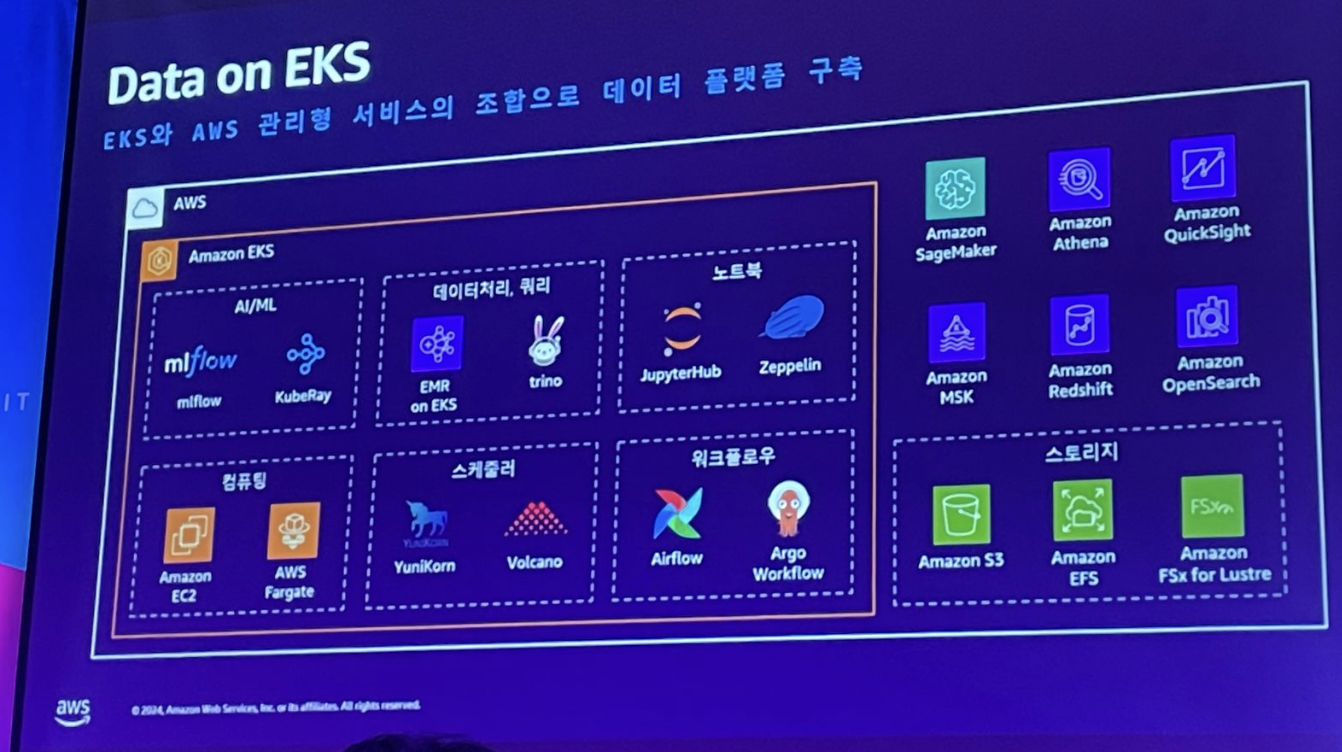
배달의 민족에서는 어떻게 데이터를 활용하는가 ?
우아한 형제들 한동훈 기술이사
- 추천 서비스
- 배달 예상 시간
- 고객 안내 시간
- 뚝딱이(GenAI)
데이터양 및 식사시간 트래픽 패턴
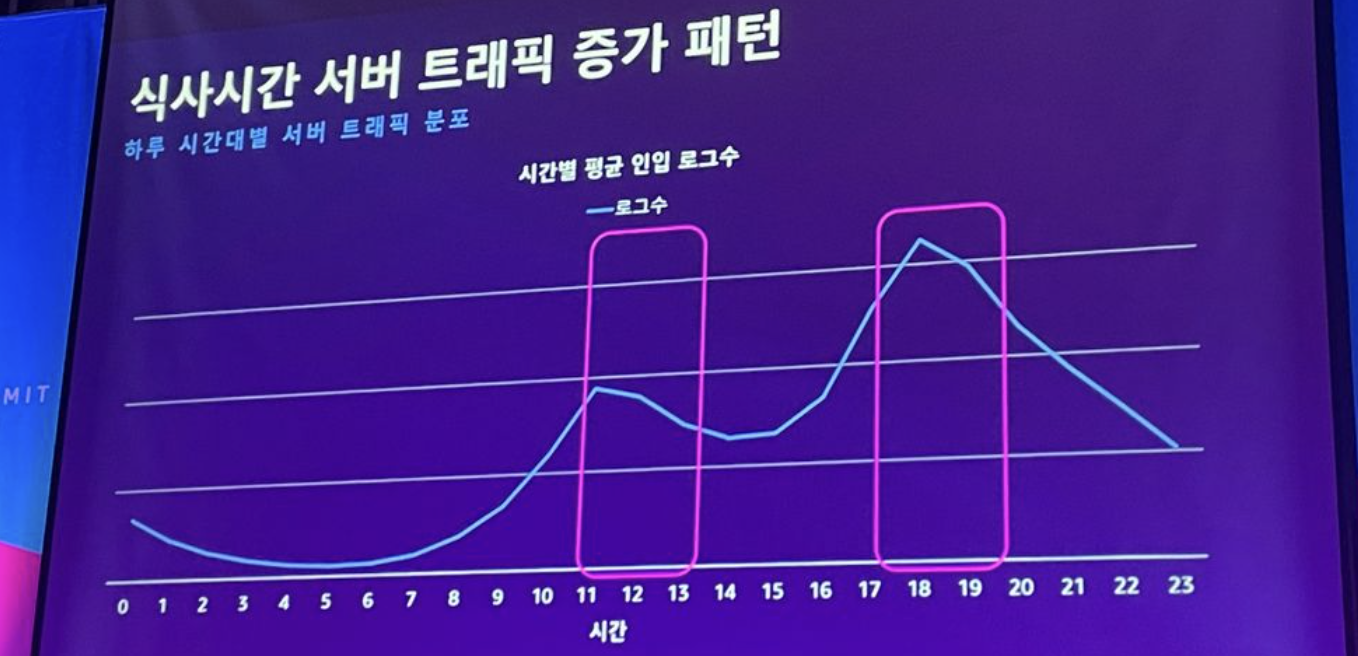
EC2 기반 플랫폼의 한계
- 비용 증가 : EMR 고정 비용, 신규 EC2 타입 미적용, 오버 프로비저닝
- 낮은 민첩성 : 불규칙한 대량 트래픽, 개발 운영 환경 대응, 자원경합(JVM에서 힙 말고 다른거도 사용한다 언급)
- 어려운 유지 보수 : 태스크별 의존성 주입, Airflow 클러스터
컨테이너 환경으로 재탄생
- 기존 데이터 플랫폼 한계점 봉착
- Airflow 이관
- 데이터 처리 시스템 이관
- 데이터 분석도구, 서빙 API dlrhk
데이터 플랫폼 on EKS

EKS 단일 플랫폼에 무수한 서비스들을 사용한
EMR on EKS 효과
이건 뻔한듯
Apache Yunikorn 적용
- 커스텀 스케줄러 적용
- CNI 파드발로 붙기 때문에 뭐 하나에 IP가 열개씩 붙어버리니까 서브넷이 엄청나게 소모된다. 그래서 단순히 서브넷 자체를 크게 만든다고 해결이 되는게 아니다.
- → 유니콘 적용
유니콘을 통해서 극복하려 했던 점
- 데이터 로컬리티 최적화 부재
- 빈 노드 활용 문제
- 애플리케이션 자원 경합
유니콘 고급 스케줄링 적용
job 하나에 꽊꽊 채워서 테스크 할당
- Gand 스캐줄링
- Bin Packing
Airflow 기반 셀프 서비스
- Airflow란 ? Airflow는 복잡한 작업을 자동으로 실행하고 관리할 수 있도록 도와주는 도구예요. 예를 들어, 데이터를 수집하고, 처리하고, 저장하는 여러 단계가 있다고 가정해볼게요. 이 모든 단계를 사람이 하나씩 수동으로 하기에는 시간이 많이 걸리고, 실수할 가능성도 높아요. 이때 Airflow를 사용하면, 각 단계를 자동화하고 체계적으로 관리할 수 있어요.
주요 개념들
-
DAG (Directed Acyclic Graph): 작업들의 순서를 나타내는 일종의 지도 같은 거예요. 각 작업을 노드로, 작업 간의 의존 관계를 엣지로 표현해요. 이 그래프는 순환하지 않아서 한 번 실행한 작업이 다시 실행되지 않도록 보장해요.
-
Task (작업): 각 단계나 작업을 의미해요. 데이터 수집, 데이터 처리, 데이터 저장 등이 각각 하나의 Task가 될 수 있어요.
-
Operator (연산자): Task를 정의하는 데 사용되는 도구예요. 예를 들어, 데이터를 가져오는 작업을 위한 BashOperator, Python 코드를 실행하는 PythonOperator 등이 있어요.
-
Scheduler (스케줄러): 정해진 시간이나 조건에 맞춰 작업을 실행하는 역할을 해요. 예를 들어, 매일 오전 9시에 데이터 수집 작업을 실행하도록 설정할 수 있어요.
-
Executor (실행자): 실제로 작업을 실행하는 역할을 해요. 로컬에서 실행할 수도 있고, 여러 대의 서버에서 병렬로 실행할 수도 있어요.
예시
다음은 간단한 예시예요. 하루에 한 번 특정 웹사이트에서 데이터를 가져와서 이를 처리하고 데이터베이스에 저장하는 작업을 Airflow로 자동화한다고 가정해볼게요.
-
DAG 정의: 하루에 한 번 실행될 작업의 순서를 정의해요.
-
Task 정의:
fetch_data: 웹사이트에서 데이터를 가져오는 작업process_data: 가져온 데이터를 처리하는 작업store_data: 처리된 데이터를 데이터베이스에 저장하는 작업
-
Operator 사용: 각 Task를 정의할 때 적절한 Operator를 사용해요. 예를 들어,
fetch_data는 PythonOperator를 사용해서 Python 코드로 웹사이트에서 데이터를 가져오도록 할 수 있어요.코드 예시
python코드 복사 from airflow import DAG from airflow.operators.python_operator import PythonOperator from datetime import datetime, timedelta def fetch_data(): # 데이터를 가져오는 코드 pass def process_data(): # 데이터를 처리하는 코드 pass def store_data(): # 데이터를 저장하는 코드 pass default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2023, 1, 1), 'retries': 1, 'retry_delay': timedelta(minutes=5), } dag = DAG( 'example_dag', default_args=default_args, description='An example DAG', schedule_interval=timedelta(days=1), ) t1 = PythonOperator( task_id='fetch_data', python_callable=fetch_data, dag=dag, ) t2 = PythonOperator( task_id='process_data', python_callable=process_data, dag=dag, ) t3 = PythonOperator( task_id='store_data', python_callable=store_data, dag=dag, ) t1 >> t2 >> t3 # 작업 순서 정의이렇게 설정해두면 Airflow가 매일 정해진 시간에
fetch_data를 실행하고, 그 다음에process_data, 마지막으로store_data를 실행해요. 이를 통해 작업이 자동으로 관리되고, 실수를 줄일 수 있어요.
-
EMR 컨테이너 이미지 관리
CI/CD를 활용한 지속적인 관리
미래 전략
- Remote Shuffle Service
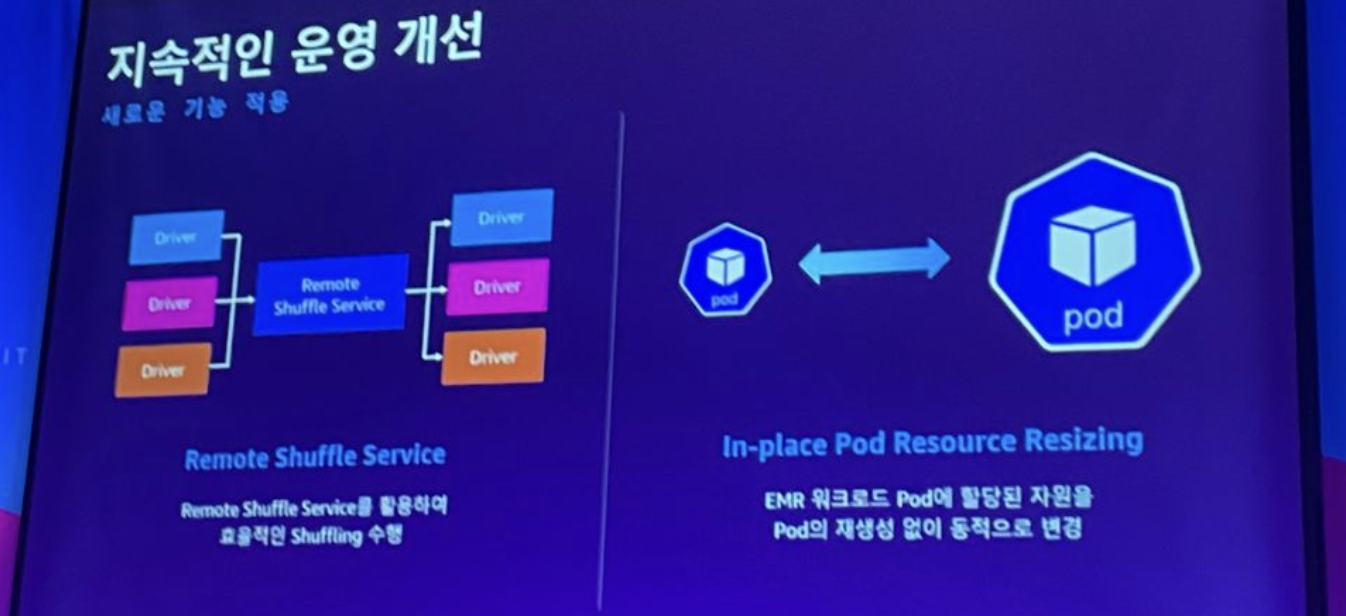
- 권한/인증 개선
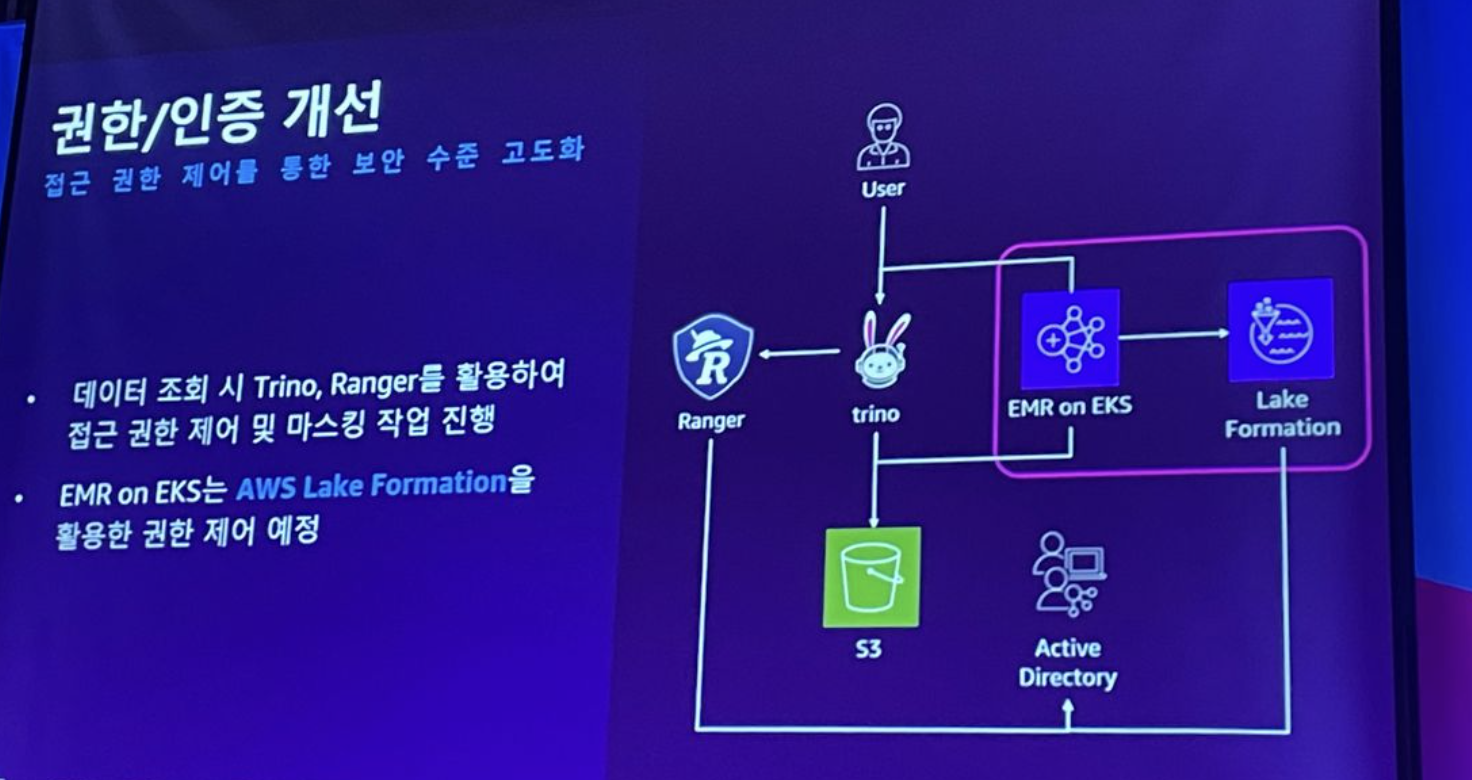
- IDC 자원의 활용
- 하이브리드 클라우드
- 네트워크보다 CPU 성능이 중요하고 더 GPU 성능도 중요하다
마무리 정리
📍 이번엔 2회차 서밋이어서 익숙해서 그런지 필요한 강연보고, 부스보고 하는게 익숙해져서 시간이 좀 남아 돌았다. 후 하루만 갔지만 대부분 부스를 다 돌았고, 보고 싶은 강연도 봤고, 체험도 많이 했다. 그리고 또 재밋었던건 이제 AWS 직원분들이랑 안면이 있어서 인사하면 알아봐주시고, SA 멘토님도 직원 전용 카페가서 커피도 얻어먹었다 ㅎㅎ또 재밋었던건, 이제 자격증 라운지가 생겼다는 건데, 제일 쉬운자격증 어려운 자격증 아무거나 있어도 들어가서 음료랑 간단한 티셔츠 뽑기 체험을 할 수 있었는데, 난 DOP 자격증이라 혼자 어깨가 올라갔다 허허 다음엔 한개 더 들고 오겠서
