df.groupby('host_name').size()
df.host_name.value_counts().sort_index()
두가지 방법이 있다.
groupby size 는 null 값도 세고
value counts 는 null 값 제외
host_name의 빈도수를 구하고 빈도수로 정렬하여 상위 5개를 출력하라
-
df.host_name.value_counts().to_frame().head()
-
Ans = df.groupby('host_name').size().\
to_frame().rename(columns={0:'counts'}).\
sort_values('counts',ascending=False)
Ans.head(5)
'neighbourhood_group','neighbourhood'로 그룹정렬하고 'neighbourhood_group'그룹에서 최대값들을 출력하라
Ans= df.groupby(['neighbourhood_group','neighbourhood'], as_index=False).size()\
.groupby(['neighbourhood_group'], as_index=False).max()
'neighbourhood_group'그룹핑하여 price열의 최대최소평균분산 구하라
Ans = df.groupby('neighbourhood_group')['price'].agg(['mean','var','max','min'])
as_index=False 를 하면 시리즈 type 에서 DF type 으로 변경됨
fillna(-999) 빈값이 있으면 괄호값으로 채워넣는다.
unstack() 계층적 인덱싱을 파괴
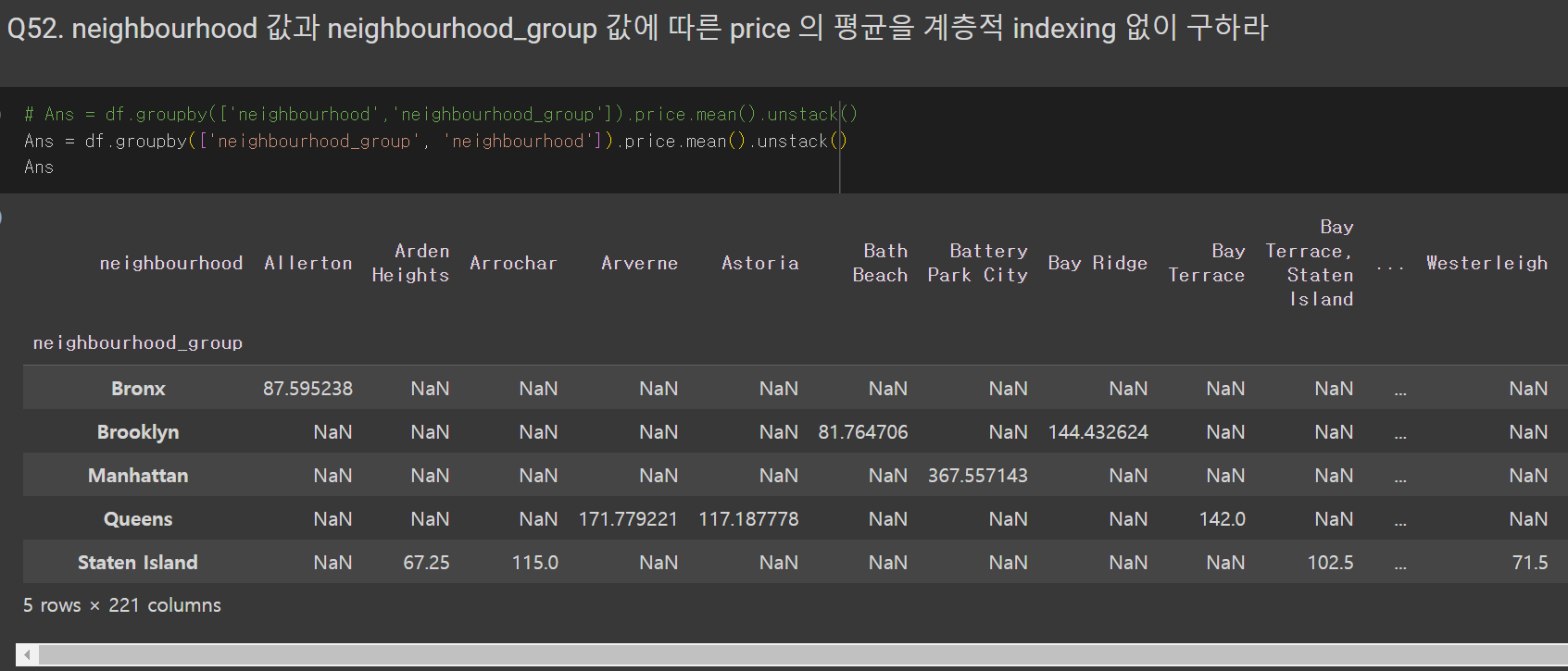
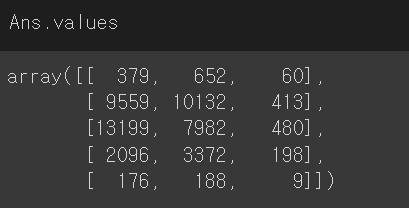
Q55. 데이터중 neighbourhood_group 값에 따른 room_type 컬럼의 숫자를 구하고 neighbourhood_group 값을 기준으로 각 값의 비율을 구하여라
Ans = df[['neighbourhood_group','room_type']].groupby(['neighbourhood_group','room_type']).size().unstack()
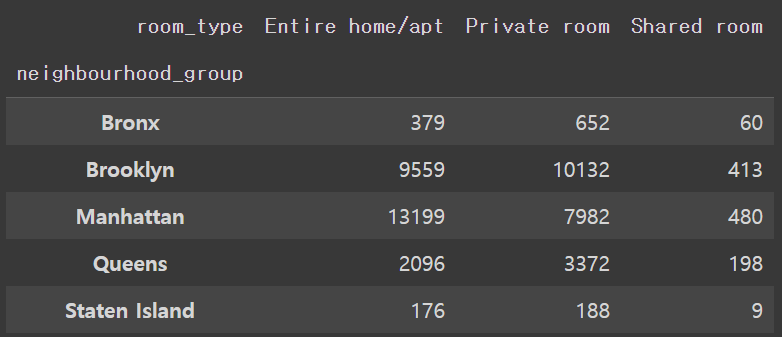
Ans.loc[:,:] = (Ans.values /Ans.sum(axis=1).values.reshape(-1,1))
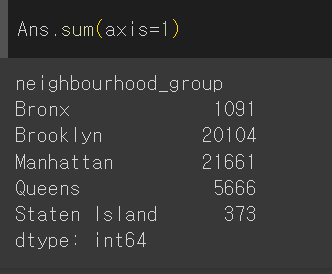
axis=1은 행을 다 더해라, axis=0은 열을 다 더해라
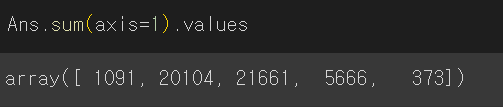
values는 array 형태로 변경

행렬 연산을 위해 1차원 형태의 행렬로 만듬 reshape(-1,1) 기억하자
loc[:,:] = 전체 df의 값에 뒤의 식을 적용할 때 사용