Elastic Search 란?
엘라스틱 서치는 분산형 오픈 소스 검색 엔진으로, Apach Lucene를 기반으로 개발되었다.
주로 로그 분석, 검색 엔진, 데이터 분석 등에 활용되며, 빠르고 확장성 있는 검색 기능을 제공
엘라스틱 서치는 텍스트 검색뿐만 아니라 구조화된 데이터와 비정형 데이터의 저장, 검색, 분석에도 탁훨한 성능을 발휘
프로젝트를 진행하다 보면 서버 성능, DB 설계의 문제나 혹은 DB 최적화가 되어있지 않아 서비스가 느려지는 형상을 경험하게 된다.
그 결과 관계형 데이터베이스에 최적화를 위해 인덱싱을 하게 되고 어떻게 인덱싱을 하냐에 따라 퍼포먼스가 달라지게 된다.
엘라스틱 서치 역시 데이터에 다양한 규칙으로 최적화된 인덱싱을 처리할 수 있어 검색에 빠른 성능을 보인다.
또한, 관계형 데이터베이스와 엘라스틱 서치의 데이터 저장되는 구조 자체가 다르다.
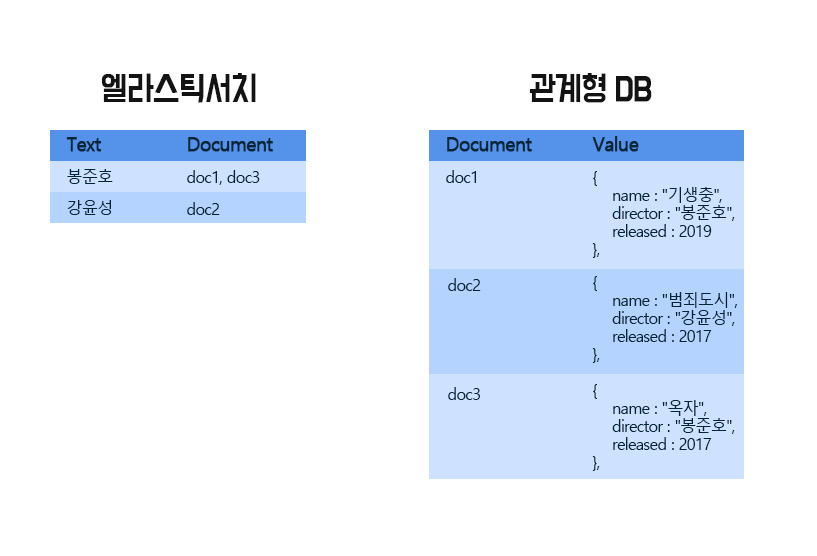
관계형 데이터베이스는 Document 중심이면 Elastic Search는 텍스트 중심이다.
RDBMS는 사용자가 봉준호를 검색하는 순간 doc1, doc3을 하나하나 확인하여 봉준호를 찾고, Elastic Search는 검색하는 순간 데이터를 찾을 수 있다.
RDBMS는 관계형 테이블을 조합하여 볼 수 있으며, 데이터의 ACID 원칙에 의해 관리되는 목적
Elastic Search는 데이터를 다른 table과 조합할 수 없으며, 데이터 트랜젝션을 지원하지 않는다. 엘라스틱 서치만으로 서비스를 개발하기에는 무리가 있다.
가장 좋은 방법은 관계형 DB를 베이스로 하고 검색에 필요한 부분만 엘라스틱 서치로 진행하는 것이 보통이다.
특징
1. 분산형 구조
- 클러스터로 구성되며, 데이터를 여러 노드에 분산하여 저장
- 분산 환경에서 데이터를 처리하기 때문에 대규모 데이터도 빠르고 안정적으로 처리
2. 실시간 검색
- 데이터를 거의 실시간으로 색인할 수 있어, 최신 데이터에 대한 즉각적인 검색 결과 제공
3. RESTful API 기반
- HTTP 기반으로 동작하며, JSON 형식으로 데이터를 전송하고 조회할 수 있는 RESTful API를 제공
- 사용하기 쉽고, 다양한 언어에서 통합하기 용이
4. Schemaless 모델
- 스키마리스 데이터 모델을 사용하여, 데이터를 저장할 때 미리 스키마를 정의하지 않아도 됨
- 필요에 따라 매핑을 설정하여 데이터 구조를 정의할 수도 있음
5. 풀텍스트 검색 (Full-text Search)
- Apache Lucene 기반으로 텍스트 분석, 색인, 검색이 매우 뛰어남
- 특히 자연어 처리와 같은 복잡한 검색 기능을 쉽게 구현 가능
6. 분석
- 데이터 검색 외에도 집계를 통해 데이터 분석 기능 제공
7. 확장성
- 수평 확장 가능
- 데이터가 많아지면 클러스터에 새로운 노드를 추가하여 성능을 유지
- 대규모 데이터 처리에 매우 유용
장단점
장점
- 빠른 검색 성능 : 대규모 데이터에서도 매우 빠르게 텍스트 검색 및 데이터 분석 처리
- 확장성 : 노드를 추가하여 성능 향상, 데이터 분산 처리로 대용량 데이터 처리 가능
- RESTful API : RESTful API를 통해 다양한 프로그래밍 언어와 쉽게 통합
- 강력한 집계 기능 : 데이터 집계 및 분석 기능이 뛰어남
단점
- 복잡한 설정 : 기본적인 사용은 간단하나, 대규모 클러스터에서의 운영은 복잡할 수 있으며, 성능 최적화나 장애 대응 등을 고려해야 함
- 메모리 사용량 : 데이터 양이 많아지면 메모리 사용량이 증가할 수 있어, 대용량 시스템에서는 메모리 관리에 주의해야 함
