concat
Concatenate 데이터를 더한다, 붙인다 라는 의미로 이해하면 좋음
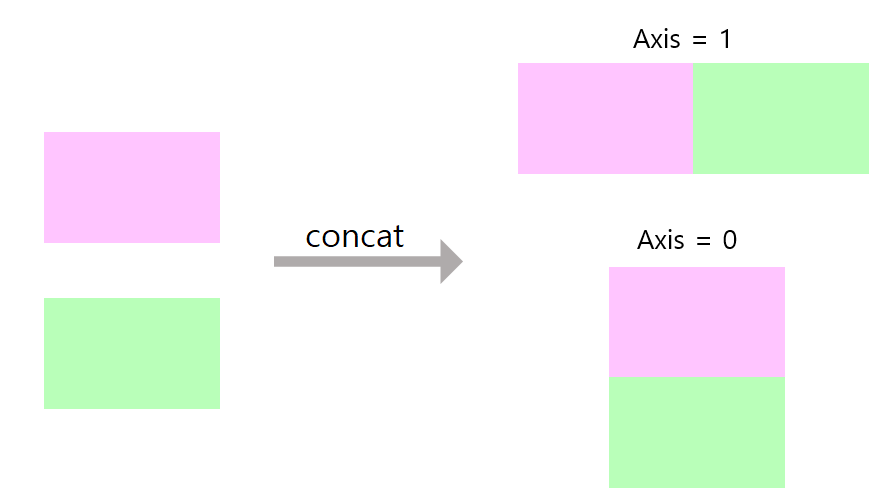
concat은 공통된 부분이 있어도 row기준이든, column기준이든 줄줄이 추가된 새로운 table을 생성함
merge
데이터를 합치는 건 같지만 concat과 merge의 가장 큰 차이점은?
"공통된 부분을 기반"으로 합치기
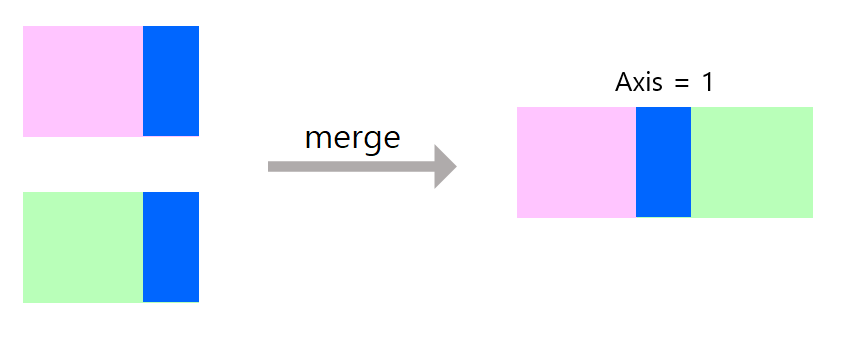
merge는 공통된 부분을 합쳐서 새로운 table을 생성함
concat은 중복된 부분이 존재할 수도 있음
물론 concat으로 데이터 셋을 합친 후 조작을 통해 전처리를 할 수도 있지만, 그런 수고스러움을 덜어주는 merge함수를 이용하는 것이 더 효과적
tidy
하나의 행에는 하나의 데이터만 존재
pandas의 .melt() 함수를 이용해서 tidy형태로 만들 수 있음
import pandas as pd
import numpy as np
table = pd.DataFrame(
[[5, 2],
[16, 11],
[3, 1]],
index=['사과', '딸기', '수박'],
columns=['A', 'B'])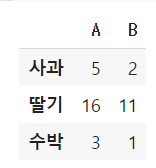
### 행의 인덱스를 선택하고, 이를 행으로 새로 추가
tidy = table.reset_index() # rownames를 새로 설정 
#누가(id), 어떤 feature 값을 가지는지(value) Column을 지정해주면 됨
tidy.melt(id_vars = 'index', value_vars= ['A', 'B'])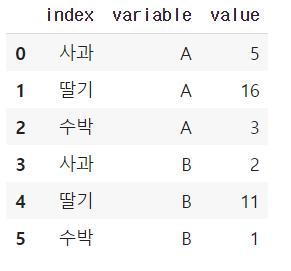
wide
tidy의 반대 개념
.pivot_table() 함수로 tidy 형태를 wide 형태로 만들 수 있음
# 열의 이름을 수정
tidy1 = tidy.rename(
columns = {
'index': 'row',
'variable': 'column',
'value': 'value'
}
)파라미터
index: unique identifier
columns: "wide" 데이터에서 column별로 다르게 하고자 하는 값.
values: 결과값이 들어가는 곳 (wide 데이터프레임의 내용에 들어갈 값)
wide = tidy1.pivot_table(index = 'row', columns = 'column', values = 'value')

찐문과생의 빅데이터 생존기🐣 열심히 할래용 (ง •_•)ง