
Abstract
-
Language 모델의 경우 복잡한 언어 문제를 잘 해결할 수 있다. 하지만 비교적 간단한 작업들(단순 계산, QA system, 검색 앤진, 번역)에서 더 작은 사이즈의 특성화 모델에 비하여 성능이 떨어지는 모습을 보여준다.
-
이에 논문의 저자들은 LM 스스로 외부 API를 사용하여 self-supervised 방식으로 학습이 가능함을 보여준다. 또한 이를 Toolformer 라 명명한다.
-
모델이 스스로 아래의 사항들을 결정할 수 있다.
- 어떠한 API를 사용할지
- API를 언제 사용할지
- API 어떤 변수를 넣을것인지
- future token prediction(대답을 생성)하는 과정에서 API의 결과를 가장 잘 반영하는 방법
-
모델이 필요하는 것은 오직 각 API에 대한 설명과 few-shot example 정도이다.
Introduction
Language Model의 Limitations
- 최신 정보를 반영하지 못 한다.
- 할루시네이션
- Low Resource Data의 경우 성능 저하
- 정밀 계산
- 수행하는 과정에서 시간 반영 불가
Limitations 해결 방안
위 문제들을 해결하기 위해서 external tool 을 사용할 수 있다. EX ) 계산기, 검색 엔진
간단하게 생각해보면 GPT4에 코드를 요구하면 코드 블록을 생성하는 것을 확인 할 수 있는데 이때 코드에 오류가 있는지 직접 디버깅해서 실행해보는 모습을 확인할 수 있었다.
하지만 이러한 방법 또한 human annotation이 대량으로 필요하다는 단점이 존재한다. 이를 해결한 것이 Toolformer 라고 저자는 소개한다.
추가적으로 2가지 관점을 언급한다.
- self-supervised way : human resource의 관점도 중요하지만 useful 한 데이터가 인간과 모델의 입장에서 다를 수 있다는 점을 언급한다.
- generality : 특성화된 방법을 사용함에 있어서 LM이 가지고 있던 general한 언어의 이해력을 저하시키면 안된다.
위 두가지 목표를 해결하기 위해서 저자는 in-context learning 기법을 통하여 from scratch로 전체 데이터 셋을 생성한다. 이를 통해 LM이 스스로 어떠한 API를 사용할지를 결정할 수 있다.
또한 데이터셋의 종류와 무관하게 적용가능한 방법이기에 Pretrianing에서 사용한 데이터를 그대로 사용 가능하다는 점에서 모델의 generality를 잃지 않고 학습이 가능함을 어필한다.
Approach
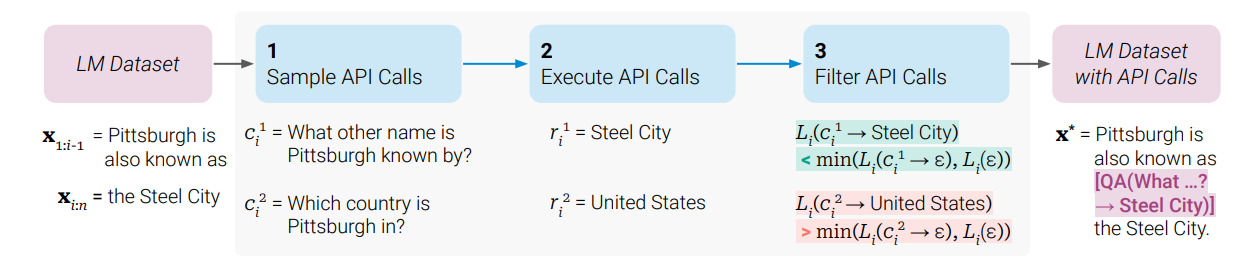
실제 수식을 기반으로 하는 방법론이 아니기 때문에 예시를 들어서 설명하고자 한다.
서울은 대한민국의 수도이며 인구가 가장 많은 도시이다.
다음과 같은 문장이 있다고 하자. 위 문장을 기반으로 간단한 QA API의 입력과 결과를 생각해보면 아래와 같은 QA를 만들 수 있다.
대한민국의 수도는 무엇인가요? 서울
대한민국에서 인구가 가장 많은 도시는 무엇인가요? 서울
이렇게 QA시스템이라는 API의 답과 결과를 만들어 간단한 테스크 성능을 올릴 수 있는 데이터를 만드는 것이 목표이다.
Approach 진행과정 요약
단계별로 요약하자면 아래의 순서를 따른다.
- API Call 샘플링
- API Call 실행
- API Call 필터링
본격적인 방법을 설명하기에 앞서서 먼저 수식들을 살펴보자.
i_c : c의 input
a_c : c의 API 이름
c : API_CALL
**논문에서는 < API > 와 < /API >을 새로 만들지 않고 "[", "]"토큰을 사용**
특별한 내용은 없고 API Call을 저렇게 표현한다는 것이다.

모델은 GPT-J를 사용하였다.
모델의 경우 Incontext learning을 통해 학습한 모델을 사용한다.
따라서 위와 같이 API와 fewshot example을 사용하여 Input x에서 API Call에 해당하는 text를 추가할 수 있다. 즉, 스스로 API에 적합한 Input을 만드는 것이다.
대한민국의 수도는 서울이다.
대한민국의 수도는 [QA(대한민국의 수도는?)] 서울이다.
위와 같이 i_c가 포함된 x* 를 만들었다.
API Call 샘플링
다음과 같이 x* 를 만들었다면 이제 어떠한 것들을 실제 데이터로 사용할지 결정하는 과정이다.
** 수식으로 설명하는게 오히려 번거로우니 말로 설명하겠습니다.**
"대한민국의 수도는" 다음 토큰으로 "["가 나올 확률을 계싼하고 결과가 threshold값보다 크다면 사용
당연히 적절한 threshold값을 찾는 과정은 cost가 필요합니다.
API Call 실행
API Call을 실행합니다.
대한민국의 수도는 [QA(대한민국의 수도는?)] 서울이다.
대한민국의 수도는 [QA(대한민국의 수도는?) -> 서울] 서울이다.
다음과 같은 형태로 만들어지면 실제 사용할 데이터의 모습을 갖춘 상태가 된다.
API Call 필터링
위와 같이 Loss를 정의하자. 위 Loss를 직관적으로 해석하면 z와 1 ~ j까지의 입력이 주어질때 모델이 x_j라고 예측하지 않을지를 수치로 표현한 것이다.
여기서 는 선형적으로 작아지는 값을 사용하여 실제 정답 토큰에 해당하는 값들에 weight를 더 주는 방법이다. (자세한 내용은 논문에서 Experiment Setting 참고)
위와 같이 L를 정의 했다면 Filtering 기준은 아래와 같다.
은 빈 문자열으로 생각할 수 있다.
수식을 직관적인 예로 해석하자면
- 대한민국의 수도는 [QA(대한민국의 수도는?)->서울]
- 대한민국의 수도는 [QA(대한민국의 수도는?)]
- 대한민국의 수도는
1번에 해당하는 내용이 이며 2번과 3번은 에 해당한다.
즉, 1번이 입력으로 주어질때 "서울이다"라는 말을 생성할 확률이 2번과 3번이 입력일때보다 생성할 확률이 일정한 값(비례) 보다 크다면 해당 데이터를 사용한다는 것이다.
Finetuning
이를 통해서 만들어진 데이터를 를 실제 finetuning에서 사용한 모델을 toolformer 라 한다.
Experiment
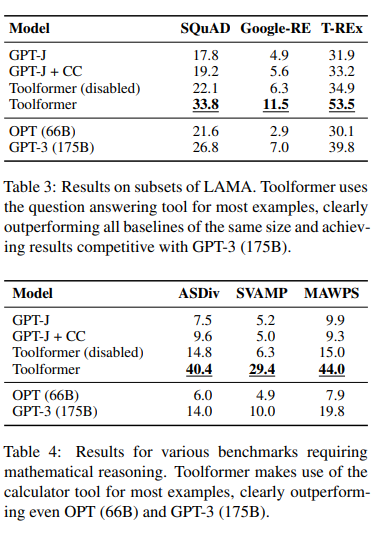
다양한 테스크에서 기존 모델 및 GPT3.5와 비교하여 좋은 성능을 보임.
자세한 내용은 논문 참고
Anlaysis
자세한 내용은 패스
Toolformer(disabled) : API의 결과없이 학습한 모델
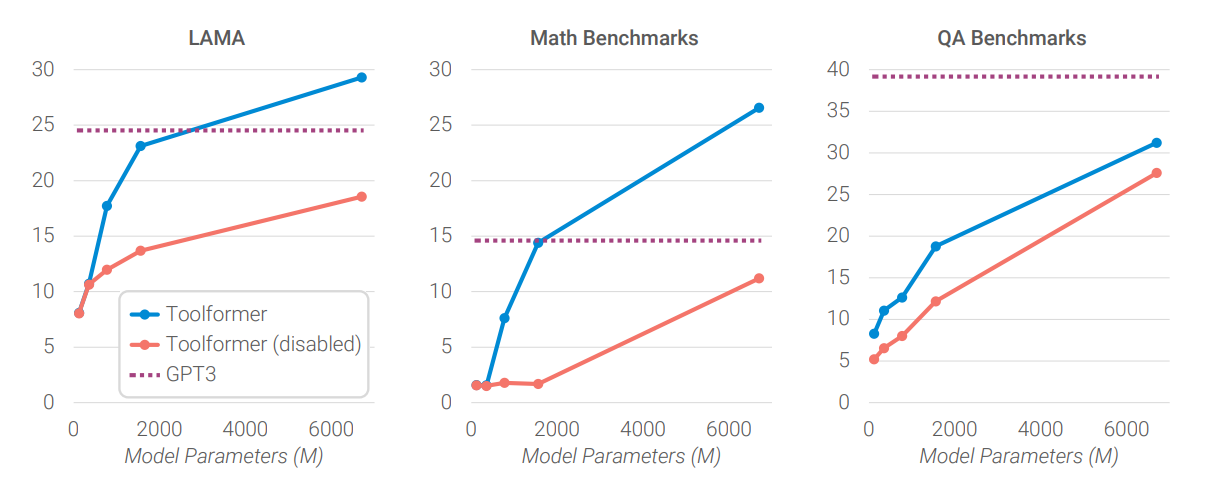
위 그래프를 보면 각 테스크 별로 Toolformer 기법의 효용성을 가늠해볼 수 있다.
- LAMA : 단답형 QA 데이터셋
- 단답형의 경우 API의 결과가 맞을 확률일 높음으로 disabled 모델에 비해 좋은 성능을 보인다. - Math : 단순 계산 데이터셋
- LLM의 수학적 계산능력의 한계를 가지기에 disabled 모델에 비해서 API를 결과를 포함할때 큰 차이로 성능이 올라간다. - QA : 단순 QA
- API의 성능이 떨어지기에 disabled 모델과 큰 차이를 보이지 않는다.
LAMA : 단답형 QA 데이터셋(참고용)
아래의 데이터 처럼 question format, x가 주어질때 Q에 대한 대답 y를 하는 테스크

Limitation
-
Chain구조가 불가능하다 : API의 output을 다른 API의 input을 사용할 수 없다.
-
QA와 같이 다양한 정답이 있을 수 있는 경우 API에 dependency가 생긴다.
-
Sample 데이터에 대해서 inefficient하다 : API에 따라 100만개의 데이터에 대해서 1000개 정도의 API가 나오기도 한다.
여기서부턴 개인적인 생각
-
필요한 threshold값이 2개 존재
-
pretraining에서 사용한 데이터를 활용한다는 점에서 generality를 보존할 수 있다는 주장은 타당하다. 하지만 실험적인 증명이 없음이 아쉽다.
-
또한 다음 방법으로 학습한 모델은 general한 테스크에서는 output에서 < API > ~~ < /API >에 해당하는 토큰만큼 제거해야한다는 Cost가 생긴다.
Small Talk
논문에서 언급한 내용이 기억에 남아서 적는다.
"what humans find useful may be different from what a model finds useful."
"사람이 판단한 유용한 정보와 모델에게 유용한 정보는 다를 수 있다."
AI의 시작점이 모델인 MLP의 시작은 인간의 뇌를 모방하였지만 모델은 발전하면서 인간이 사고하는 방식과는 거리가 멀어졌다. 이를 인식하고 인간이 전달하고자하는 정보를 모델의 입장에서 잘 전달하는 방법을 연구할 필요성이 있다.
Reference
Toolformer: Language models can teach themselves to use tools.
Schick, Timo, et al. (2024)
