로지스틱 회귀
- 표준화 할 때 훈련세트의 통계값으로 테스트 세트를 변환해야한다.
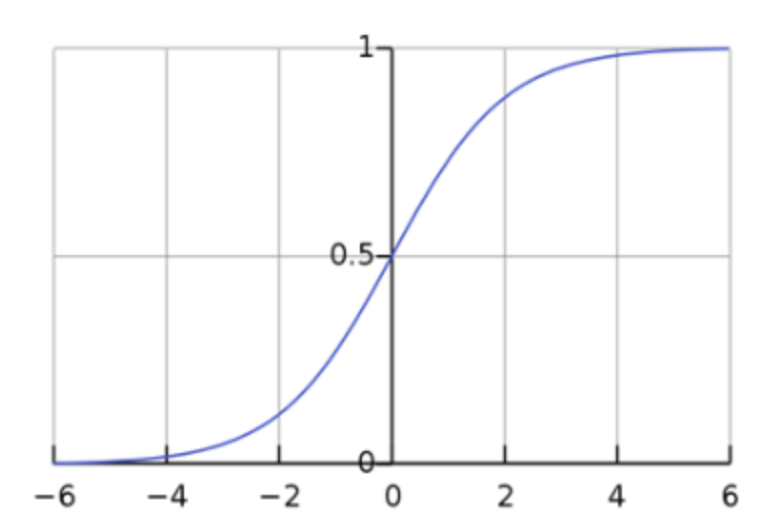
- 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 것으로 선형 방정식의 출력을 0~1 사이의 값으로 하여 이진 분류를 위해 사용한다.
- 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 쓰는 함수는 시그모이드 함수다.
- 다중분류에서는 여러개의 선형방정식 출력값을 0~1 사이로 압축하고 합이 1이 되도록 하는 소프트 맥스 함수 사용하기
- 선형 분류 알고리즘
과대/과소 적합
import numpy as np
import matplotlib.pyplot as plt
sc = SGDClassifier(loss='log_loss', random_state=42)
train_score = []
test_score = []
classes = np.unique(train_target)
for _ in range(0, 300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))
plt.plot(train_score, label='train_score')
plt.plot(test_score, label='test_score')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(loc='lower right')
plt.title('과대/과소 적합확인')
plt.show()
- 에포크 수를 많은 경우 과대적합
- 에포크 수가 적으면 과소적합
트리 알고리즘
1. 결정트리
-
모델 :: 스무고개와 비슷
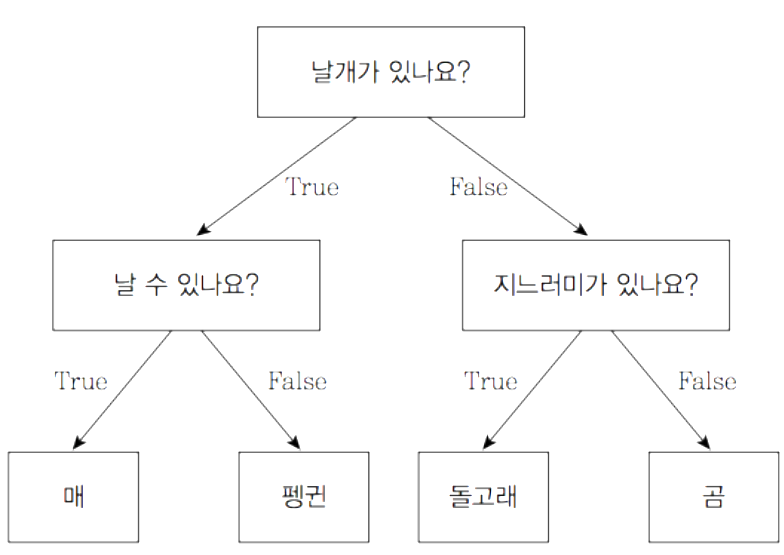
-
출처 : Baek Kyun Shin
지니 불순도
- 노드에서 데이터를 분할할 기준을 정할 때 사용
- O :: 순수한 노드, 0.5 :: 최악의 지니 불순도
- 지니 불순도 = 1 - (음성 클래스 비율 ^2 + 양성 클래스 비율^2)
엔트로피
- 지니 불순도와 동일하게 결정트리의 불순도를 구하는데 사용
- 수식에서 지니는 제곱을 사용하고 엔트로피는 로그를 사용(차이점)
Pruning
- == 가지치기
- 트리의 가지가 계속 많아지면 모델의 정확성이 떨어진다. 즉 일반화가 안된다.
교차 검증과 그리드 서치
- 훈련세트(약 60%), 검증세트 (약 20%), 테스트세트(약 20%)정도로 구분 (구글링)
Cross Validation
- 검증세트를 떼어내서 평가하는 과정을 여러번 반복
- K-Fold Cross Validation
- k-1개의 훈련세트와 1개의 검증세트를 만들고 학습하고 검증. ( 이를 k 번 반복 )
그리드 서치
- 하이펄파라미터 탐색을 자동화 해주는 도구
랜덤 서치
- 그리드 서치하는 시간이 오래걸리면 사용해보기
트리의 앙상블
-
정형 데이터 : 표, 그래프와 같이 정리되어 있는 것
-
반정형 데이터 : csv, JSON, XML
-
비정형 데이터 : .avi, .wav, .JPG
-
n_jobs를 -1로 설정
앙상블 학습
- 더 좋은 예측 결과를 만들기 위해 여러개의 모델을 훈련하는 알고리즘 (머신러닝)
랜덤 포레스트
- 대표적인 결정 트리 기반의 앙상블 학습 방법
엑스트라 트리
- 랜덤 포레스트와 비슷한데 부트스트랩 샘플 사용 X
- 램덤하게 노드를 분할하여 과대적합을 방지
양도 많고 어렵다 ...
