저번시간 끝까지 다루지 못했던 신경망 모델 훈련도 작성해보고, 우리가 하려는 프로젝트에 맞는(kaggle 에 있는) 코드도 작성해보고자 한다.
4가지 정도를 따라해봤는데, 그 중 상위 2가지만 작성해보려 한다.
인공 신경망으로 패션 아이템 분류하기
- 케라스 모델은 훈련하기 전 설정 단계가 존재
- complite() 메서드에서 수행한다.
- 필수로 지정할 것은 손실함수의 종류이다.
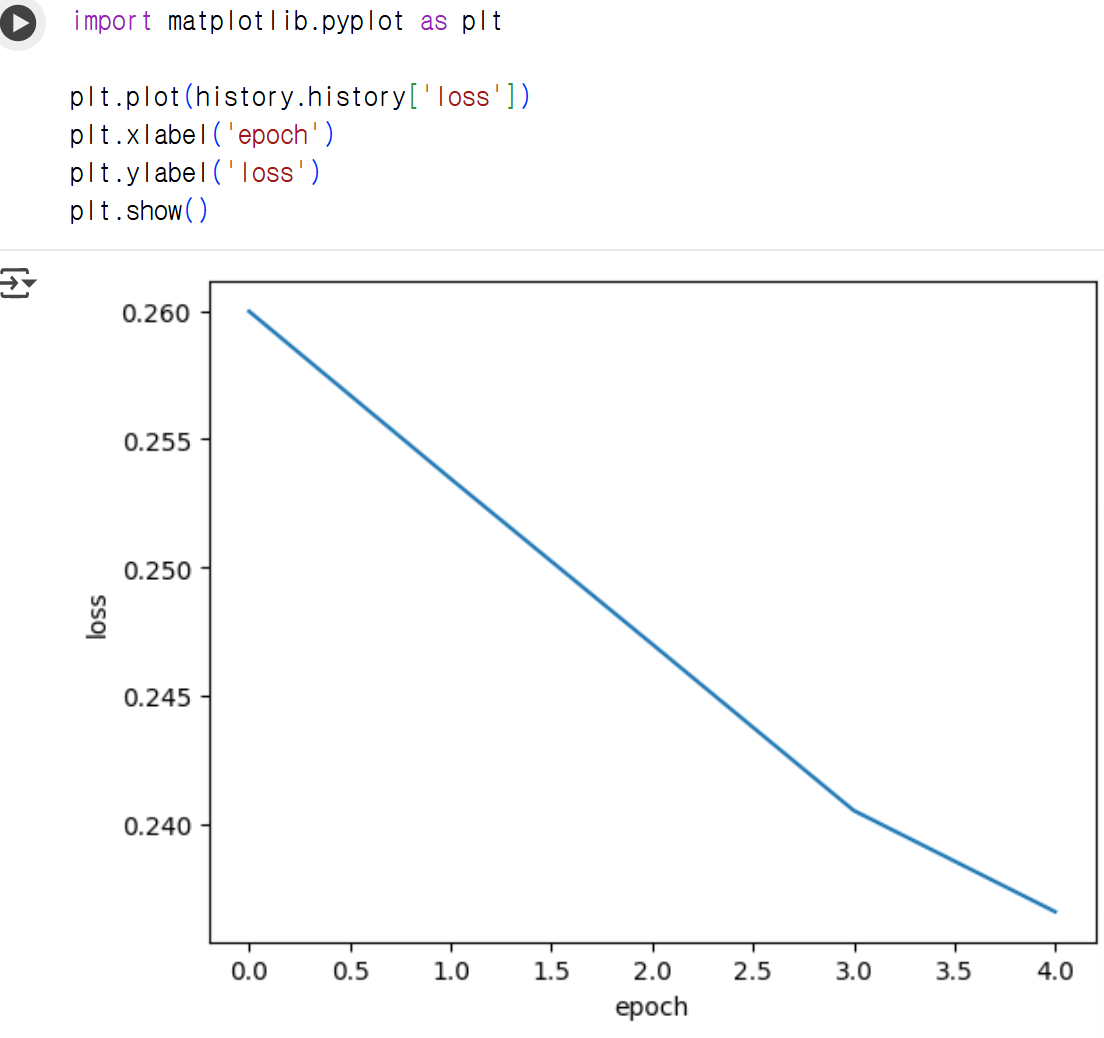
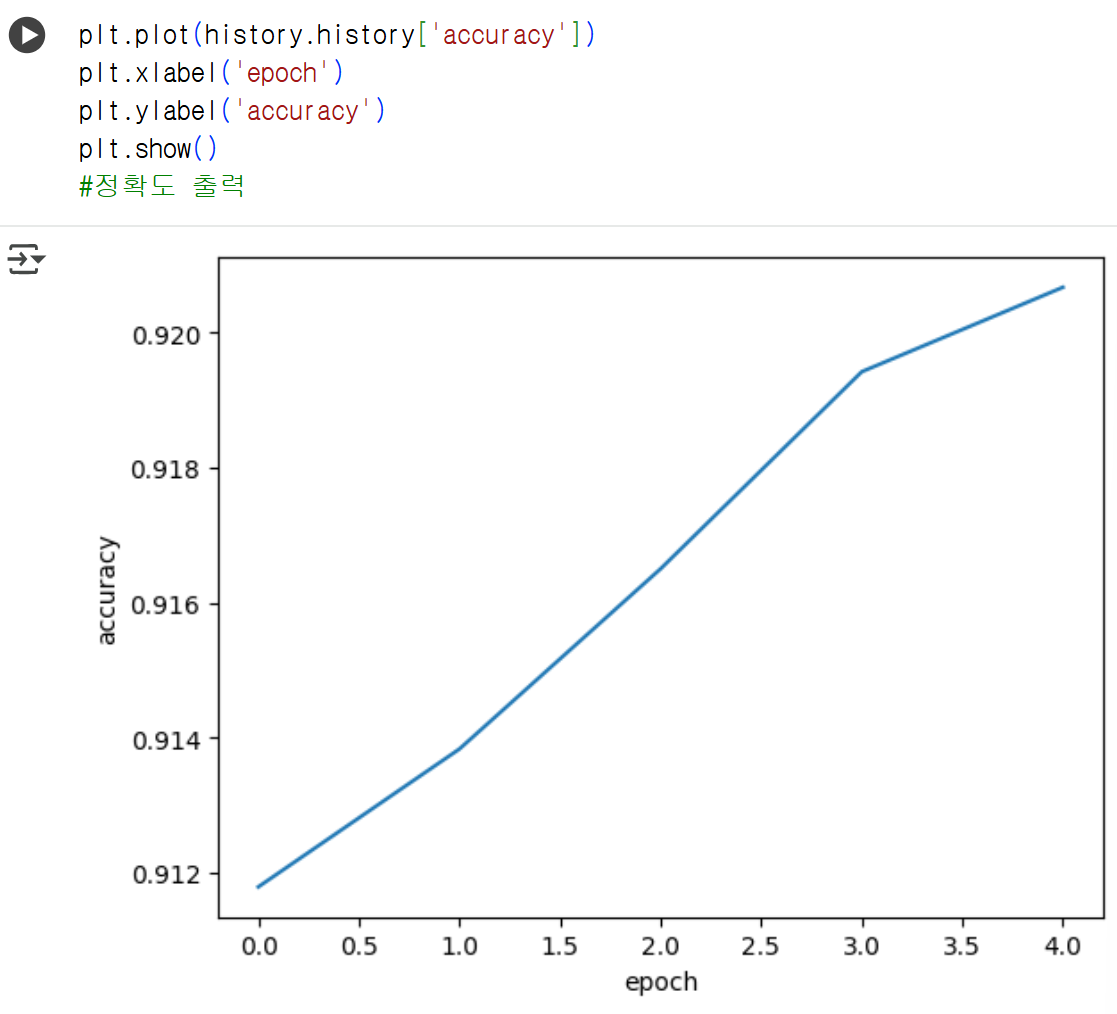
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
kaggle Student Performance(Multiple Linear Regression)
1. kaggle Student Performance
- 데이터 불러오기
- 기본 통계 확인(info(), describe())
import pandas as pd
df = pd.read_csv("farm/kaggle/input/students-performance-in-exams/StudentsPerformance.csv")
df.info(); df.describe()- EDA
- 이상치 확인
- 성별 인종 부모학력 점심 등 점수 분포 시각화
import seaborn as sns, matplotlib.pyplot as plt
sns.countplot(x='gender', data=df)
sns.boxplot(x='test_preparation_course', y='math_score', data=df)
sns.heatmap(df.corr(), annot=True)
- 데이터 전처리
- 범주형변수인코딩
- 새로운 피처 생성
- 데이터셋 분할(train_test_split)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['gender'] = le.fit_transform(df['gender'])
df = pd.get_dummies(df, drop_first=True)
df['average_score'] = df[['math_score','reading_score','writing_score']].mean(axis=1)
- 모델 학습 및 평가
- LinearRegression, LogisticRegression, RandomForestClassfier 등 비교
- 예측 결과 시각화 및 정확도 평가
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.ensemble import RandomForestClassifier
X = df.drop('average_score', axis=1)
y = df['average_score']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
lr = LinearRegression().fit(X_train, y_train)
rf = RandomForestClassifier().fit(X_train, y_train.round()) # 분류형 예시
2. Student Performance ((Multiple Linear Regression)
- 데이터 불러오기/기초 확인
import pandas as pd
df = pd.read_csv("…Student-Performance-Multiple-Linear-Regression.csv")
df.info(); df.describe()
- EDA
- 데이터 전처리 및 특징 엔지니어링
- 학습용 데이터셋 / 테스트용 데이터 셋 나누어짐
- 다변량 선형 회귀
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)- 여러 독립변수를 사용해서 종속변수 예측
- 모델의 유의성 분석이 존재.
- 모델 평가 및 해석
- 회귀모형이 얼마나 잘 들어맞는지 R² 값, 잔차 분석 등을 통해 평가. 각 독립변수가 얼마나 유의미한지(p-value) 분석: 공부시간, 이전시험점수는 유의
