[개념] 딥러닝 optimizer 알고리즘 정리
딥러닝에 사용하는 대표적인 optimizer 8종을 살펴봅니다.
optimizer: 딥러닝 학습 속도를 높이고 안정적이게 학습되게 도와줌
- optimizer 동작방식 정리
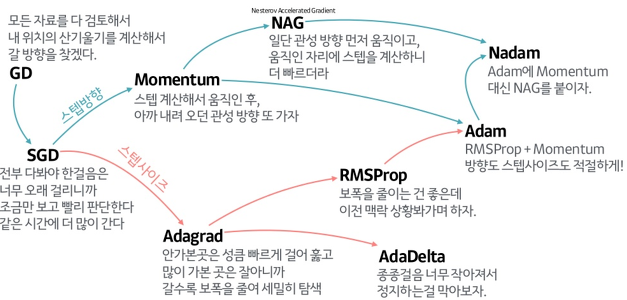
-
SGD(Stochastic Gradient Descent): 전체 데이터 중 batch 데이터셋을 가지고 gradient 평균을 구해서 Gradient Descent 수행
-
Momentum: SGD에 관성이라는 개념을 추가하여 이전 학습 결과도 일부 weight 변화에 영향을 주게함. 관성을 통해 local minium에서 빠져 나올 수 있음.
-
NAG(Nesterov Accelerated Gradient): NAG는 관성만큼 움직인 후 gradient를 계산하여, Mometum이 관성으로인해 수렴이 되지 않는 경우를 막아줌.
-
AdaGrad(Adaptive Gradient): 각 weight들 마다 learning rate를 다르게줌. 학습을 통해 크게 변동이 있었던 weight에 대해서는 learning rate를 감소시키고, 아직 변동이 별로 없었던 weight는 learning rate을 증가시켜서 학습이 되게끔 함.
-
AdaDelta(Adaptive Delta): AdaGrad가 weight 학습률이 0이되는 문제를 의 문제점을 해결하기 위한 고안된 방식. 모든 gradient의 정보를 저장하는 것이 아니고 지난 w개의 gradient 정보만을 저장하고, gradient update에 지수 이동 평균를 적용.
-
RMSProp(Root Mean Square Propatation): AdaGrad는 복잡한 다차원 곡면 function에서는 global minimum 전에 learning rate가 0에 수렴할 수 있어 고안된 방식. gradient를 단순 누적하지 않고 지수 가중 이동 평균을 이용하여 최신 기울기들이 더 크게 반영되도록 함.
-
Adam(Adaptive Momentum): RMSProp과 Momentum을 조합한 방식. 학습률과 방향 2가지 모두 고려.
-
Nadam: Adam에 Momenum 대신 NAG를 조합한 방식.
