CRDT와 OT(1) - figma의 구현
이 포스팅은 2024.11.28에 작성되었습니다.
<수정사항>
1. 11.30 오타 3개를 발견하여 수정(갓창민)
서론
(주절거리는 서론입니다. 시간이 없으신 분들은 스킵해주세용)
가장 최근 진행한 프로젝트에서 실시간으로 협업할 수 있는 Todo List와 유사한 워크플로우 관리 서비스를 구현했다. 어떤 서비스(Trello)를 거의 클론코딩하듯 구현하였는데, 해당 서비스의 기술블로그를 보니 실시간 화면 반영로직을 소켓으로 구현했다는 걸 알게되었다. 그 외에도 가장 자주 사용하는 동시 편집 디자인 툴인 Figma도 소켓을 사용한다는 정보를 얻었고, 우리 서비스도 소켓을 이용하여 실시간 편집 기능을 구현하였다.
하지만 생각보다 소켓통신이 불안정했고, 오프라인모드 구현을 위해 어플리케이션 내장 DB와 서버 DB를 동기화하는 과정에서 불안정한 소켓의 특징을 어떻게든 해결해야했다. 이를 위해 http 통신과 소켓통신을 섞기도 했고, 순서보장을 위한 메시지큐와 ack, 카프카 토픽을 사용했다.
시간이 굉장히 부족했지만 팀원들 덕분에 어떻게든 구현에 성공하였고, 지금 생각해도 그 당시에는 이 구현방법이 최선의 선택이었다. 하지만 이 방법이 정말로 좋은 방법인지는 확신할 수 없었다. 신경 쓰이는 점들은 다음과 같았다.
- 일단 로직 자체가 굉장히 복잡했음
- ack를 받고 다음 변경사항을 주는 부분이 가장 큰 병목이다. 시연 시나리오에서는 잘 동작했지만, 변경사항이 너무 많은 경우에 빠르게 받아올 수 없다는 문제가 있음
- ack관련한 테스트가 너무 힘들 수 있다(나는 테스트방법이 도저히 떠오르지 않았다)
- 사용자별로 지금까지 받은 변경사항에 대한 offset을 서버에서 관리하는 게 좋은 방법인지 궁금했음
- 중간에 서버나 프론트에서 뭔가를 누락해서 제대로 반영되지 않을 때 어떻게 처리해야할 지 명확하지 않았다
우리의 로직 자체를 개선하는 방법도 좋겠지만, 현재 사용되는 동시편집 서비스들이 어떻게 구현하였는지 분석하면서 더 좋은 방법이 있다면 찾아내고 싶었다. 그래서 서비스들을 하나씩 분석해보고 구현방법을 살펴보는 시간을 가져보고자 하였다.
이번 포스팅은 피그마의 소켓기반 동시편집 기술과 관련된 내용이다! 이후에 노션 등의 툴도 살펴보고자 한다.
CRDT와 OT란?
동시편집, 실시간 협업 툴 구현방법을 검색했을 때 이 두 가지 방법이 가장 많이 언급된다. 이 두 가지의 기술을 먼저 정리하고 피그마의 이야기를 알아보도록 하자!
실시간 협업 에디터가 동작하는 과정
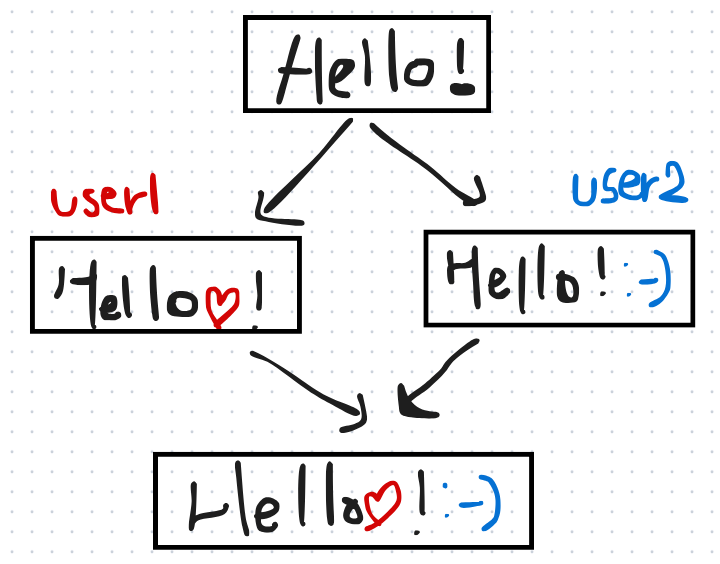
user1이 Hello! 중간에 ❤를 넣고, user2가 Hello! 뒤애 :-) 이모지를 추가하는 상황이다.
실시간 협업 에디터는 이 두 가지 operation을 합쳐서 Hello❤!:-) 가 나오도록 한다.
이렇게 실시간 협업 에디터 구현에 사용되는 알고리즘은 OT와 CRDT가 있다.
OT(Operational Transformation)
Operational Transformation 기술은 1989년부터 2006년까지 사용되던 기술로, Google Docs와 Ms Office에서 사용하였다. 작동 원리는 다음과 같다.
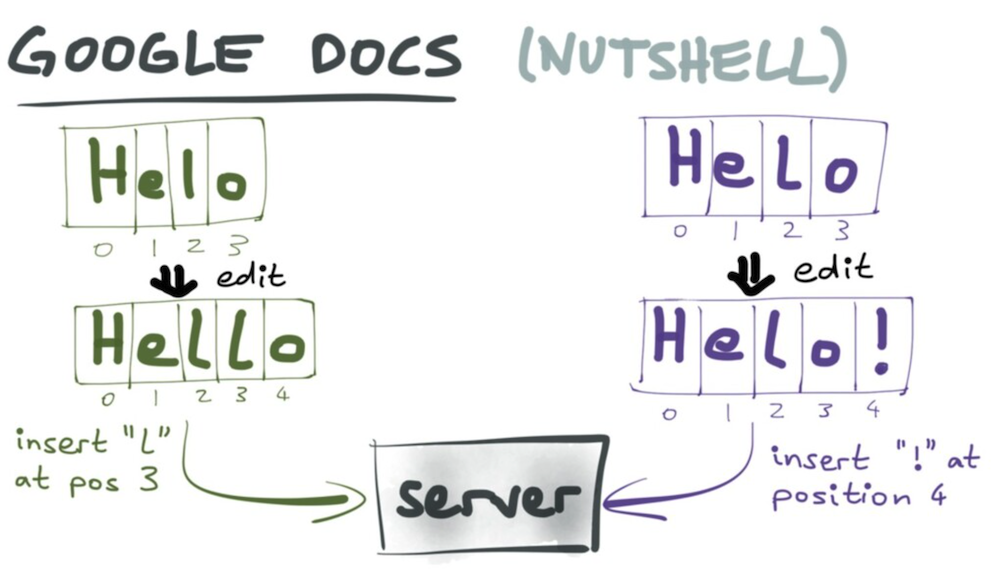
- 첫 번째 operation = 인덱스 3에 l을 삽입
- 두 번째 operation = 인덱스 4에 !를 삽입
=> 서버는 두 operation을 받아 통합
두 operation은 순차적으로 진행된다. 하지만 첫 번째 operation이 수행된 후 두 번째 operation의 인덱스는 원하는 위치가 아니게 될 수 있다. (인덱스 4가 아닌 인덱스 5에 삽입이 되어야 정상적임)
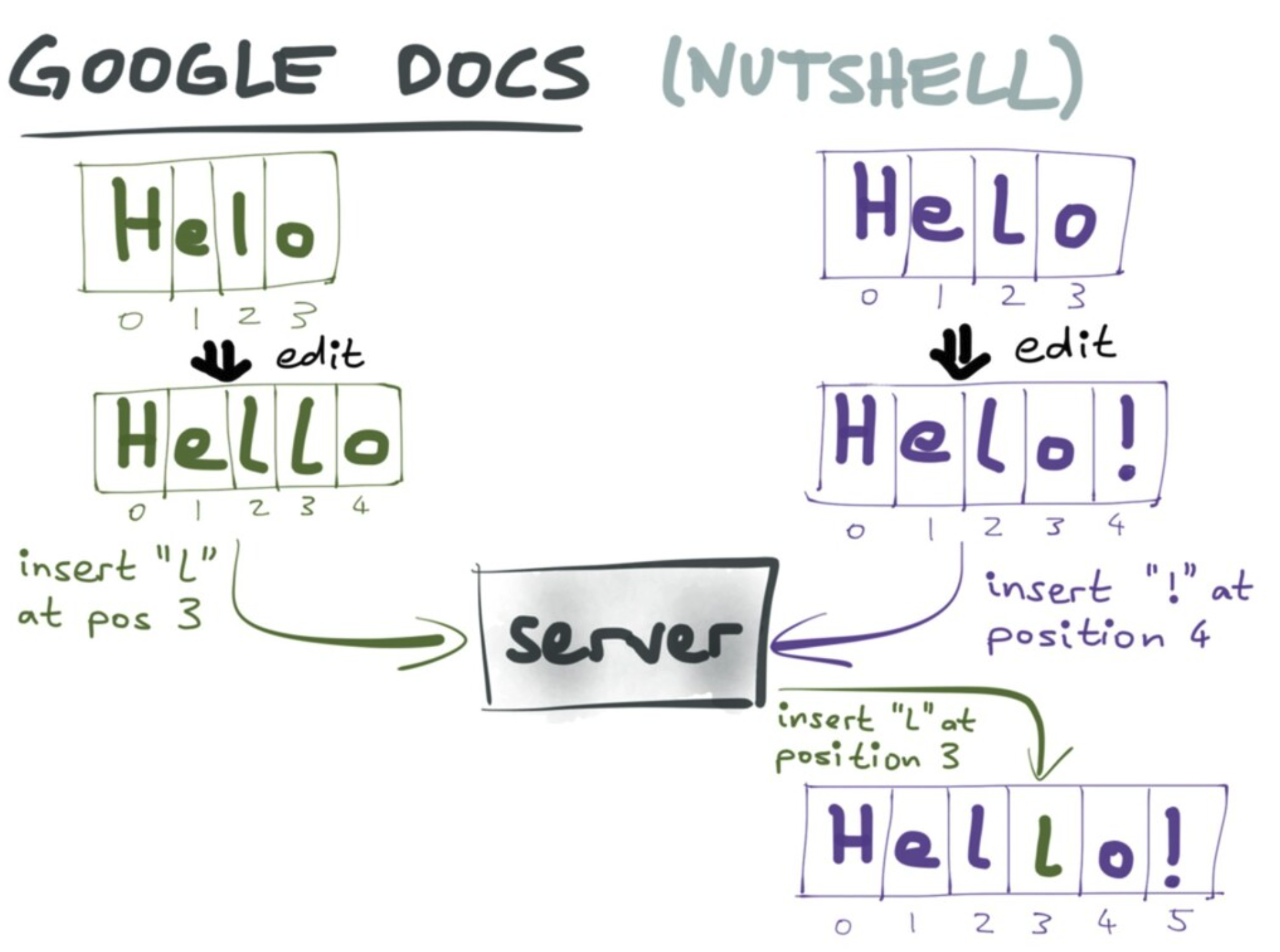
OT는 이와같은 상황을 중앙서버에서 인덱스를 조정해줌으로써 해결한다. 즉, 서버는 이전 동작을 기반으로 다음 동작을 transform 시켜준다. (그래서 operational transformation이다)
OT는 텍스트에서 오프셋을 통해 연산을 정의하는 기술이다. 모든 변경사항을 기록하고, 중앙서버에 전송하면 서버는 이를 순차적으로 실행하고 이전동작을 기반으로 다음 동작을 변환시키는 과정을 거친 후 클라이언트에 값을 반환한다.
OT의 단점
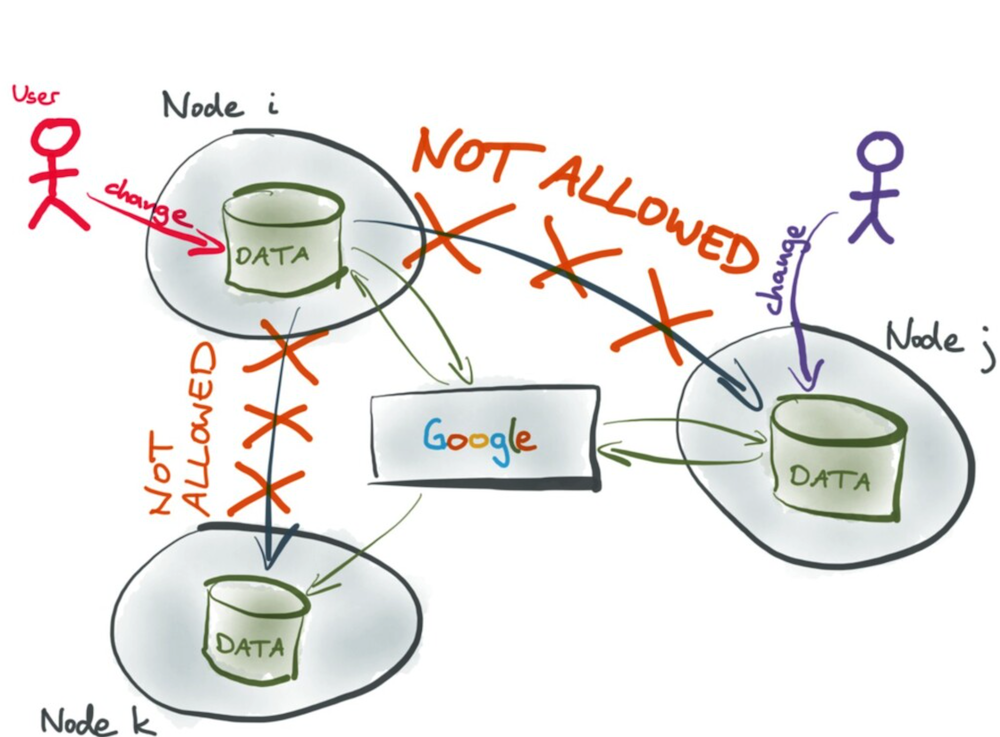
위에서 언급했듯이, OT는 중앙 집중식 서버와 DB가 필수적이다. 이전 변경사항을 기반으로 다음 동작을 변환시켜줘야하기 때문이다.
이로 인해서 서버의 과부하 문제가 발생할 수 있다. 그리고 분산 시스템에서 연산 자체가 순차적으로 실행되기 때문에 속도가 느려질 수 있다. 가장 큰 문제점은 상태와 연산의 결과 조합을 예측하기 매우 어렵다는 것이다. 삽입과 삭제만 처리하는 OT 알고리즘의 경우도 매우 복잡하고 오류가 발생하기 쉽다.
CRDT의 경우, 중앙 집중식 서버가 필요하지 않고, 어떤 네트워크나 통신이든 제한이 없다. 그래서 협업 어플리케이션 뿐만 아니라 Redis Enterprise 같이 데이터 센터가 멀리 떨어져있는 DB system에도 CRDT가 사용된다.
CRDT(Conflict-Free-Replicated Data Types)
Conflict-Free-Replicated Data Types 는 2006년 이후부터 현재까지 사용되는 다양한 데이터 구조의 모음을 뜻한다. Figma나 Redis, Yorkie에서 사용한다.
CRDT의 뜻은 "어떤 변경사항을 받으면, 순서와 상관없이 변경사항만 같다면 같은 상태"라는 뜻이다. 즉, 순서 상관없이 operation만 같으면 어긋나더라도 같은 상태로 인정된다. 이게 어떻게 가능한지는 CRDT의 동작방식을 보면 쉽게 이해할 수 있다.
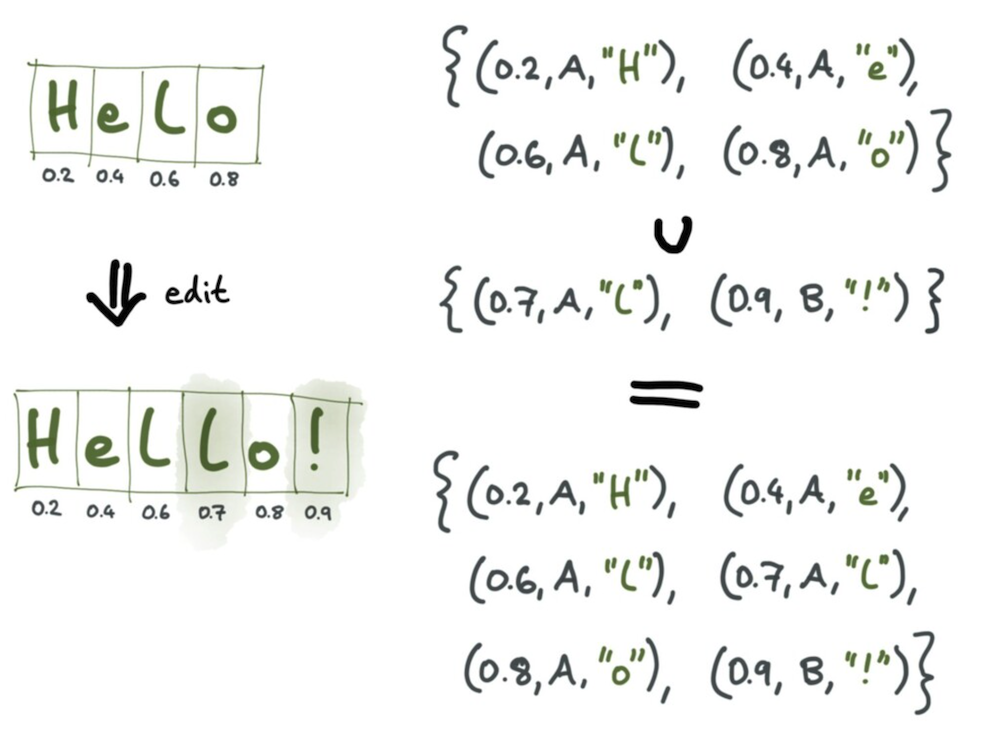
OT의 경우, 인덱스 삽입연산을 수행하는데 이 인덱스가 이전 operation에 의해 변경될 수 있다. 그래서 서버는 이전 operation을 기반으로 연산을 변환해준다. 그래서 순서가 굉장히 중요하다. 하지만 CRDT의 경우 각 개체(사진에서 글자)를 유니크한 값으로 본다. 그래서 텍스트가 추가된다면 새로운 유니크한 값을 생성해서 넣어준다.
예를 들어, 유니크 값을 0과 1 사이의 숫자들로 지정할 때 L과 !를 넣는 상황에서 다음과 같은 연산을 수행한다.
- L은 0.6과 0.8사이에 0.7을 생성 후 삽입
- !는 0.8과 1 사이에 0.9를 생성 후 삽입
동시에 같은 텍스트를 편집하더라도, 합치는 과정에서 유니크한 값으로 판별하기 때문에 충돌은 일어나지 않는다. 그래서 CRDT에서의 연산은 서버 응답을 기다릴 필요없이 바로 수행 가능하다.
그리고 서버에서 병합하든 클라이언트에서 병합하든 같은 결과를 만들기 때문에 네트워크 영향을 직접적으로 받지 않을 수 있다.
CRDT의 특징을 정리해보면 다음과 같다.
- 애플리케이션은 다른 복제본과 연산을 하지 않고
독립적으로,동시에모든 복제본을 업데이트 할 수 있다. - 알고리즘은 발생할 수 있는 모든 불일치를 자동으로 해결
- 복제본은 특정 시점에는 다른 상태를 가질 수 있어도, 결국에는
하나로 수렴하는 것이 보장됨(모든 CRDT는 최종 일관성을 보장하는 특정 수학적 속성을 충족하기 때문에, 최종적으로 하나의 결과로 수렴함이 무조건 보장된다)
CRDT 방식의 문제점
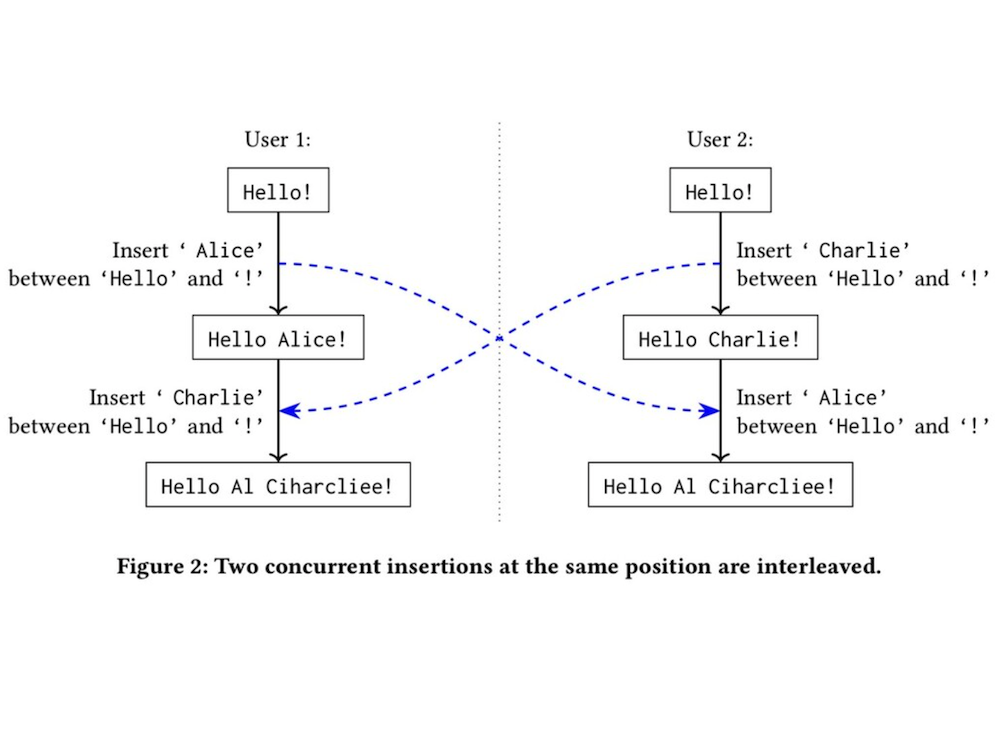
CRDT도 완벽하지 않은 동작이 존재한다. (동작 방식만 봐도 병합 관련한 문제가 생길 수 있음을 예측한 사람이 있을거다) 사진에서 볼 수 있듯이, CRDT를 사용하여 두 글자를 merge했는데 이상한 짬뽕단어를 생성해내버렸다.
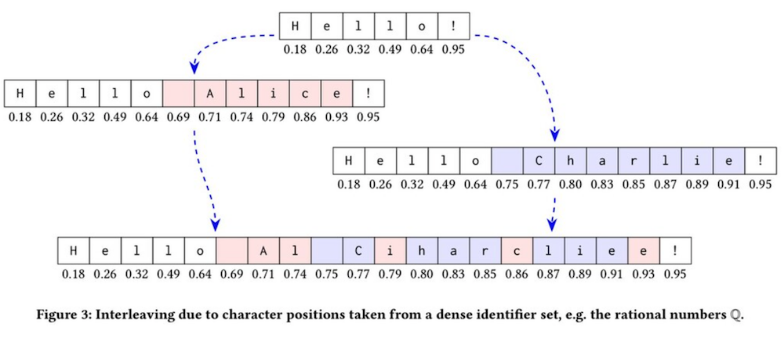
글자 하나에 모두 유니크한 값을 가진다면, 독립적으로 글자들이 랜덤한 값에 의해 merge되어버린다. 그래서 CRDT에서는 이렇게 짬뽕단어를 만들어내는 문제를 해결할 수 있는 다양한 알고리즘들이 존재한다(Logoot, LSEQ, RGA, Treedoc, WOOT, ...)
본론: 피그마 이야기
이제 OT와 CRDT를 확실히 정리했으니, 피그마의 구현 방법을 알아보자.
Websocket을 기반으로 한 클라이언트/서버 아키텍처 사용
figma는 "적절한 링크만 있으면, 모든 사람이 작업하는 사람을 방해하지 않고도 디자인 프로젝트의 현황을 볼 수 있는 서비스"를 만들고자 동시협업 디자인 툴 개발을 시작했다고 한다. 피그마는 이러한 동시편집 기능 개발을 위해 웹소켓을 기반으로 한 클라이언트/서버 아키텍처를 사용하였다.
Figma 동작방식
일단 Figma의 동작방식을 순차적으로 알아보자.
- 문서가 열리면 클라이언트는
파일 사본을 다운로드함 - 해당 문서에 대한 업데이트는 양방향으로
Websocket 연결을 통해 동기화됨 - 임의의 시간동안 오프라인 상태가 되어 편집을 계속할 수 있음.
- 다시 온라인으로 돌아오면 클라이언트는 문서의 새 사본을 다운로드하고, 최신 상태 위에 오프라인 편집 내용을 다시 적용한 다음, 새 websocket 연결을 통해 업데이트 동기화를 계속함
+) Figma의 문서변경 외에 댓글, 사용자, 팀, 프로젝트 등의 기능은 멀티플레이어 시스템이 아닌 Postgres에 저장하고 완전히 별도의 시스템을 사용하여 동기화한다. 분리한 이유는 성능, 오프라인 가용성, 보안과 같은 특정 속성에 대한 다른 상충 관계로 인해서이다.
figma는 해당 동작방식을 정의하고 반복적인 실험을 통해 프로토타입 환경을 만들어 시뮬레이션을 진행하였다고 한다. 다양한 시나리오를 적용하여 평가한 후, 해당 아이디어를 실제 코드베이스에 접목하였다.
figma는 custom CRDT를 사용함
figma는 Google Docs가 사용하는 OT가 figma 서비스에 적용하기에는 과도하다고 생각하였다. OT는 메모리와 성능 오버헤드가 낮은 긴 텍스트 문서를 편집하는 좋은 방법이지만, 매우 복잡하고 올바르게 구현하기 어려웠다. (위에서 단점으로 언급했듯, 추론하기 매우 어려운 조합 폭발이 걱정되었다고 한다)
figma가 멀티플레이어 시스템을 설계할 때의 가장 큰 목표는 작업을 완료할 때 필요한 것 이상으로 복잡하지 않게 하는 것이었다. 이를 통해 구현과 디버깅, 테스트, 유지관리를 용이하게 하고자 하였다. 또한 figma는 텍스트 편집기가 아니였기 때문에 OT보단 덜 복잡한 방법을 선호하였다.
figma는 OT가 아닌 CRDT에서 영감을 받아 동시편집을 구현하였다. CRDT는 다양한 유형이 있는데, 두 가지만 설명하면 다음과 같다(더 알아보기)
Grow-only set: 유일한 업데이트는 set에 무언가를 추가하는 것. 어떤 순서로든 적용하기만 하면 set의 내용을 확인할 수 있음Last-write-win register: 단일 값의 컨테이너이다. 업데이트는 새 값, 타임스탬프 및 peer ID로 구현이 가능하다. 최신 업데이트의 값을 가져오기만 하면 레지스터의 값을 확인할 수 있음
Figma는 완벽한 CRDT를 구현하지 않았다. CRDT는 중앙 서버가 존재하지 않아도 동시편집이 가능하도록 하는 분산 시스템을 위해 설계된 도구이지만, Figma는 중앙 서버에서 변경사항들을 관리하는 자체 솔루션을 개발하여 서비스를 구현하였다.
이유는 중앙 서버 없는 분산시스템을 구현하면 불가피한 성능 및 메모리 오버헤드가 발생하기 때문이었다. figma는 이 추가적인 오버헤드를 제거하고, 더 빠르고 간소한 구현의 이점을 얻기 위해 중앙서버에서 최종 상태를 결정하도록 하였다.
Figma의 구체적인 설계
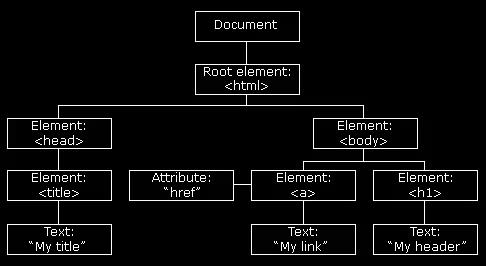
모든 Figma의 문서는 HTML DOM과 유사한 객체의 트리로 구성된다.
- 전체 문서를 나타내는 단일 루트 객체
- 페이지 객체
- 페이지 내용을 나타내는 객체의 계층 구조..
- 페이지 객체
각 객체는 ID와 값이 있는 속성 컬렉션이 있다. (map이나 행이 있는 데이터베이스에 저장될 수 있다고 생각할 수 있음) 즉, figma에 새 기능을 추가하는 것은 일반적으로 객체에 새 속성을 추가하는 것과 같다.
Figma의 multiplayer system 구체적으로 알아보기
Syncing object properties
피그마의 멀티플레이어 서버는 클라이언트가 어떤 객체의 속성에 대해 보낸 최신 값을 추적한다. 그래서 충돌은 두 클라이언트가 같은 객체의 같은 속성을 변경할 때만 발생한다.
- 같은 객체의 관련 없는 속성: 충돌 x
- 다른 객체의 관련 있는 속성: 충돌 x
충돌 발생 시에 문서는 서버로 전송된 마지막 값으로 덮어씌워진다. (이는 CRDT의 Last-write-win register와 유사하지만, 서버에서 이벤트 순서를 정의할 수 있기 때문에 타임스탬프가 필요하지 않다) 즉, Figma에서는 동일한 텍스트 값을 동시에 편집하는 것이 작동하지 않는다. 변경사항은 원자적이고 둘 중 하나로 덮어씌워진다.
Figma는 동시편집은 구현하지만, 완전한 동시편집은 구현되지 않는다는 것을 알 수 있다.
Figma는 빠른 반응성을 위해 클라이언트의 속성 변경 사항은 서버의 확인을 기다리지 않고 즉시 적용된다. 하지만 이 구현방식은 서버에서 들어오는 변경사항을 적용하면서 값을 덮어쓸 때, 충돌하는 변경 사항이 깜빡거리는 문제가 생길 수 있다. 상황은 다음과 같다.
- 동그라미 객체를 파랑에서 초록색으로 바꿈 ->
동그라미 = 초록 - 서버에 변경사항을 보냄
- 짧은 시간 안에 서버에서 동그라미 객체가 노란색으로 변경되었다고 옴 ->
동그라미 = 노랑 - 서버에서 내가 변경한 초록 변경사항이 옴 ->
동그라미 = 초록
3과 4사이는 굉장히 짧은 시간이고, 노란색에서 초록색으로 깜빡거리는 문제가 생길 수 있다.
Figma는 이를 피하기 위해 예측값을 사용자에게 보여주고자 하였고, 따라서 확인되지 않은 변경사항과, 충돌하는 변경사항(노랑)을 삭제하는 방식을 적용하여 깜빡이는 문제를 줄일 수 있었다. (사이트에 있는 gif를 확인하면 더 이해가 쉽다. 사이트를 꼭 들어가보자!)
Syncing object creation and removal
할당되지 않은 객체 ID에 속성을 쓰는 방식을 통해 객체는 자동 생성될 수 없다. 또한 객체를 제거하면 모든 속성을 포함하여 서버에서 해당 객체에 대한 모든 데이터가 삭제되어야한다.
✅ 삭제된 데이터를 서버에 저장하지 않음
Figma에서 객체를 만드는 것도 Last-write-win register와 유사하다. 여기서 객체가 set에 있는지 여부는 해당 객체의 last-writer-wins 속성으로 구분한다. Figma에서는 해당 속성을 서버에 저장하지 않고, 해당 데이터는 삭제를 수행한 클라이언트의 실행 취소 버퍼에 저장된다. 클라이언트가 삭제를 실행취소하는 경우에는 삭제된 객체의 모든 속성을 복원한다. 이를 통해 문서가 편집되면서 크기가 계속 커지는 걸 방지한다.
✅ 오프라인 모드를 위해, 클라이언트가 고유함이 보장되는 ID를 생성
Figma의 시스템은 오프라인 모드도 지원하기 때문에, 서버가 아닌 클라이언트가 직접 고유함이 보장되는 새 객체 ID를 생성할 수 있어야한다. 이는 모든 클라이언트의 고유 ID를 할당한 후, 해당 ID를 새로 생성된 객체 ID 일부로 포함하면 된다. 이렇게 하면 다른 클라이언트는 절대 동일한 객체 ID를 생성할 수 없다.
Syncing trees of objects
일관된 트리 구조로 객체를 배열하는 것은 굉장히 중요한 부분이다. 부모를 바꾸는 경우에 대한 로직의 복잡성은 굉장히 복잡하다. Figma는 트리 구조를 설계할 때 두 가지의 목표를 세웠다.
- 객체의 부모를 변경하는 것은 해당 객체의 관련 없는 속성에 대한 변경과 충돌하면 안됨(색을 변경하는 동안 위치를 조정하면 두 작업은 모두 성공해야함)
- 동일한 객체에 대해 부모 변경작업이 두 번 일어나면, 해당 객체의 사본 두 개를 생성해서는 안된다.
✅ 부모에 대한 링크를 자식의 속성으로 지정
많은 접근 방식은 객체를 삭제하고 다른 곳에 새 ID의 객체를 만드는 방법으로 부모를 재지정한다. 하지만 Figma의 특성상 객체의 ID가 변경될 때 동시 편집이 삭제되므로, 이 방식은 좋지 않았다. 그래서 Figma는 부모에 대한 링크를 자식의 속성으로 지정하는 방식을 사용하였다. 이를 통해 한 객체가 여러 부모를 가지게 되는 에러상황은 발생하지 않을 수 있다.
✅ 사이클이 없어야함
한 클라이언트가 A를 B의 자식으로 만들고, 다른 클라이언트가 B를 A의 자식으로 만드는 동시편집이 있을 때 사이클이 발생할 수 있다. 그래서 Figma의 멀티플레이어 서버는 사이클을 일으킬 수 있는 부모 속성 업데이트를 거부하여 서버에서 발생할 수 없도록 한다. 하지만 Figma는 서버에 반영되지 않은 클라이언트의 변경사항을 미리 반영하기 때문에 사이클 문제가 여전히 발생할 수 있다.
이를 해결하기 위해 Figma는 이러한 객체를 일시적으로 서로 부모를 지정하고, 서버가 클라이언트의 변경사항을 거부하고 객체가 속한 곳에서 부모로 다시 지정될 때까지 트리에서 제거한다. 이 솔루션은 객체가 일시적으로(서버에서 받아올 때까지) 사라지기 때문에 사용자 경험이 좋지 않을 수 있지만, 매우 드문 일시적인 문제에 대한 간단한 솔루션이므로 굳이 복잡한 로직을 추가할 필요는 없었다고 한다.
✅ 자식의 순서를 지정하는 방법
Figma는 부모에 대한 자식의 순서를 결정하는 방법으로 분수 인덱싱 기술을 사용한다. 자식 배열에서의 객체 위치는 0과 1사이의 분수로 표현되고, 객체의 자식의 순서는 위치에 따라 정렬하여 결정한다. 중간 삽입 시 두 객체의 위치 평균으로 위치를 설정한다.
undo 구현
멀티플레이어 환경에서의 undo 구현은 복잡할 수 있다. 예를 들어, 다른 사람이 내가 편집한 객체를 편집하고 실행취소한 경우에는 어떻게 해야할까? 멀티플레이어 환경이기 때문에 다른 사람의 작업을 덮어쓰지 않도록 해야한다.
Figma는 undo operation의 경우 undo에 대한 redo history를 수정하고, redo operation의 경우 redo에 대한 undo hisotry를 수정하도록 구현하였다. 변경사항이 존재할 수 있기 때문에, 현재 상태를 기반으로 수정할 수 있도록 구현하였다. (동영상을 보면 이해가 쉬울거다)
우리 서비스와의 비교
✅ 엔티티의 ID 생성
피그마의 경우, 클라이언트에서 객체에 대한 ID를 생성한다.
우리 서비스의 경우, 어떤 엔티티 생성에 대한 pk를 서버에서 생성하고 관리하도록 하였다. 안드로이드 측에서 pk를 클라이언트에서 생성하는 게 맞지 않냐는 의견이 나왔다가 무산됐는데, 피그마는 이 방법을 사용하여 객체를 만들어냈다는 걸 보니 이 방법을 조금 더 생각해보고 적용해볼껄 하는 생각이 들어 아쉬웠다(좀 더 생각해볼껄)
✅ websocket 오프라인 -> 온라인 반영 로직
우리 서비스(슈퍼보드)는 오프라인에서 온라인으로 변경될 때, 현재까지의 변경사항을 순서대로 쭉 받아온다. 이 방법은 변경사항이 굉장히 많을 때 최신 변경사항까지 반영하는 데 시간이 많이 걸릴 수 있다는 단점이 있다. (순서와 정확함 보장을 위해 ack를 사용하는 로직때문에 더 시간이 지연될 수 있다)
피그마의 경우 가장 최신의 파일 사본을 다운로드하고, 이후 변경사항을 받으면서 적용하는 식으로 동작하여 동기화 시간을 줄인다.
(우리 서비스의 경우는 디비 값 자체를 다 받아와야해서 사본을 다운로드 하는 방식이 맞는지는 잘 모르겠다)
✅ websocket 순서 관련 로직
figma의 경우, 순서가 변경되어도 상관이 없도록 custom CRDT를 구현하여 순서가 꼬여도 상관없도록 하였다. 우리 팀원들이 걱정한 어떤 객체(도형, 텍스트박스 등)를 생성하고 수정하는 로직이 꼬이는 문제까지는 고려하지 않았는데, figma 서비스가 잘 동작하는 걸 보면 이 부분은 딱히 고려하지 않아도 되는 사항인 듯 했다.
만약 순서가 꼬인다고 해도, 따로 처리해주려고 하지 않고 가장 마지막에 수정한 사항을 반영하도록 처리하여 생각보다 간단하게 문제를 해결하였다.
✅ 순서 관련 로직
피그마에서도 순서 관련한 로직이 존재하는데, 우리 서비스와는 살짝 기능이 다르지만 구현방식 자체는 비슷했다. 우리 서비스의 경우 Long 타입 정수기반의 거지수 방식을 사용하였는데, 피그마는 분수 인덱싱 방식으로 이를 구현하였다.
마치며..
동시 편집에 대해 많은 것을 배울 수 있었던 좋은 글인 것 같다. 우리 서비스를 구현하는 과정에서 소켓을 공부할 때 피그마의 글이 있다는 걸 알고있었지만, 다음에 읽자는 생각으로 구현을 먼저한 게 후회된다. 피그마의 구현 방식을 먼저 확인했다면 조금은 빠르게 의사결정이 이루어졌지 않을까 생각한다. 우리 서비스와 비슷한 점이 많아 너무 재미있게 읽을 수 있었다.
다른 서비스 구현방식도 확인하면서 동시편집에 대해 더 공부해보고싶다.
참고자료
https://www.figma.com/blog/how-figmas-multiplayer-technology-works/
https://channel.io/ko/blog/articles/6d8bd607
https://www.youtube.com/watch?v=x7drE24geUw

글 좋아요!
클라이언트가 해야할 일이 확실히 늘어나는 느낌이네요
초기에 찾아봤던 Yjs도 CRDT라는데 사용했으면 프로젝트가 편해졌을것 같기도하네요