
이 포스팅은 2024.06.08 에 작성된 글입니다.
(수정사항)
- 2024.06.09 lost update 예시 추가
서론
동시성 처리, 트랜잭션에 대해 공부하다 write skew와 lost update의 차이점에 대해 궁금증이 생겼다.
lost update가 write skew의 특별한 케이스라고 하는 의견도 있고, 둘은 완전히 다르다는 의견도 있어서 자료를 찾아보고 정리해보려고 한다.
write skew와 lost update를 알아야하는 이유
write skew와 lost update 모두 동시에 실행된 트랜잭션이 같은 데이터를 조회하면서 데이터에 일관성이 깨지는 이상현상이다.
Dirty Read, Non-Repeatable Read, Phantom Read 는 굉장히 잘 알려져있지만, write skew나 lost update는 조금 생소할 수 있다.(필자는 그랬다..😥) 실제로 나는 이 두 가지 문제를 이번에 처음 접했다.
하지만 데이터 무결성, 일관성이 중요한 서비스라면 write skew, lost update도 꼭 고려해야한다!!! 특히 MySQL의 경우 Repeatable Read 트랜잭션 격리 수준에서는 Phantom Read까지는 방지해주지만 이 두 가지 이상현상은 방지해주지 못한다. 따로 처리해주지 않는다면 원하지 않는 데이터가 삽입, 수정될 수도 있다.

그냥 MySQL의 가장 높은 격리수준인 Serializable을 사용해도 이 두 가지 문제는 해결되지만, 성능을 고려하여 Repeatable Read를 사용해야한다면 비관적 락을 사용하는 등 이 두 가지 이상현상을 꼭 해결해야할 것이다!
Read skew
한 트랜잭션이 데이터베이스를 읽을 때 다른 트랜잭션이 커밋한 데이터가 나타나는 현상
Read Skew는 MySQL 의 Repeatable Read에서 MVCC 기술을 이용하여 방지할 수 있다. Write Skew를 적는 김에 간략하게 짚고 가겠다!
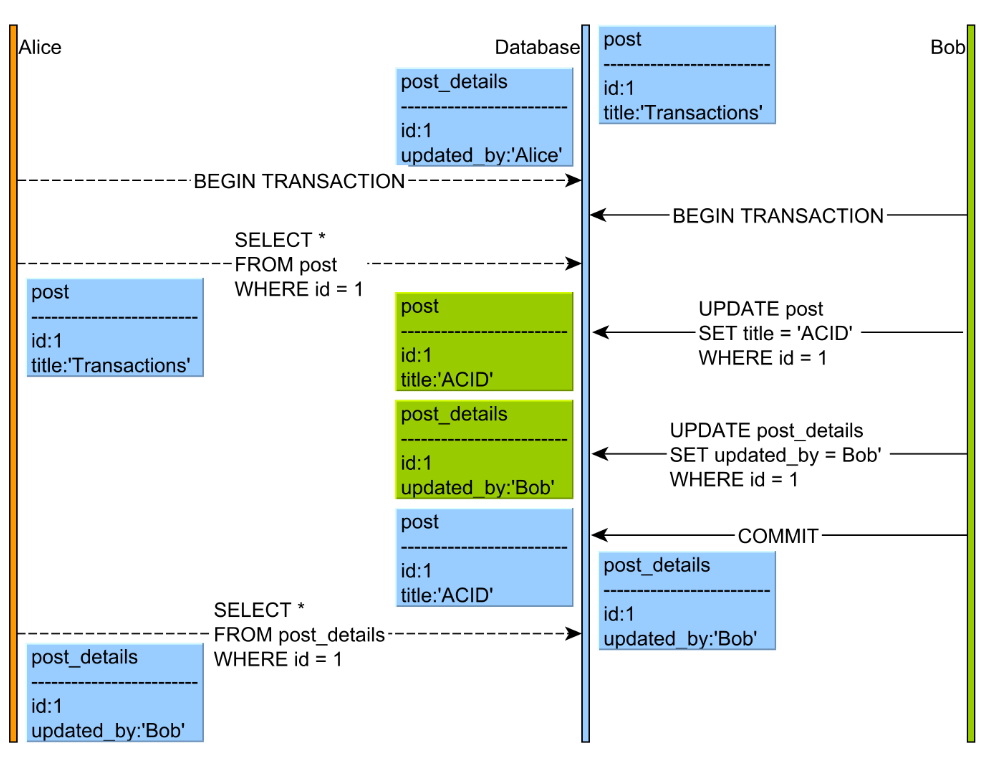
(이미지 출처)
왼쪽에 Alice를 집중해서 보자! Alice의 트랜잭션에서는 같은 쿼리로 데이터를 조회했는데 다른 결과가 나왔다.
Read Skew 이상현상이 발생하면 이렇게 한 트랜잭션 내에서 데이터를 읽을 때 일관되지 않은 데이터가 나온다. 이런 이상 현상은 MySQL의 Read Uncommitted, Read Committed 격리 수준에서 발생할 수 있는 문제이며, Repeatable Read와 Serializable 격리수준에서는 발생하지 않는다.
Write skew
의사 2명이 현재 당직 근무를 설 수 있는 상태다.
만약 당직 근무를 서는 사람이 2명 이상이라면 한 명은 쉴 수 있다. 하지만 필수적으로 1명 이상이 당직근무를 서야한다. 쉬고싶었던 John과 Lisa는 동시에 쉬겠다는 요청을 보낸다.
| No | Transaction1 | Transaction2 |
|---|---|---|
| 1 | BEGIN; | |
| 2 | BEGIN; | |
| 3 | SELECT count(*) FROM doctor WHERE on_call = True; //2 | |
| 4 | SELECT count(*) FROM doctor WHERE on_call = True; //2 | |
| 5 | UPDATE doctor SET on_call = False WHERE id = 1; //13 | |
| 6 | COMMIT; | |
| 7 | UPDATE doctor SET on_call = False WHERE id = 2; //13 | |
| 8 | COMMIT; |
둘은 동시에 요청을 보내고 쉬러 집에가버렸다. 당직 근무를 서는 의사는 0명이 되었다...
다른 예시로 인원 제한이 있는 그룹에 선착순으로 들어가는 상황이다. 인기 그룹인 'backend'그룹의 정원은 5명이고, 이미 4명이 차있는 상태다. John과 Lisa는 동시에 이 그룹에 가입하려고 한다.
| No | Transaction1 | Transaction2 |
|---|---|---|
| 1 | BEGIN; | |
| 2 | BEGIN; | |
| 3 | SELECT count(*) FROM group WHERE name = 'backend'; //4 | |
| 4 | SELECT count(*) FROM group WHERE name = 'backend' //4 | |
| 5 | INSERT INTO member_group values ('John', 'backend') //13 | |
| 6 | COMMIT; | |
| 7 | INSERT INTO member_group values ('Lisa', 'backend') //13 | |
| 8 | COMMIT; |
그룹의 제한인원은 5명이지만 6명이 들어와버렸다!
Lost update 예시
쇼핑몰의 경우라고 가정해보자. stock에는 물건의 재고가 들어있다.
| No | Transaction1 | Transaction2 |
|---|---|---|
| 1 | BEGIN; | |
| 2 | BEGIN; | |
| 3 | SELECT stock FROM product WHERE id=2; //20 | |
| 4 | SELECT stock FROM product WHERE id=2; //20 | |
| 5 | UPDATE product SET stock = 13 WHERE id = 2; //13 | |
| 6 | COMMIT; | |
| 7 | UPDATE product SET stock = 16 WHERE id = 2; //13 | |
| 8 | COMMIT; |
이 경우 처음 Transaction1의 동작은 완전히 무시되고 결과가 16이 나와버린다. 재고가 한정되어있는 경우에는 굉장히 치명적인 결과를 낳을 수 있다. (재고가 없는데 배송을 해야하는 상황...)
실제 코드 예시
public MainAccountDto.Response addCash(Member member, AddCashRequest request) throws InterruptedException {
MainAccount mainAccount = mainAccountRepository.findByMember(member)
.orElseThrow(() -> new RuntimeException());
//Thread.sleep(7000);
mainAccount.addCash(request.getCash());
mainAccountRepository.save(mainAccount);
return MainAccountDto.Response.builder()
.balance(mainAccount.getBalance())
.build();
}service에는 기본 @Transactional 어노테이션을 사용하였다.
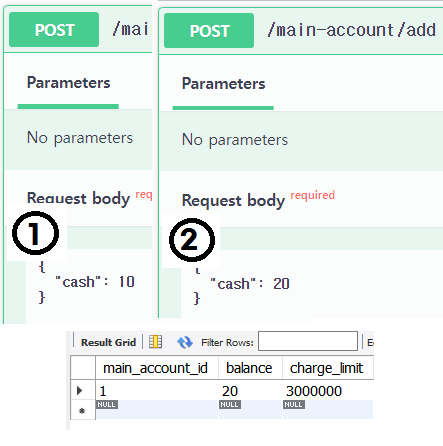
첫 번째 request를 먼저 실행시키고, 거의 동시에 두 번째 request를 실행시켰다.
디비 결과를 보면 첫 번째 request가 추가한 cash인 10이 반영되지 않은 걸 확인할 수 있다. 0 => 10 => 20 이 올바른 순서이고, 만약 거의 동시에 실행했을 경우 두 트랜잭션 중 하나는 실패해야 정상이지만 두 트랜잭션은 모두 성공하였고 결과를 덮어써버렸다. 실제 돈과 관련된 API였다면 굉장히 치명적인 오류였을 것이다.
차이점 비교
둘 다 오래된 데이터를 읽음으로써 일관성이 깨지는 경우이다. 위 예시를 봤을 때 다음과 같이 정리할 수 있을 것 같다.
- write skew는 오래된 데이터를 읽음으로써 이상한 데이터가 삽입/ 수정되는 것
- lost update는 동시에 실행된 트랜잭션들이 오래된 데이터를 읽음으로써 첫 번째의 변경사항이 아예 무시되는 것(후속 tx에 의해 덮어써지는 것)
내가 이해한 바로는 둘이 성격은 비슷한 것 같다. 어떻게 보면 lost updates가 write skew의 특별한 케이스같아 보이기도 한다. 그나마 큰 차이점 하나는 로그테이블과 같이 떨어져있는 테이블에 일관성 없는 데이터가 삽입되는 경우 같다. 이는 write skew에 포함되지만 lost updates의 예시는 아니다.
🤔 굳이 구분해야하나?
둘 다 트랜잭션이 서로 간섭하여 일관성 없는 데이터가 생긴다는 점이 같고, 굳이 구분해야하는지 의문이 들 수 있다. 실제로 MySQL같은 경우에는 Repeatable Read에서 두 문제 모두 해결할 수 없고, Serializable의 경우 두 문제를 모두 해결한다.
하지만 lost update와 write skew를 구분해야한다는 의견이 있어 가져와봤다.
I don't think that characterizing lost updates as a special case of write skew is fully correct. In academia these are considered seperate cases, because you can meaningfully say that a database system prevents lost updates trough snapshot isolation, but not write skew. As stated here: jepsen.io/consistency/models/snapshot-isolation
링크를 타고 들어가보면 PostgreSQL 경우에는 Repeatable Read 트랜잭션 격리 수준에서 Snapshot 격리를 하는데, 이를 통해 lost updates를 방지할 수 있다고 되어있다. (스냅샷 격리가 lost updates 시기를 감지한다고 한다)
하지만 write skew까지는 방지할 수 없다고 적혀있다.
PostgreSQL의 스냅샷 격리에 대해 더 알아보고 싶으신 분은 링크를 참고하면 좋을 것 같다.
마치며..
이 둘을 그렇게 상세하게 구분하지 않아도 될 것 같지만, PostgreSQL을 사용하는 경우라면 Repeatable Read 격리 수준에서 write skew 문제가 발생할 수 있다는 점 정도는 알아두는 게 좋을 것 같다.
쓸데없이 궁금증이 생겨 찾아본 내용이었는데, 좋은 시각을 얻을 수 있었던 것 같다. 데이터베이스마다 트랜잭션 격리 수준 구현방법이 다르고, 다양한 이상이 생길 수 있다는 것을 알게되었고, 내가 사용하는 격리수준에서 어떤 이상이 발생할 수 있는지 알아두는 게 중요하다는 걸 알게되었다.
역시 의미없는 공부는 없는 것 같다.
참고자료
https://vladmihalcea.com/a-beginners-guide-to-read-and-write-skew-phenomena/
https://stackoverflow.com/questions/27826714/lost-update-vs-write-skew
https://vladmihalcea.com/write-skew-2pl-mvcc/
