[Naver] Naver API

0. 네이버 검색 API 이용하기
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8
- urllib: http 프로토콜에 따라서 서버의 요청/응답을 처리하기 위한 모듈
- urllib.request: 클라이언트의 요청을 처리하는 모듈
- urllib.parse: url 주소에 대한 분석
1) 블로그 검색
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.requestclient_id = "W9vtuU0AjeaZ6gUbvEW9"
client_secret = "sTk3PshC7D"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode) 실행 결과 아래와 같이 네이버 블로그에 "파이썬"을 검색했을 경우의 코드가 출력되는 것을 알 수 있다.

2) 글자로 읽을 경우, decode utf-8 설정
print(response_body.decode("utf-8"))import os
import sys
import urllib.request
client_id = "W9vtuU0AjeaZ6gUbvEW9"
client_secret = "sTk3PshC7D"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/book?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)이렇게 다시 출력된다.
3. 만약 블로그 말고 다른 기능에서 검색하고 싶다면?
3_1 카페(cafearticle)
- 코드에서
url = "https://openapi.naver.com/v1/search/cafearticle?query=" + encText
이 부분에서 /search/ 다음 주소를 변경해주기만 하면된다.
import os
import sys
import urllib.request
client_id = "W9vtuU0AjeaZ6gUbvEW9"
client_secret = "sTk3PshC7D"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/cafearticle?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)실행해보면 카페아티클에서 검색된 파이썬 관련 글들이 출력되는 것을 알 수 있다.

3_2 쇼핑(shop)
import os
import sys
import urllib.request
client_id = "W9vtuU0AjeaZ6gUbvEW9"
client_secret = "sTk3PshC7D"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
- 이외에도 책(book), 백과사전(encyc) 등이 있다. 원하는 것 설정해서 사용하면 된다.
01. 상품검색
- 몰스킨이라는 다이어리 상품을 검색해보려고 한다.
import os
import sys
import urllib.request
client_id = "W9vtuU0AjeaZ6gUbvEW9"
client_secret = "sTk3PshC7D"
encText = urllib.parse.quote("몰스킨")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)다음과 같이 출력된다.
1) gen_search_url()
- encText = urllib.parse.quote("몰스킨") url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_dispgen_search_url("shop", "TEST", 10, 3)
- api_node : shop?, movie?, book? 등 무엇을 검색할 것 인가
- search_text : 어떤 단어
- start_num : 몇번째부터 검색할 것인가
- disp_num : 몇개를 출력해줄 것인가
2) get_result_onepage()
datetime.datetime.now()
url = gen_search_url("shop", "몰스킨", 1, 5)
one_result = get_result_onpage(url)
- shop 기능에 검색어 "몰스킨"으로 1번째부터 5개의 url 출력
one_result
one_result["items"]- 하나씩 아이템을 나누어 어떻게 나타나는지 확인해보겠다.

one_result["items"][0]["title"]one_result["items"][0]["link"]one_result["items"][0]["lprice"]one_result["items"][0]["mallName"]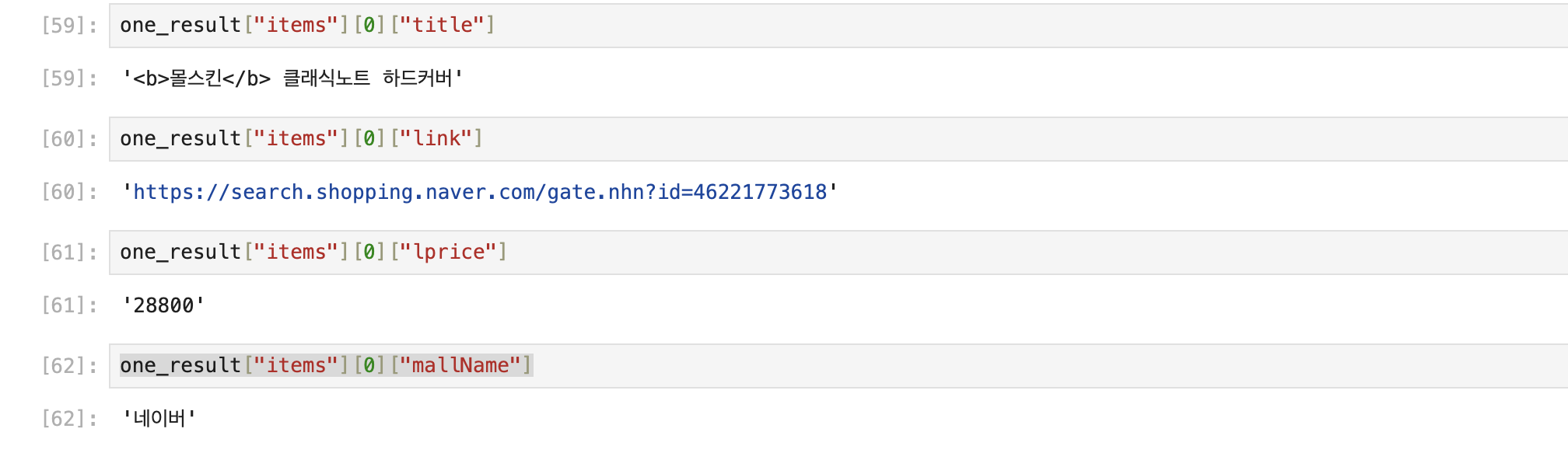
3) get_fields()
one_result["items"][0]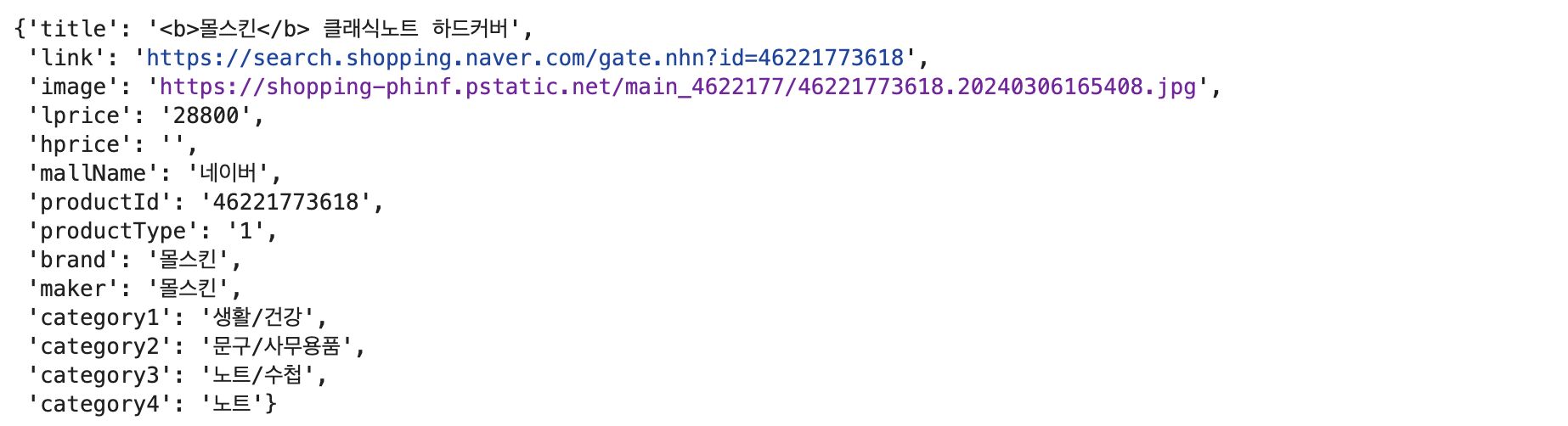
import pandas as pd
def get_fields(json_data):
title = [each["title"] for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"lprice": lprice,
"mall": mall_name,
}, columns=["title", "lprice", "link", "mall"])
return result_pdget_fields(one_result)
4) delete_tag()
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_strimport pandas as pd
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mall_name = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"link": link,
"lprice": lprice,
"mall": mall_name,
}, columns=["title", "lprice", "link", "mall"])
return result_pd get_fields(one_result)
url = gen_search_url("shop", "몰스킨", 1, 5)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
pd_result
5) actMain()
for n in range(1, 1000, 100):
print(n)
result_mol = []
for n in range(1, 1000, 100):
url = gen_search_url("shop", "몰스킨", n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
result_mol.info()
result_mol.reset_index(drop=True, inplace=True)
result_mol.info()
result_mol.head()
result_mol.info()
result_mol["lprice"] = result_mol["lprice"].astype("float")
result_mol.info()
6) to_excel
여기서부터는 주피터 노트북에서 xlsxwriter이 설치 되지 않아 Colab으로 넘어왔다는 것을 양해해주길 바란다.
!pip install xlsxwriter다음과 같이 뜨면, 설치가 진행된 것이다.

현재 어느 경로에 있는지 알기 위함이다.
pwd
지금까지 만들어놓은 엑셀을 내보내기 해볼 것이다.
result_mol.to_excel('06_molskin_diary_in_naver_shop.xlsx')다음과 같이 해주면 코랩에서 drive에 저장될 것이다.
02. 시각화
import matplotlib.pyplot as plt
from matplotlib import rc
import numpy as np
import seaborn as sns
import platform
from matplotlib import font_manager, rc
import matplotlib as mpl
%matplotlib inline아래 코드는 코랩에서 한글설정 해주는 코드이다.
!apt-get install -y fonts-nanum*
!rm -rf /root/.cache/matplotlib/*path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf'
font_name = mpl.font_manager.FontProperties(fname=path).get_name()
plt.rcParams['font.family'] = font_name본격적으로 그래프를 그려보겠다.
plt.figure(figsize=(15, 6))
sns.countplot(
x="mall",
data=result_mol,
palette="RdYlGn",
order=result_mol["mall"].value_counts().index
)
plt.xticks(rotation=90)
plt.show()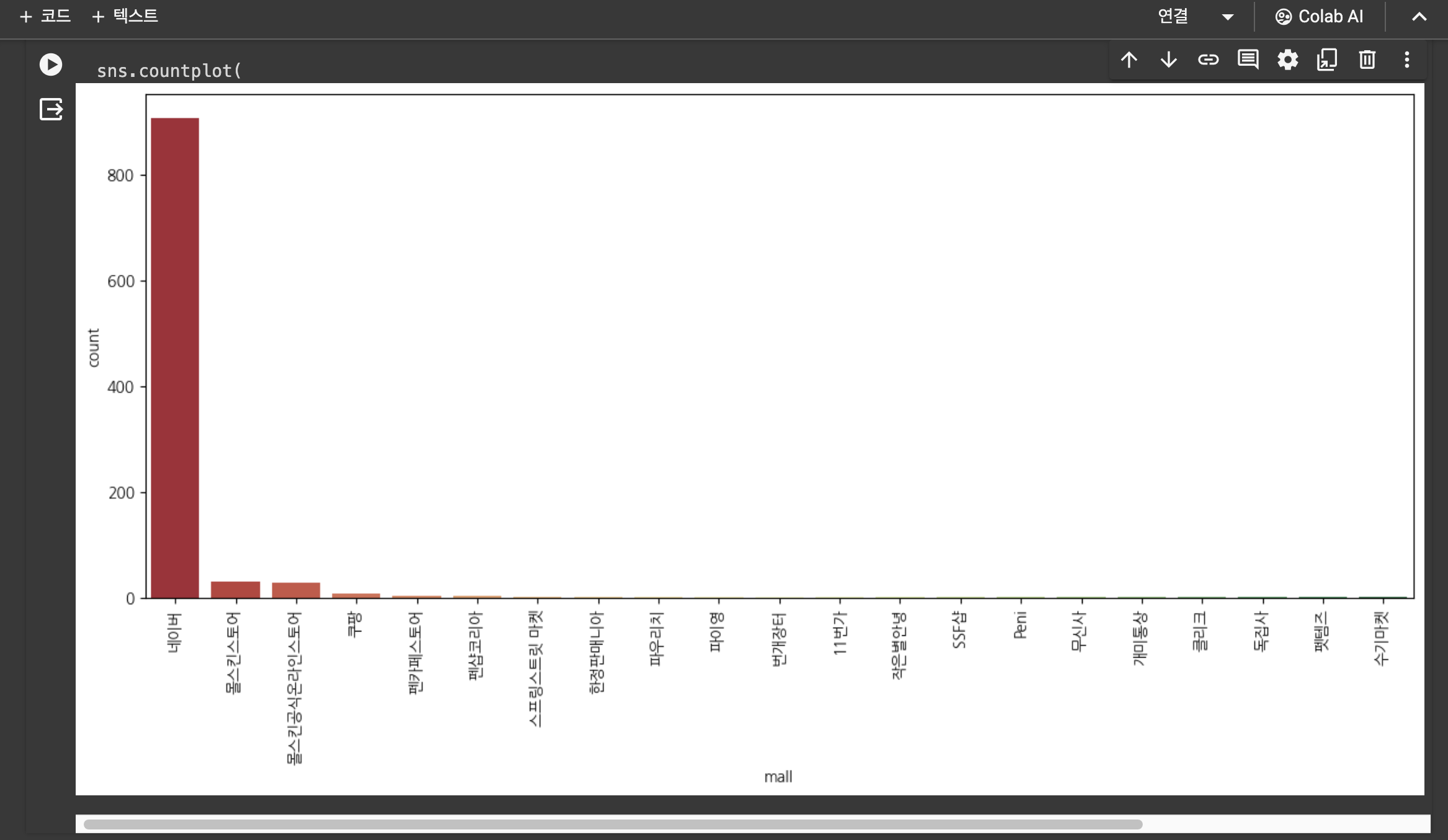

data dreamer