0. Seoul_CCTV 데이터 확인
import pandas as pdCCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8")
CCTV_Seoul.head()
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True)
CCTV_Seoul.head()
하위 데이터 5개를 확인 해볼 수 있다.
CCTV_Seoul.tail()
만약 "소계'부분을 자세히 보고싶다면 sort method를 통해 소계 컬럼을 기준으로 오름차순 또는 내림차순 정렬이 가능하다.
CCTV_Seoul.sort_values(by="소계", ascending=True).head(5)
or
CCTV_Seoul.sort_values(by="소계", ascending=False).head(5)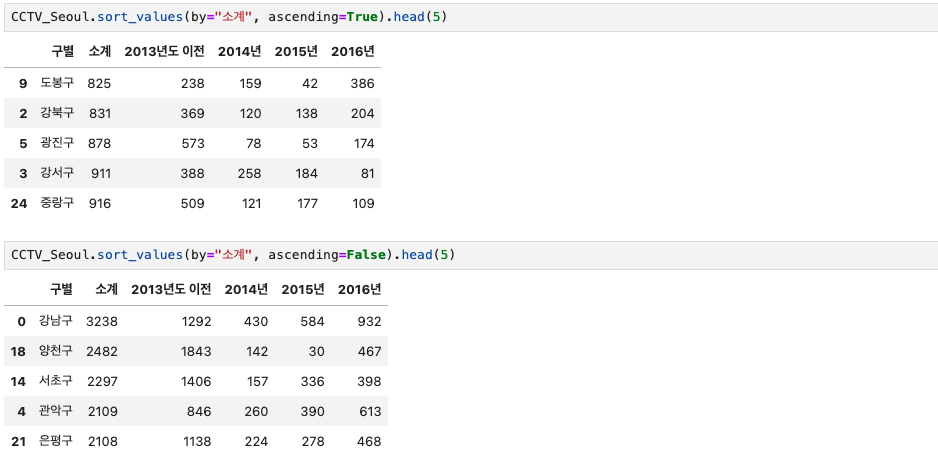
여기에 최근 CCTV 증가율에 대한 컬럼을 추가하려고 한다. 추가 후 CCTV 최근증가율 컬럼을 기준으로 내림차순으로 상위 5개의 데이터를 확인해보자. 그러면 최근 3년간 보유했던 CCTV대비 얼마나 증가했는지, 어느 '구'들이 그렇게 하고 있는지 알 수 있다.
CCTV_Seoul["최근증가율"] = (
(CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"]) / CCTV_Seoul["2013년도 이전"] * 100
)
CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head(5)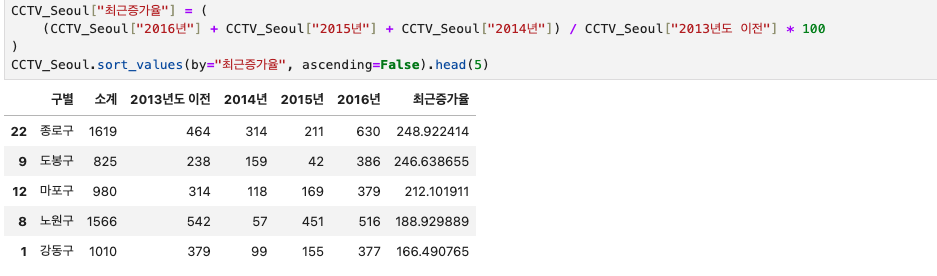
1. Seoul_인구 데이터 확인
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
)
pop_Seoul.head()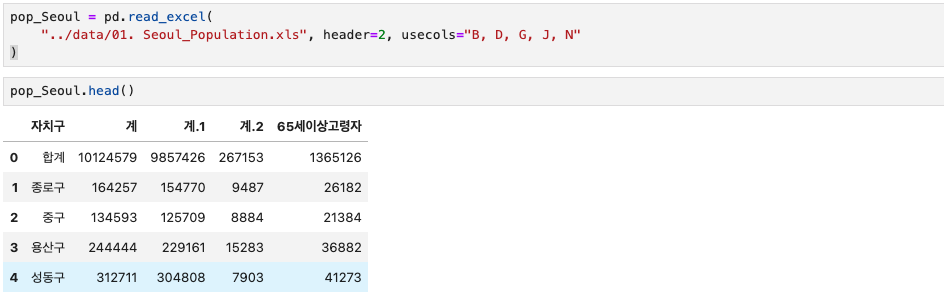
pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자",
},
inplace=True,
)
pop_Seoul.head()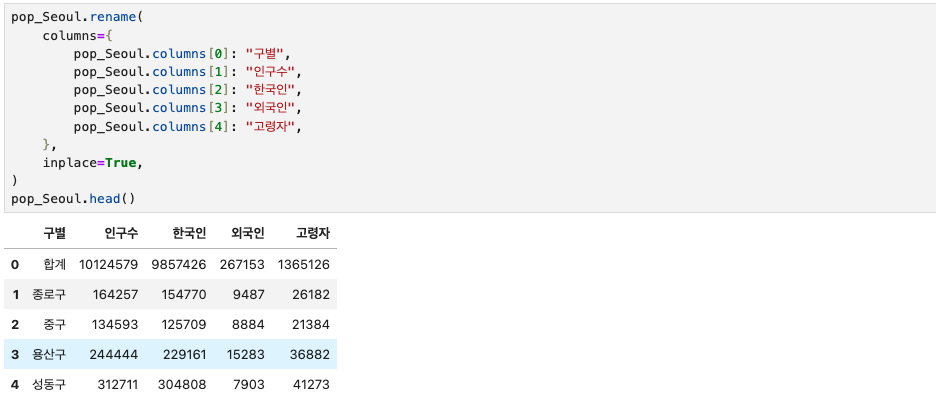
pop_Seoul.tail()
CCTV 데이터와 맞추어 주기 위해 "합계"행을 삭제해보려고 한다.
행 삭제를 위해서는 drop() method를 사용해준다.
pop_Seoul.drop([0], axis=0, inplace=True)
pop_Seoul.head()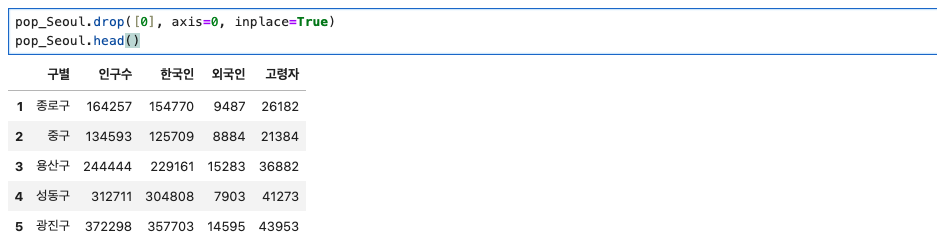
unique() method는 한번이라도 등장한 데이터들이 어떤 것이 있는지, 중복되지 않고 어떤 값들이 있었는지 보여준다.
즉, 중복 없이 어떤 데이터들이 1번 이상 나타났는지 알 수 있다.
len(pop_Seoul["구별"],unique()) 해보았다면, 25개의 '구'가 있음을 알 수 있다.
pop_Seoul["구별"].unique()
그다음에 새로운 컬럼을 만들어주려고 한다.
'외국인 비율', '고령자 비율' 이라는 두 개의 컬럼을 만들어준다.
pop_Seoul["외국인비율"] = pop_Seoul["외국인"] / pop_Seoul["인구수"] * 100
pop_Seoul["고령자비율"] = pop_Seoul["고령자"] / pop_Seoul["인구수"] * 100
pop_Seoul.head()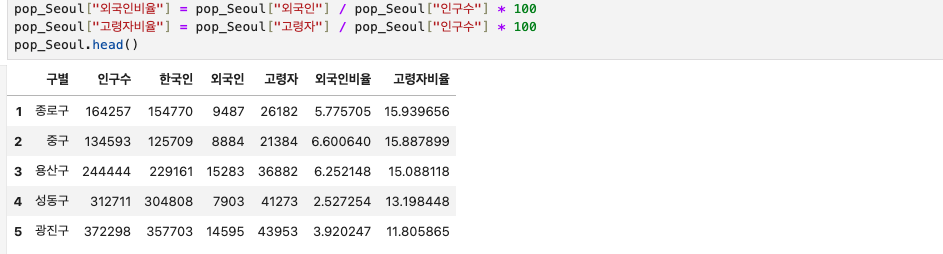
이것을 토대로 인구수를 기준으로 sorting해보자.
pop_Seoul.sort_values(["인구수"], ascending=False).head(5)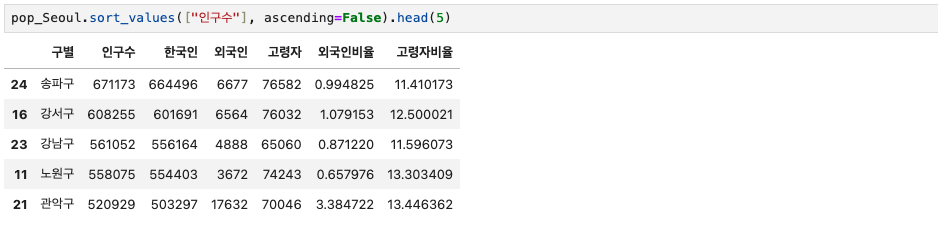 인구수가 어느 구별로 많은지 알 수 있다.
인구수가 어느 구별로 많은지 알 수 있다.
외국인 비율로 sorting하면 아래와 같다.
pop_Seoul.sort_values(["외국인비율"], ascending=False).head(5)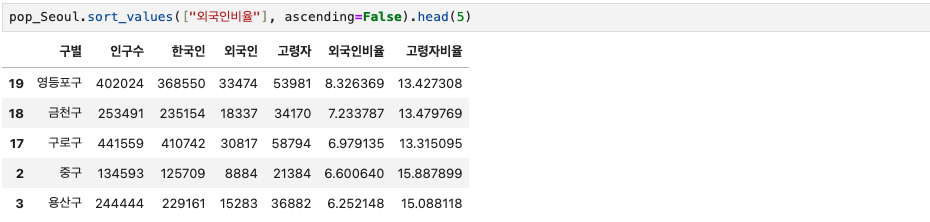
고령자 비율로도 sorting 해보자.
pop_Seoul.sort_values(by="고령자비율", ascending=False).head(5)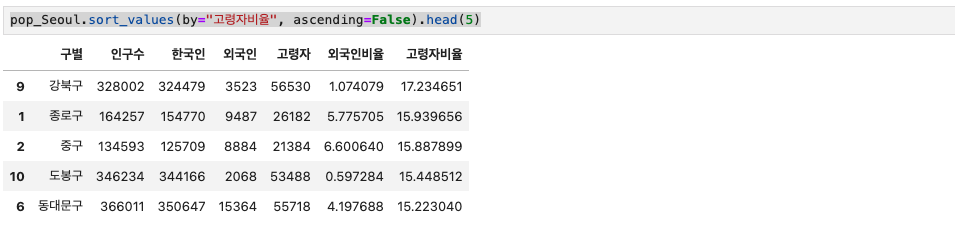
여기까지 데이터프레임에 담긴 데이터를 탐색해보고 컬럼을 수정하거나 추가, 삭제해보며 데이터를 정렬하여 필요한 정보를 확인해보았다.
2. 두 데이터 합치기
나는 CCTV_Seoul 과 pop_Seoul 데이터를 가지고 있다.
CCTV_Seoul.head(1)
pop_Seoul.head(1)
이 두 데이터를 합치기 위해 left 자리에는 CCTV_Seoul, right자리에는 pop_Seoul 데이터를 넣어주었다. 공통되는 컬럼을 찾았을때, 구별이라는 공통된 컬럼이 존재하여 on="구별" 으로 기준값을 잡아주었다. 자동으로 inner가 되어 공통된 값 부분만 출력되었다.
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on="구별")
data_result.head()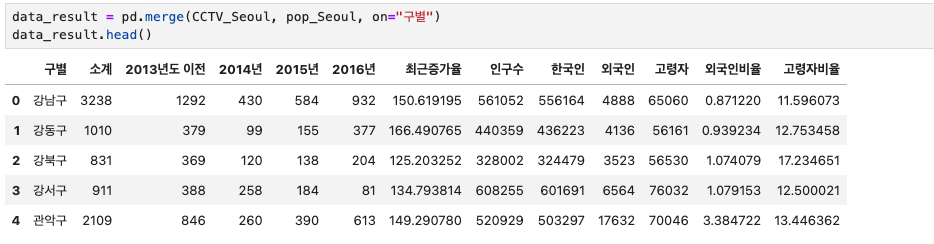 여기에서 연도별 데이터 컬럼을 삭제해주고자 한다.
여기에서 연도별 데이터 컬럼을 삭제해주고자 한다.
del data_result["2013년도 이전"]
del data_result["2014년"]
data_result.head(3)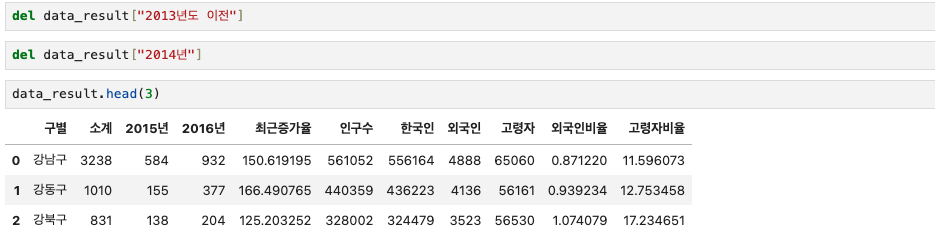 다른 방법으로 남아있는 연도별 데이터 컬럼을 삭제해주겠다.
다른 방법으로 남아있는 연도별 데이터 컬럼을 삭제해주겠다.
이때 axis옵션을 설정해주어야 하는데, 기본 axis=0이면 가로축(행)이다. 나의 경우, 열 기준으로 삭제할 것이기 때문에 axis=1로 설정해준다. 그리고 변경된 것을 객체에 바로 저장해주기 위해 inplace=True해준다.
data_result.drop(["2015년", "2016년"], axis=1, inplace=True)
data_result.head()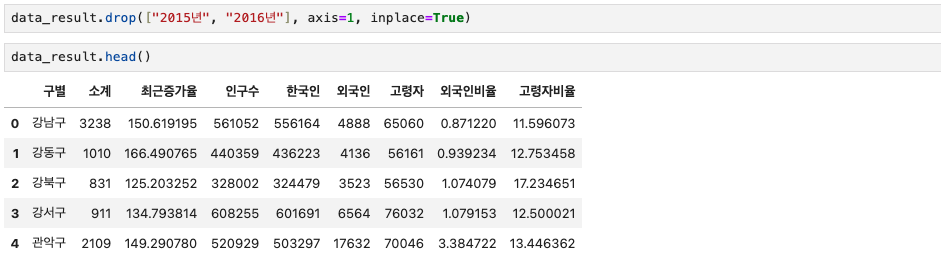
시각화 작업에 앞서 "구별"을 index로 설정해주려고 한다.
인덱스 변경을 위해서는 set_index()에 선택한 컬럼을 넣어주어 데이터 프레임의 인덱스로 지정한다.
data_result.set_index("구별", inplace=True)
data_result.head()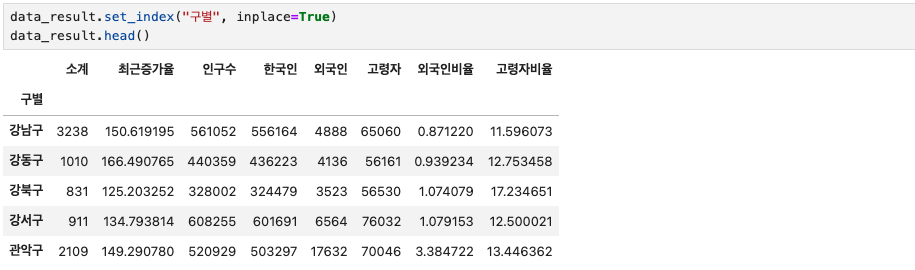
이 상태에서 상관계수를 확인하려고 한다.
correlation의 약자인 corr()를 이용해 상관계수가 0.2이상인 데이터를 비교할 수 있다.
컬럼을 기준으로 소계와 최근증가율, 소계와 인구수.. 이런식으로 한개씩 짝지어 상관계수 값이 나타난다.
상관계수 값을 보고 0.2이상 인것을 추려서 데이터 분석이 가능하다.
data_result.corr()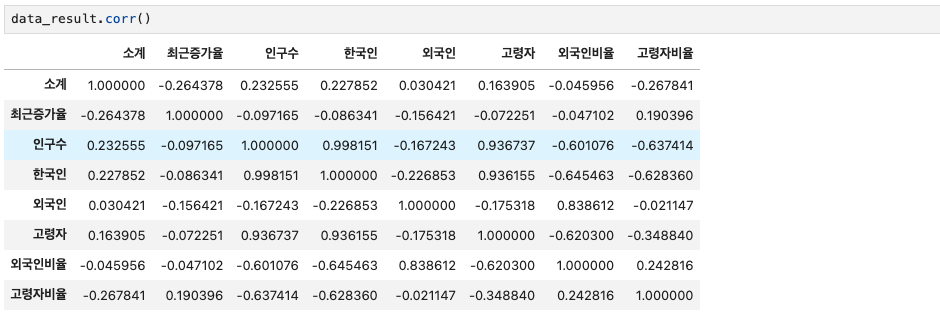
아래와 같이 info()를 확인해보면, 각 데이터 타입이 무엇인지 확인해 볼 수 있다.
data_result.info()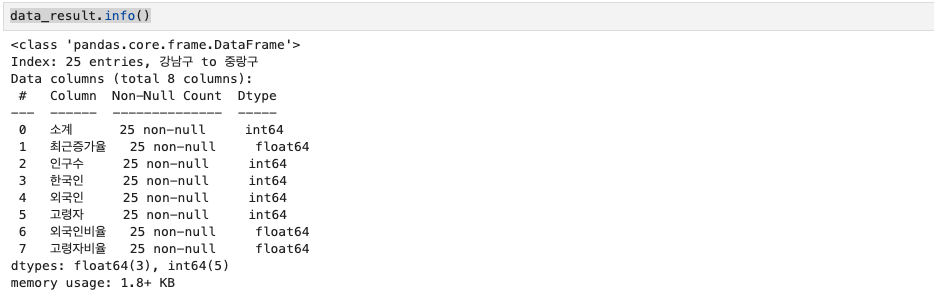
여기까지 했으면,
CCTV비율이라는 컬럼을 하나 만들어주려고 한다. 소계 / 인구수 로 인구수 대비 CCTV 비율을 계산한다.
data_result["CCTV비율"] = data_result["소계"] / data_result["인구수"]
data_result["CCTV비율"] = data_result["CCTV비율"] * 100
data_result.head()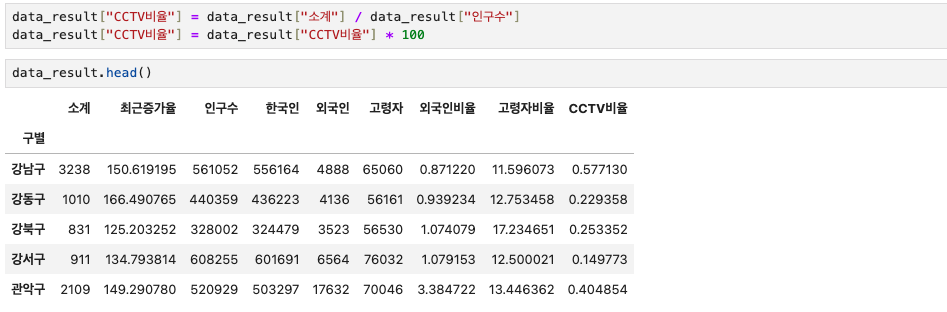
내림차순으로 정렬하여 결과값을 확인해보면,
data_result.sort_values(by="CCTV비율",ascending=False).head()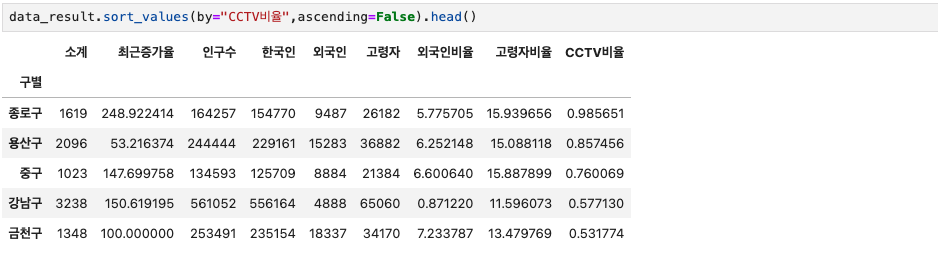 나타나는 '구'들이 CCTV비율이 높은 지역이라 확인할 수 있다.
나타나는 '구'들이 CCTV비율이 높은 지역이라 확인할 수 있다.
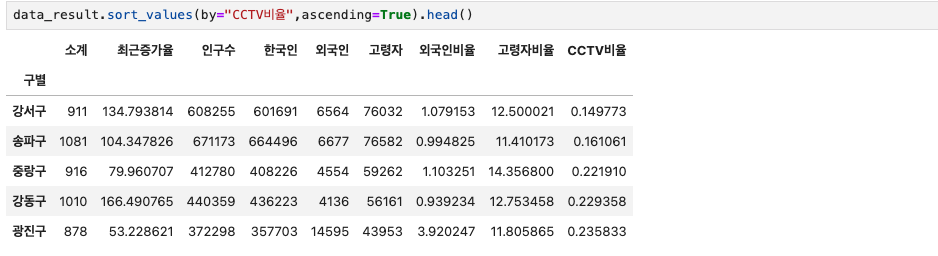
반대로 True 옵션을 주면 CCTV비율이 낮은 '구'를 비교해볼 수 있다.
data_result.sort_values(by="CCTV비율",ascending=True).head()