프로그램을 하다 보면 이름이 같은 변수와 함수를 사용하는 경우가 있다. 객체지향을 하다보면 함수의 이름이 겹치게 오버로딩 혹은 오버라이딩을 하는 것을 권장하기도 하는데, 이때 컴파일러가 무엇을 사용해야 하는지 모르는 '모호성(Ambiguity)'이 생겨난다.
using과 모호성을 살펴보자
using & 모호성
#include <iostream>
namespace a
{
int my_var(10);
}
namespace b
{
int my_var(20);
}
int main()
{
/*using namespace std;*/
using std::cout;
using std::endl;
cout << "Hello" << endl;
cout << b::my_var << endl;
cout << a::my_var << endl;
return 0;
}우리가 지금까지 using namespace std를 사용하여 코드를 구성했으나 내부적으로 어떻게 되어 있는지 확인해 본적이 없다. 눈치 빠른 사람들은 이미 알았겠지만, namespace를 배우면서 알게 되지 않았을까? 위의 코드를 보면 std라는 namespace에 cout과 endl이 들어있다는것을 알 수 있다. 즉, std namespace에 cout과 endl의 함수가 선언되어 있다는 것이다.
cout << b::my_var << endl;의 코드를 보면 더욱 쉽게 이해할 수 있을 것이다. 그럼 다음 이미지를 보자.
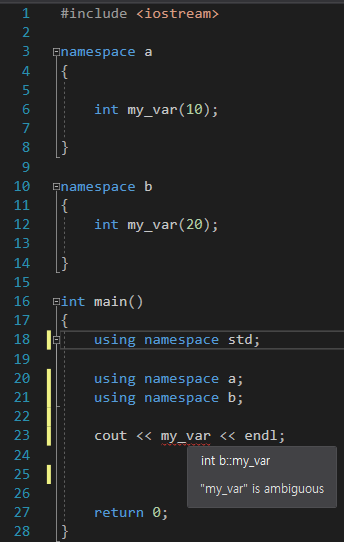 이 경우에 대해 생각해보자. 이때 '모호성'이라는 것이 나온다. 위의 코드처럼 사용하게 된다면, compiler의 입장에선 어떤
이 경우에 대해 생각해보자. 이때 '모호성'이라는 것이 나온다. 위의 코드처럼 사용하게 된다면, compiler의 입장에선 어떤 my_var을 사용해야 하는지 모른다. 이래서 error을 발생시킨다.
만약 namespace안에 변수의 이름이 다르다면 error가 나지 않는다. 만약 변수의 이름이 같다면 namespace를 명시하고 ::을 넣고 작성하는 것이 올바르지만, 그러기 싫을 땐 어떻게 해야하는가?
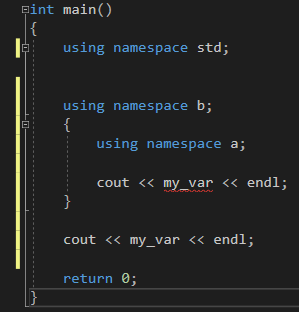 중괄호를 이용해 코드를 작성하면 된다. 근데 위의 이미지를 보면 아직도 '모호성'이 문제가 된다. 왜 그럴까? 중괄호 밖의
중괄호를 이용해 코드를 작성하면 된다. 근데 위의 이미지를 보면 아직도 '모호성'이 문제가 된다. 왜 그럴까? 중괄호 밖의 my_var는 namespace b의 영향을 받지만 namespace a의 영향을 받진 않는다. 하지만!!! 중괄호 안의 my_var는 여전히 namespace a와 namespace b의 영향을 받으므로 '모호성'이 뜨게 되는 것이다. 이럴 경우에는 다음과 같이 코드를 작성한다.
#include <iostream>
namespace a
{
int my_var(10);
int my_a(123);
}
namespace b
{
int my_var(20);
int my_b(456);
}
int main()
{
using namespace std;
{
using namespace a;
cout << my_var << endl;
}
{
using namespace b;
cout << my_var << endl;
}
return 0;
}중괄호 2개를 이용하여 구분을 지어 준다면 '모호성'의 문제는 사라진다.
using namespace는 편한면도 있지만 위험한 면도 있다. 양날의 검..ㅎㄷㄷ.. 그래서 만약, 특정 헤더파일의 전역범위에 넣어버리면 그 헤더를 포함하는 c++파일에 영향을 주게 된다. 가급적이면 c++파일에 넣는 것이 좋긴하지만, 가끔가다 헤더에 넣긴 하긴 함.. 따라서 가급적 좁은 영역에서 사용할 수 있도록 코딩하는 것이 좋다.
