전편이었던 PFLD의 Preprocess 편을 보면 전부가 아닌 일부이다. 딥러닝은 3가지로 쪼갤 수 있다고 생각한다.
[Preprocess] - [model] - [Postprocess]
이 3가지가 가장 중요하며 딥러닝의 pipeline이라 생각한다. dataset.py도 Preprocess에 속하며 model단까지 가기전까진 모두가 Preprocess에 속한다고 생각하면 된다.
우선 전에 WFLW Dataset의 데이터 형식부터 복기해보도록 하자.
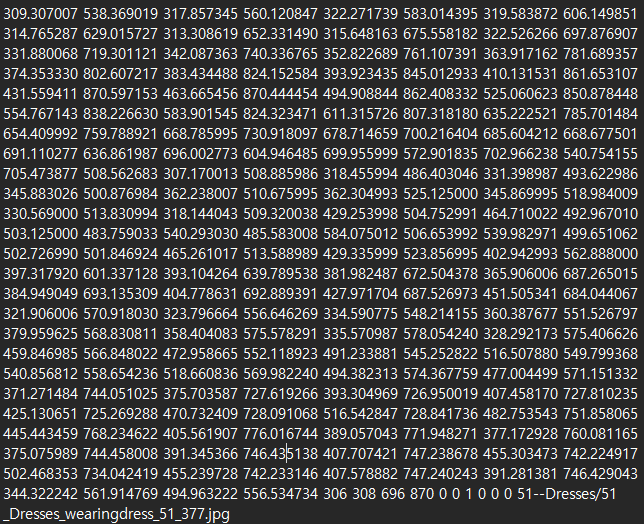
WFLW train dataset은 위의 형식이 계속 반복된다. landmark의 (x, y)쌍 98개, bbox 좌표, attribute 6개, train_img_name으로 구성되어 있다.
앞서 scratch했던 코드를 돌리게 되면 list.txt 파일을 하나 얻게 된다. 
list의 format은 위와 같으며

위의 이미지처럼 출력이 나오게 되는데, 모두 0과 1사이의 값을 갖게 되는 것을 알 수 있다.
우린 이 데이터를 학습에 사용하려고 하니 dataset.py에서 크게 수정하거나 고칠 내용은 없다. 따라서 짧고 쉽게 구현이 가능하다.
# dataset.py
import cv2
import torch
import numpy as np
from torch.utils.data import Dataset
class WFLWDataset(Dataset):
def __init__(self, file, transform=None):
self.file = file
self.line = None
self.img = None
self.landmarks = None
self.attribute = None
self.euler_angle = None
self.transform = None
with open(file, 'r') as f:
self.file = f.readlines()
def __len__(self):
return len(self.file)
def __getitem__(self, idx):
self.line = self.file[idx].strip().split()
self.img = cv2.imread(self.line[0])
self.landmarks = np.asarray(self.line[1:197], dtype=float32)
self.attribute = np.asarray(self.line[197:203], dtype=int32)
self.euler_angle = np.asrray(self.line[203:206], dtype=float32)
if self.transform:
self.img = self.transform(self.img)
return (self.img, self.landmarks, self.attribute, self.euler_angle)이것이 전부이다. preprocess 파일을 따로 만드는 바람에 getitem()에서 할 역할이 따로 없고 전달만 해주면 DataLoader에서 Batch 단위로 학습할 수 있게되니, Dataset.py는 이처럼 단순하게 작성할 수 있다.
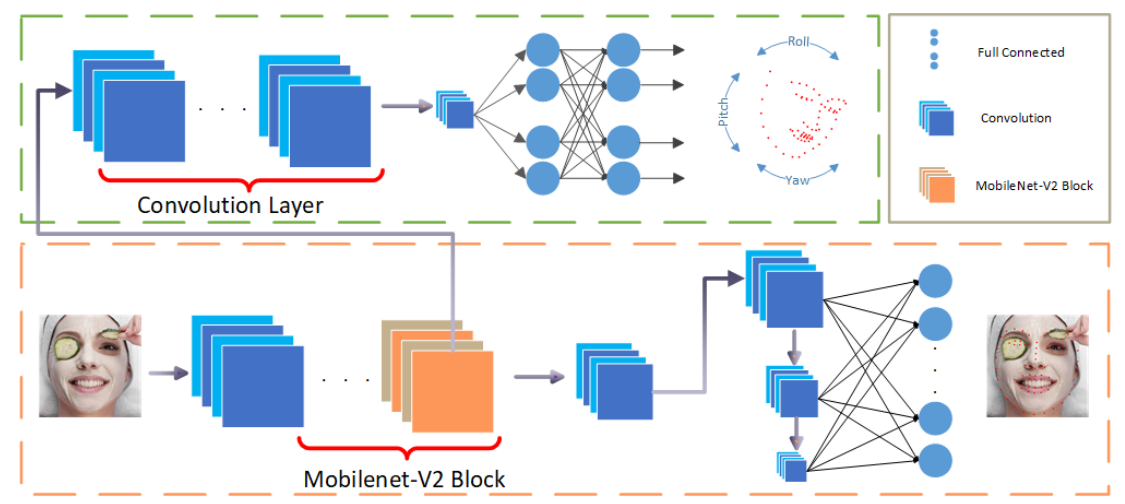
이제 PFLD 논문에서 나온 Backbone인 model을 설계하려고 한다. MobileNetV2는 이미 구현했으므로 중간 feature를 input으로 하는 Auxiliary Network만 추가해주면 된다.
그러나 최근에 올린 MobilenetV2와는 살짝 다른 부분이 있기 때문에, 코드 방식이 살짝 바뀌게 된다. PFLD에서는 친절하게 Backbone design과 Auxiliary design을 보여줬으니 아래를 참고해서 모델을 설계하면 된다. 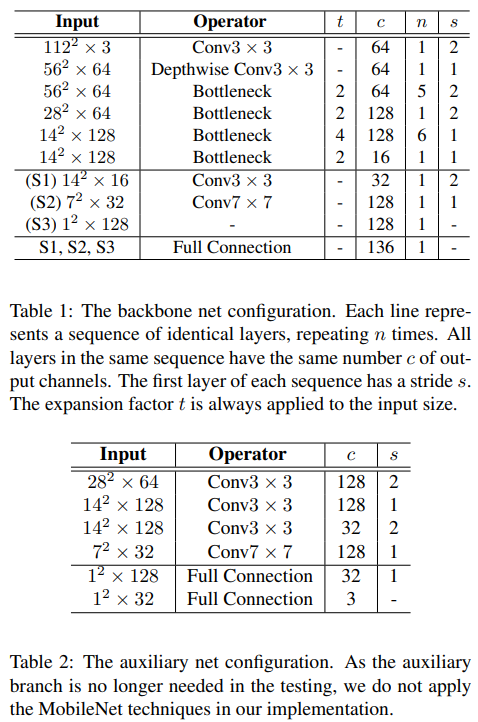
자. 구현해보자!
# model.py
import torch
from torch import nn
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(CNNBlock, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, bias=False, **kwargs),
nn.BatchNorm2d(out_channels),
nn.ReLU6()
)
def forward(self, x):
return self.layers(x)
class DepthwiseConv(nn.Module):
def __init__(self, in_channels, out_channels, stride, **kwargs):
super(DepthwiseConv, self).__init__()
self.DW_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, groups=in_channels, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(),
)
def forward(self, x):
return self.DW_conv(x)
class PointwiseConv(nn.Module):
def __init__(self, in_channels, out_channels, nonlinear=None):
super(PointwiseConv, self).__init__()
self.R_PW_conv = CNNBlock(in_channels, out_channels, kernel_size=1, stride=1)
self.L_PW_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
)
self.nonlinear = nonlinear
def forward(self, x):
if self.nonlinear:
return self.R_PW_conv(x)
else:
return self.L_PW_conv(x)
class Bottleneck(nn.Module):
def __init__(self, in_channels, expansion, out_channels, stride, residual=None):
super(Bottleneck, self).__init__()
print('ssss', stride)
self.layers = nn.Sequential(
PointwiseConv(in_channels, in_channels*expansion, nonlinear=True),
DepthwiseConv(in_channels * expansion, in_channels * expansion, stride),
PointwiseConv(in_channels * expansion, out_channels, nonlinear=False),
)
self.residual = residual
def forward(self, x):
if self.residual:
return x + self.layers(x)
else:
return self.layers(x)
class PFLDBackbone(nn.Module):
def __init__(self, in_channels=3):
super(PFLDBackbone, self).__init__()
# input(-1, 3, 112, 112)
self.conv1_layer = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU6()
)
self.DW_conv1_layer = DepthwiseConv(64, 64, stride=1, padding=1) # output : [1, 64, 56, 56]
self.Bottleneck_1_1 = Bottleneck(64, 6, 64, 2, residual=False)
self.Bottleneck_1_2 = Bottleneck(64, 6, 64, 1, residual=True)
self.Bottleneck_1_3 = Bottleneck(64, 6, 64, 1, residual=True)
self.Bottleneck_1_4 = Bottleneck(64, 6, 64, 1, residual=True)
self.Bottleneck_1_5 = Bottleneck(64, 6, 64, 1, residual=True) # output : [1, 64, 28, 28]
self.Bottleneck_2_1 = Bottleneck(64, 6, 128, 2, residual=False) # output : [1, 128, 14, 14]
self.Bottleneck_3_1 = Bottleneck(128, 6, 128, 1, residual=False)
self.Bottleneck_3_2 = Bottleneck(128, 6, 128, 1, residual=True)
self.Bottleneck_3_3 = Bottleneck(128, 6, 128, 1, residual=True)
self.Bottleneck_3_4 = Bottleneck(128, 6, 128, 1, residual=True)
self.Bottleneck_3_5 = Bottleneck(128, 6, 128, 1, residual=True)
self.Bottleneck_3_6 = Bottleneck(128, 6, 128, 1, residual=True) # output : [1, 128, 14, 14]
self.Bottleneck_4_1 = Bottleneck(128, 6, 16, 1, residual=False)
self.conv2_layer = CNNBlock(16, 32, kernel_size=3, stride=2, padding=1)
self.conv3_layer = nn.Conv2d(32, 128, kernel_size=7, stride=1)
self.bn_l = nn.BatchNorm2d(128)
self.avgpool1 = nn.AvgPool2d(14)
self.avgpool2 = nn.AvgPool2d(7)
self.fc = nn.Linear(176, 196)
def forward(self, x):
x = self.conv1_layer(x)
x = self.DW_conv1_layer(x)
x = self.Bottleneck_1_1(x)
x = self.Bottleneck_1_2(x)
x = self.Bottleneck_1_3(x)
x = self.Bottleneck_1_4(x)
out1 = self.Bottleneck_1_5(x)
print(out1.shape)
x = self.Bottleneck_2_1(out1)
x = self.Bottleneck_3_1(x)
x = self.Bottleneck_3_2(x)
x = self.Bottleneck_3_3(x)
x = self.Bottleneck_3_4(x)
x = self.Bottleneck_3_5(x)
x = self.Bottleneck_3_6(x)
x = self.Bottleneck_4_1(x)
s1 = self.avgpool1(x)
s1 = s1.view(s1.size(0), -1)
x = self.conv2_layer(x)
s2 = self.avgpool2(x)
s2 = s2.view(s2.size(0), -1)
s3 = self.conv3_layer(x)
s3 = s3.view(s3.size(0), -1)
cat = torch.cat([s1, s2, s3], dim=1)
landmarks = self.fc(cat)
return out1, landmarks
# [-1, 64, 28, 28]
class AuxiliaryBlock(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = CNNBlock(64, 128, kernel_size=3, stride=2, padding=1)
self.conv2 = CNNBlock(128, 128, kernel_size=3, stride=1, padding=1)
self.conv3 = CNNBlock(128, 32, kernel_size=3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 128, kernel_size=7, stride=1, padding=0)
self.global_avg = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(128, 32)
self.fc2 = nn.Linear(32, 3)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.global_avg(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
return x
a = torch.randn(1, 3, 112, 112)
model = PFLDBackbone(in_channels=3)
out1, landmark = model(a)
print('out:', out1.shape)
print('landmark : ', landmark.shape)
b = torch.randn(1, 64, 28, 28)
model = AuxiliaryBlock()
print(model(b).shape)
model 같은 경우엔 backbone이 mobilenet v2이기 때문에, 추가적인 설명은 하지 않아도 될 것 같다. Auxiliary Network의 경우에는 train에는 작동하지만 inference단에서는 작동하지 않는다. 그렇기 때문에, PFLD Backbone에 같이 집어넣으면 안되고 따로 빼서 작성해주어야 한다.
이는 나중에 PFLD의 inference 부분을 공부하면 알아갈 내용이니 계속 공부해보자.
