PFLD test code 리뷰하기 전에, 우선 학습한 결과부터 보려고 한다.


만족스러운가? 아니다. 전혀 만족스럽지 않다. 사진 속 정면에 있는 데이터라면 어느정돈 만족스럽다고 생각하지만 고개를 들거나 회전했다면 landmark의 error는 매우 큰 수준이다. 무엇이 문제일까?
의문점
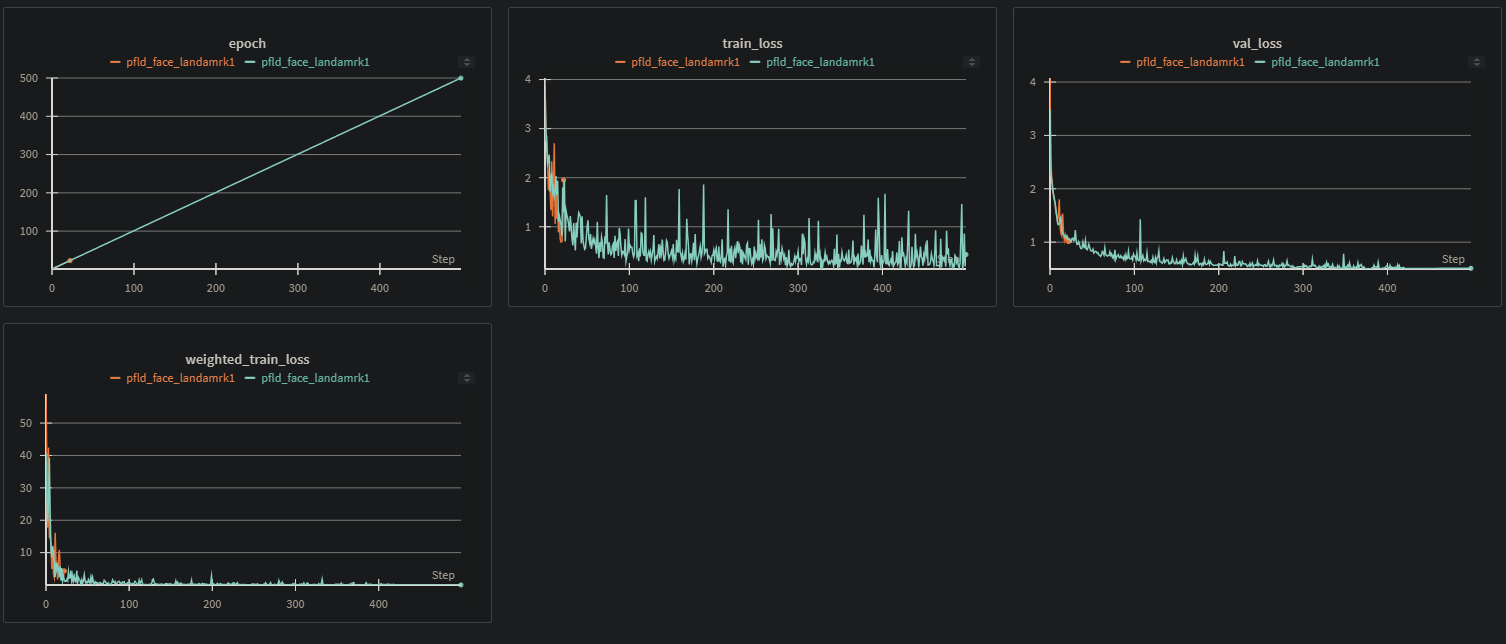
학습 loss를 보면 보면 크게 이상있다고 판단되진 않는다. 다만, 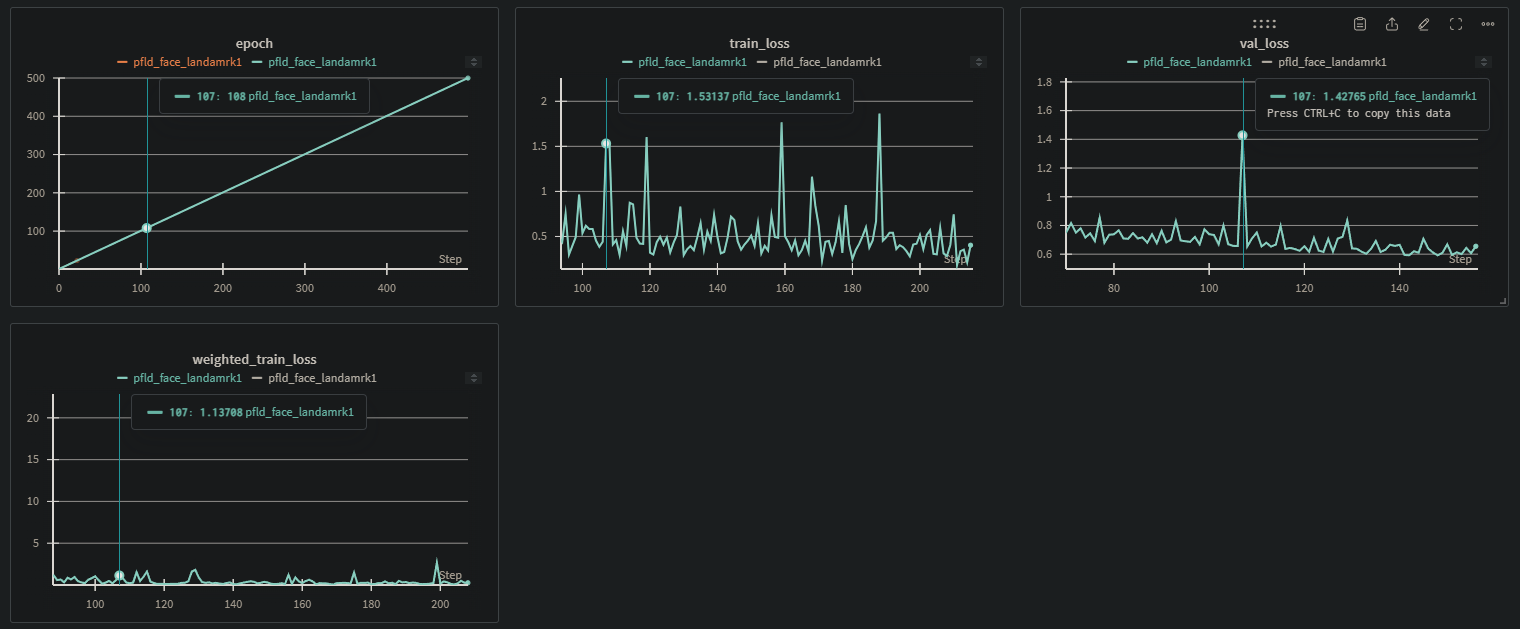
epoch 107에서 validation의 loss가 치솟고 train loss도 같이 치솟는 경향을 보여주는데, 이때 weigthed_train_loss도 살짝 치솟는 경향이 보인다.
설마, epoch 107에서 local minimum에 빠져서 더이상 학습이 되지 않은걸까?
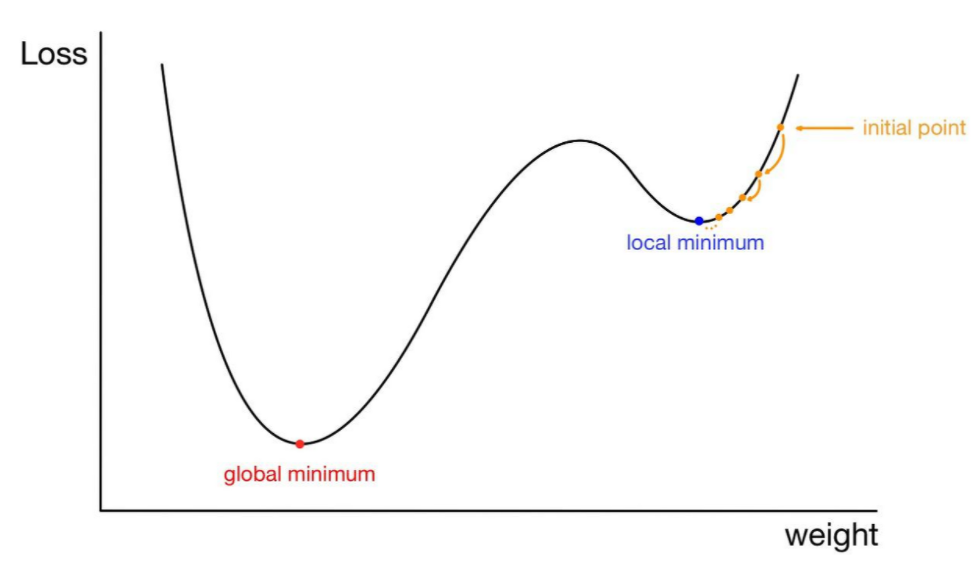
local minimum은 위의 이미지로 설명이 가능한데, 우리가 원하는 이상향이 global minimum이라면 현재 상태는 local minimum일 가능성이 유력하다고 볼 수 있다. 학습 epoch가 부족할지도 모르겠지만 local minimum에서 허우적거릴 수도 있는 노릇이니 말이다.
epoch 107과 epoch 500모델과 비교해보자.
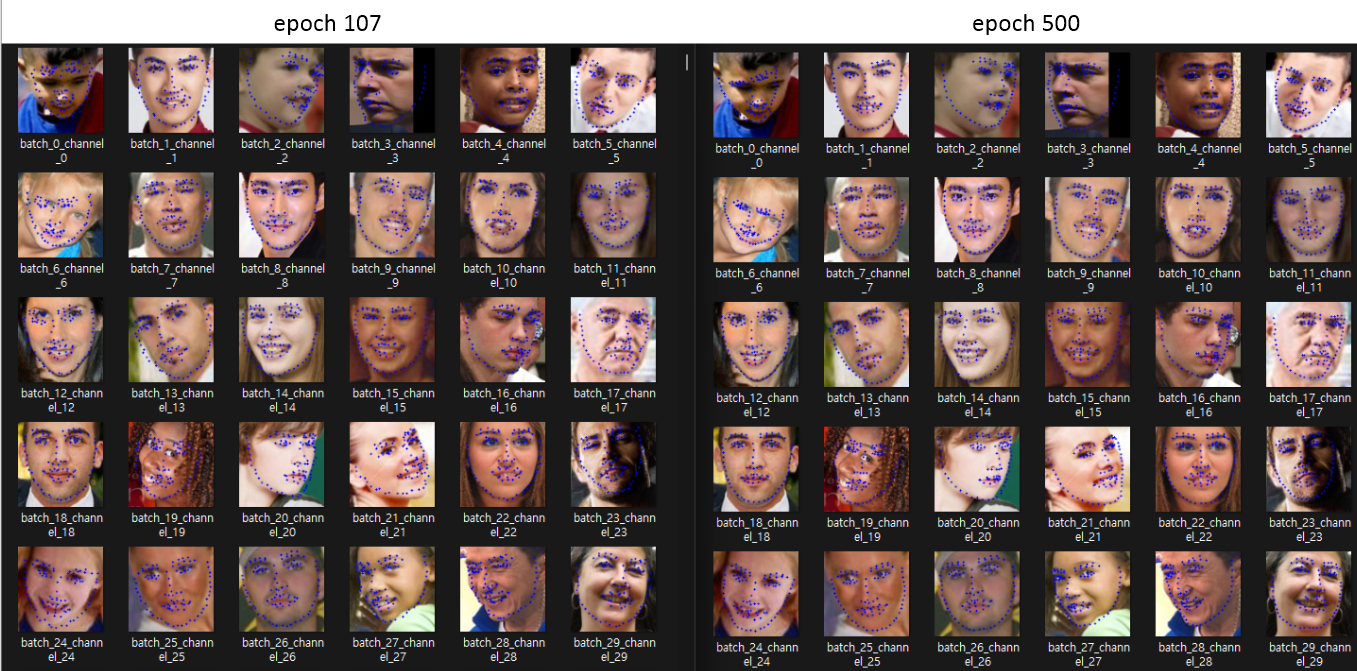
음,,, 이미지만으로는 local minimum으로 빠졌는지 불가하다. 하지만 확실한건 epoch가 높아질수록 고개를 숙이거나 고개를 회전한 데이터들의 landmark 분포는 중앙에 위치하는 경향이 강하다. 즉, data Imbalance가 발생했을 가능성도 있다. 우선은 local minimum에 빠졌는지 확인하기 위해서는 각 layer마다 gradient level을 확인하고 완만하게 감소를 했는지, 중간에 튄 값에서 계속 수렴하는지 확인이 필요하다. 첫번째 학습때에는 그런걸 생각하지 않고 loss만 확인했기 때문에, 다시 처음부터 학습을 하여 local minimum에 빠졌는지 확인을 해보았다.

input image가 conv1 -> conv2 -> conv3를 지날때의 가중치를 보면 local minimum에 빠졌다는 증거는 없다. 다만 model 설계를 했을때, BatchNormalization을 사용했을때, Conv block의 bias를 False를 했어야 했지만 default를 사용했기에 다시 학습해야하는 상황이 발생했다.
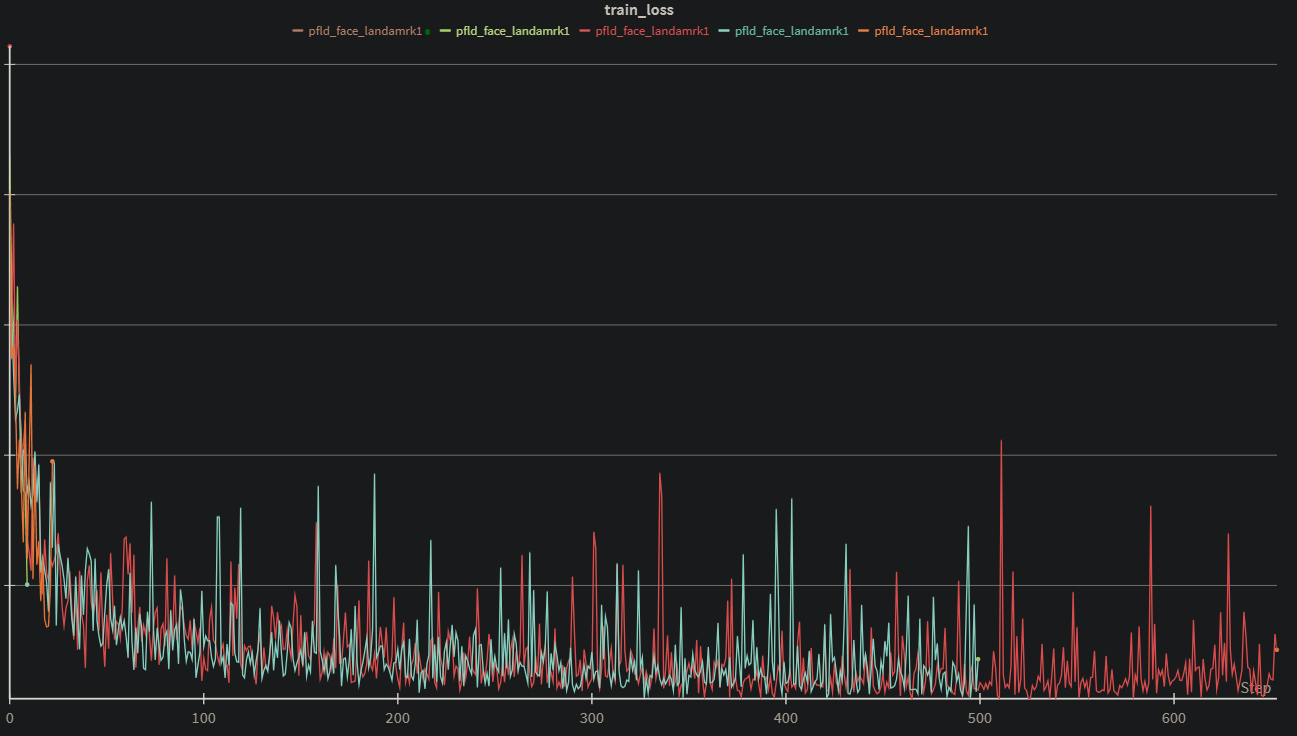
또한 문제점은 train_loss가 발산하는데에 있다. loss.item()을 통해 이동평균선을 구해보면 epoch 500 이후부터는 발산하는 형태를 보이게 된다. train_loss는 weighted_train_loss와 차이점이 있는데
weighted_train_loss
- angle이 클수록 좀더 높은 가중치를 부여함.
- attribute가 희소할수록 좀더 높은 가중치를 부여함.
-> 이를 통해 Data Imbalance를 해결한데에 있다.
train_loss
- angle과 attribute 무시.
- 따라서 모든 angle, attribute 모두 동일한 중요도를 갖게 됨.
-> 모델은 모든 landmark에 대해여 균일하게 학습하려고 시도.
weighted_train_loss는 overfitting으로 인해 local minimum에 빠졌고 이로 인해 모델 자체가 너무 특정 angle, attribute에 치우쳐져 있다는 것을 뜻한다.
즉, 특정 상황에 너무 가중치를 높여준 탓에 일반적인 landmark 상황도 불안정해질 가능성이 높아진다. 
이런 확실한 정면 사진에서 조차 error 발생율이 매우 높다. 이를 해결하기 위해선 가중치 조절이 일정부분 필요하다.
지금부터의 해결방법은 loss landscape를 그려보는 방법 하나와 loss 가중치 값을 조금 바꿔보는게 좋을 것 같다.
가중치를 일단 outlier에 덜 민감하게 만들도록 해야하는게 최우선 과제일 것 같다.
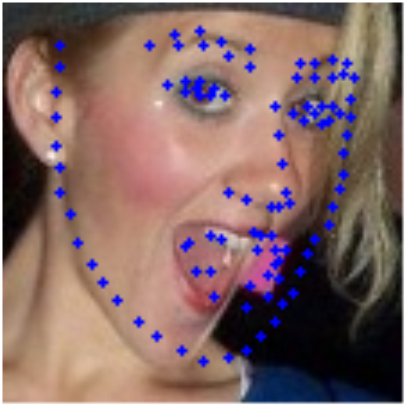
그럼 얼굴 밖으로 나간 landmark에 대해서 덜 민감하게 학습할 가능성이 있으므로 Wing Loss로 바꾼뒤에 다시 학습을 해보자.
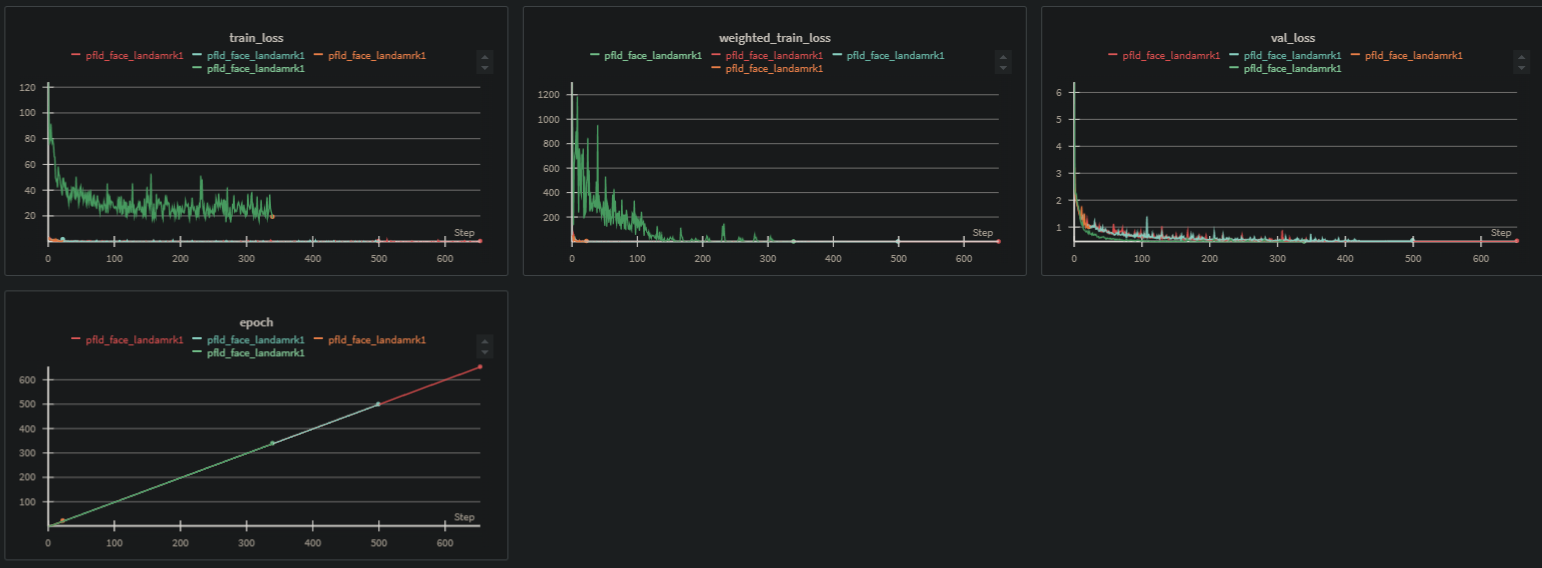
과정을 보자면 train_loss 자체는 수렴중이긴하나 큰 값에서 횡보하고 있다. weighted_train_loss는 만족할만한 수치로 수렴중에 있다. 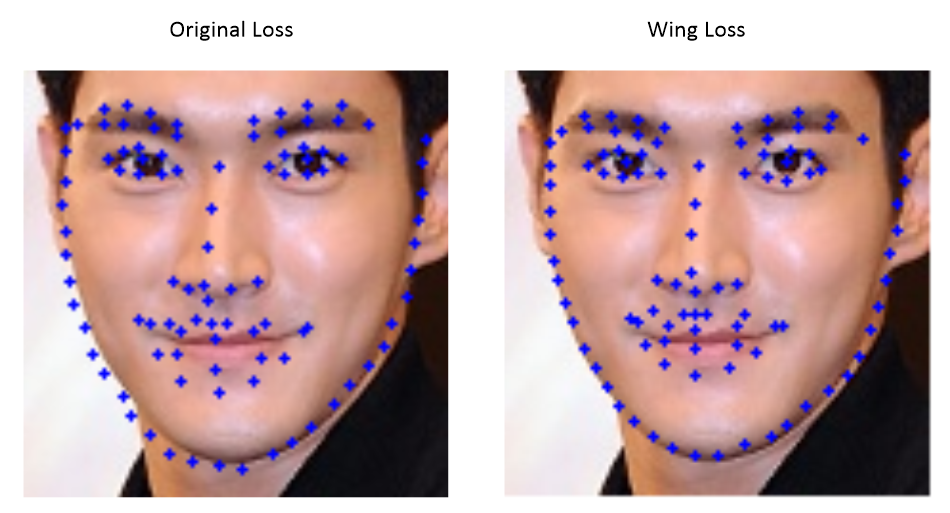
정면 test_data에서는 매우 만족한 결과를 얻었다. 눈의 중앙도 적절히 찾고 있으며 코, 입도 기존보다 적은 오차를 주며 제자리에 위치하고 있다. 다만, 여전히 문제인 것은 회전된 각도, 속성에 대한 예측이다.
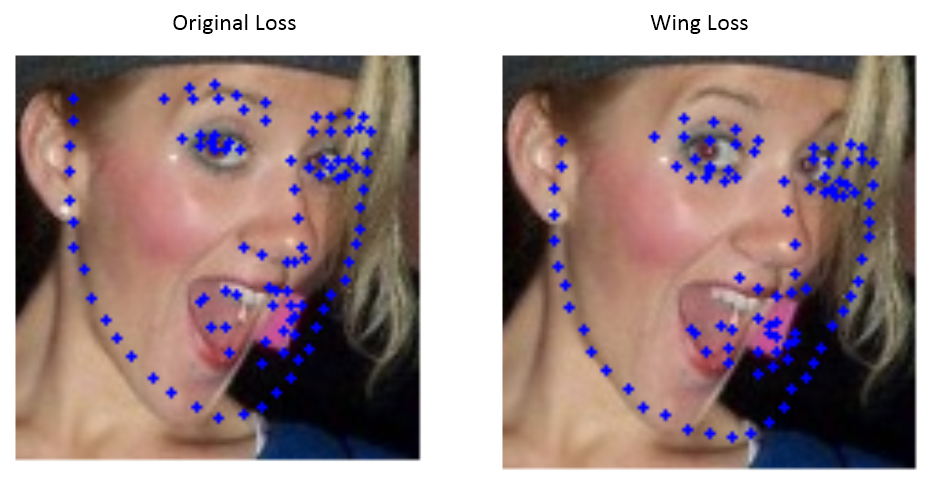
완전히 다른 곳을 예측하고 있으며 이는 여러가지 수정이 필요하다.
wing loss를 사용한 이유는 작은 오차에 비선형적으로 작동하여 오차를 세밀하게 학습하는데, 이는 ground truth landmark와 예측된 landmark의 차이가 작을 경우 더 세밀하게 학습한다는 데에 의미가 있다. 이는 확실히 그렇다.
얼굴이 정면일 경우에는 일반 loss보다 성능이 훨씬 좋은 경향이 있다.

얼굴 외곽의 landmark만 보아도 original loss 보다 더 정확하게 예측하고 있는 것을 볼 수 있다. 코 중앙과 코등의 landmark도 훨씬 섬세한 것을 볼 수 있다. 즉, 작은 오차일 경우에 더 세밀하게 학습한다는 것을 보여준다.

고개를 회전했을 경우, groundtruth landmark와 모델이 예측한 landmark의 차이가 커지게 되는데, wing loss의 경우 선형적으로 값이 증가하기 때문에, loss값에 덜 영향을 미치게 된다.
처음에 loss를 세웠던 것을 보면 l2 loss를 사용하기 때문에, groundtruth와 예측한 landmark 사이의 error를 제곱하여 loss를 키우는 경향이 있는데, wing loss의 경우에는 이때 선형적으로만 loss를 키우기 때문에 l2 loss에 비해서는 loss값에 덜 영향을 준다는 것이다. 이 때문에, 모델이 안정적으로 학습할 수 있게 해준다. (loss값이 커지게 되면 모델이 outlier에 민감하게 학습되기 때문.)
예측된 결과를 본다면 landmark의 예측이 너무 튀는 경우의 사진에는 답이 없지만, 얼추 맞춘 landmark의 사진을 보면 wing loss의 landmark 사진들의 코 landmark는 매우 세밀한 것을 알 수 있다.
계속 여러가지 실험을 해봐야겠지만, loss를 너무 키워 outlier에 민감하게 학습하는 loss보단 loss를 적당히 키워 outlier와 inlier 모두 안정된 loss를 선택하는 것이 맞다고 생각한다.
따라서, MSE에 기반한 loss보단 MAE에 기반한 loss로 여러가지를 실험해서 test를 해보는 것이 매우 중요하다고 생각한다.
loss를 바꿔보고 여러가지 test를 해봤었는데, 아무리 생각해도 뭔가 이상했다. euler_angle에 대한 데이터들이 전혀 학습되지 않은 느낌.... 그래서 학습할 데이터 set을 다시 확인해봤다.
이런 식으로 총 75000개의 학습 데이터를 학습하는데,  list.txt의 파일 크기가 28,398KB라고...?
list.txt의 파일 크기가 28,398KB라고...?
게다가 75000개의 데이터들에 대한 정보가 있어야 하는데, 뭔가 부족한 느낌이다.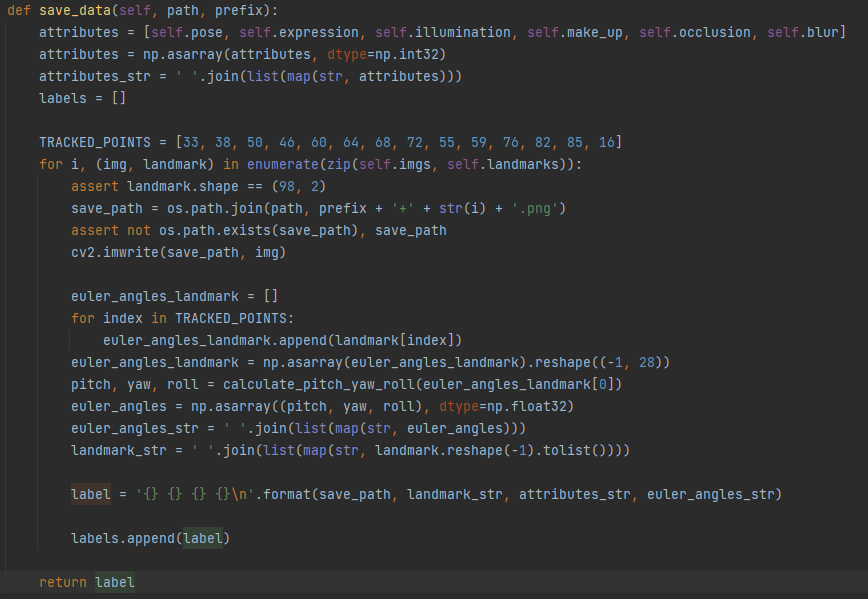
labels를 return해야 하는데, label만 return하는 문제,..............끄아아아아아아ㅏㅏㅏㅏ
이렇다 보니 증강은 해놓고 증강한 데이터들은 학습을 안하지... 에휴.. 다시 학습을 진행해보자. 이번엔 더 많은 시간이 걸릴 것 같다.
