(U-Net) Convolutional Networks for Biomedical Image Segmentation 논문 리뷰
오늘은 Segmentation에 대해 알기 위해 꼭 봐야 하는 milestone 같은 U-Net paper을 리뷰하려고 한다. 물론 FCN paper도 milestone에 속한다.
U-Net : https://arxiv.org/pdf/1505.04597.pdf
U-Net 참고 블로그 : https://joungheekim.github.io/2020/09/28/paper-review/
U-Net 구현 : https://github.com/phantomJUN/U_NET_SRC
Abstract
"we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization"
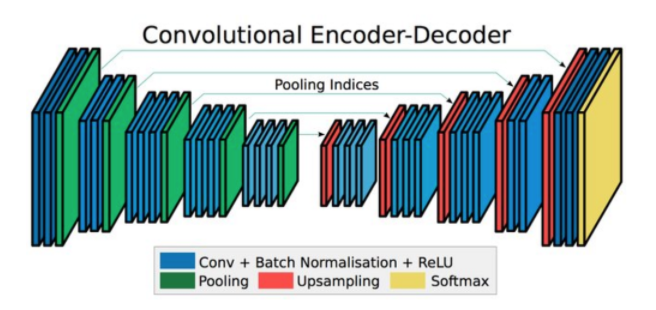
U-Net 저자들은 데이터 증가(증식)의 사용에 의존하는 네트워크와 훈련 전략을 제시한다. 또한, 그들의 architecture는 feature map을 위한 축소 경로와 정밀한 위치를 알기 위한 대칭 확장 구조로 구성된다. 즉, 이들의 architecture는 encoder과 decoder 형태로 되어 있다는 것이다.
1. Introduction & Network Architecture
1.1 Introduction
"The main idea in [9] is to supplement a usual contracting network by successive layers, where pooling operators are replaced by upsampling operators."
기존의 Convolutional Network 같은 경우에는 Classification problem만 수행을 했었다. 하지만 시간이 흘러서 수 많은 연구들이 나온 결과 Localization도 해결했다. 특히, biomedical image processing에서 Localization을 해결했다 라는 것이다. 근데, 이 조차도 문제가 있었다 라는 것!
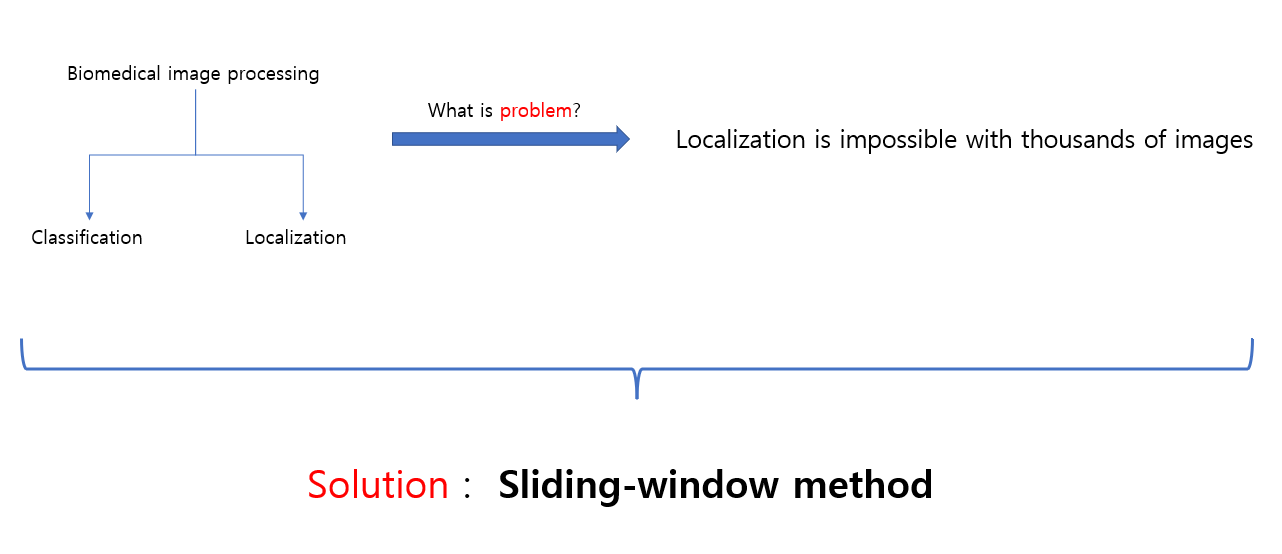 그림에서 설명이 돼있다시피, 해결책은 sliding window를 사용한 Network 였다.
그림에서 설명이 돼있다시피, 해결책은 sliding window를 사용한 Network 였다.
Solution : input에 대한 local region(patch)을 제공하여 각 pixel의 label을 예측하는 sliding-window를 설정한 Network를 사용했다.
- localize를 할 수 있다.
- train image보다 더 많은 train patch image가 필요하다.
뭐 해결을 해서 좋긴한데, 이 Network는 2가지의 단점이 있다.
1. Slow & run separately & a lot of redundancy
---> 이 Network는 느리고 각 patch들에 대해 독립적으로 동작하며, 중복(patch들이 서로 겹치는)이 많다. 각 patch들에 대해 CNN을 적용시켜야 하기 때문이다.
2. trade-off between localization accuracy & use of context
---> 큰 patch들에 대해서는 localization accuracy를 감소시키는 더 많은 max-pooling layer을 요구하고, 작은 patch들에 대해서는 대충 훑어보고 넘어가는 경우가 있다.
그래서 논문의 저자들은 이러한 문제를 해결하기 위해서 다음과 같은 architecture을 갖는 Network를 만들었다.
1.2 Network Architecture
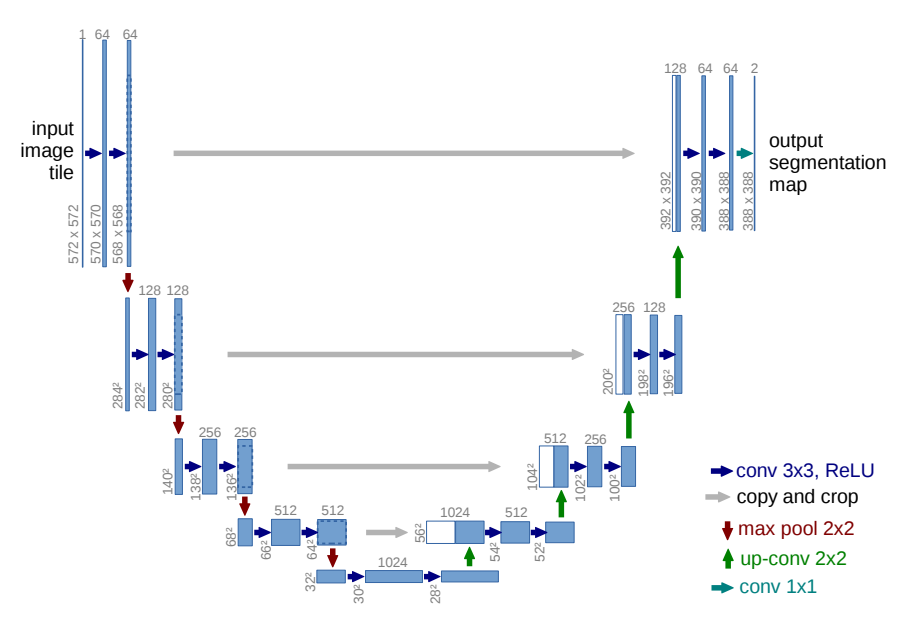
1. contracting path (수축 경로)
contracting path는 downsampling을 담당하며, convolution layer을 지날때마다 작은 feature map을 만들어 낸다.
- 3 x 3 Convolution Layer + ReLU + BatchNorm(No Padding, stride = 1)
- 3 x 3 Convolution Layer + ReLU + BatchNorm(No Padding, stride = 1)
- 2 x 2 Max-pooling Layer (stride = 2)
3 x 3 convolution으로 수행할때, downsampling이 되는 이유는 padding을 하지 않았으므로 output(feature map)은 감소한다. Downsampling을 할때마다 채널 수는 2배로 늘린다.
1 -> 64 -> 128 -> 256 -> 512 -> 1024 개로 그림을 보면 확실히 이해할 수 있다.
2. Bottle Neck (전환 구간)
contracting path에서 expanding path 구간으로 전환되는 구간이다.
- 3×3 Convolution Layer + ReLu + BatchNorm (No Padding, Stride = 1)
- 3×3 Convolution Layer + ReLu + BatchNorm (No Padding, Stride = 1)
- Dropout Layer
Dropout Layer는 모델을 generalize하고 noize에 robustness(견고하게) 만들어 준다.
3. expanding path (확장 경로)
expanding path는 upsampling을 담당하며, localization을 찾아낸다.
- 2×2 Deconvolution layer (Stride = 2)
- 수축 경로에서 동일한 Level의 Feature Map을 추출하고 크기를 맞추기 위하여 cropping 후에 이전 Layer에서 생성된 Feature Map과 Concatenation(연결)한다.
(위의 그림에서 회색 화살표를 살펴보면 된다.) - 3×3 Convolution Layer + ReLu + BatchNorm (No Padding, Stride = 1)
- 3×3 Convolution Layer + ReLu + BatchNorm (No Padding, Stride = 1)
expanding path는 connection을 통해 contracting path에서 생성된 contextual 정보와 위치 정보 결합하는 역할을 한다.동일한 Level에서 수축경로의 특징맵과 확장경로의 특징맵의 크기가 다른 이유는 여러번의 패딩이 없는 3×3 Convolution Layer를 지나면서 특징맵의 크기가 줄어들기 때문이다. 확장경로의 마지막에 Class의 갯수만큼 필터를 갖고 있는 1×1 Convolution Layer가 있다. 1×1 Convolution Layer를 통과한 후 각 픽셀이 어떤 Class에 해당하는지에 대한 정보를 나타내는 3차원(Width × Height × Class) 벡터가 생성된다.
1.3 Training
논문에서는 다양한 학습 방법을 통해서 performace를 이끌어 내고 있다.
- overlap-tile strategy : 큰 이미지를 겹치는 부분이 잇도록 일정 크기로 나누고 모델의 Input으로 활용
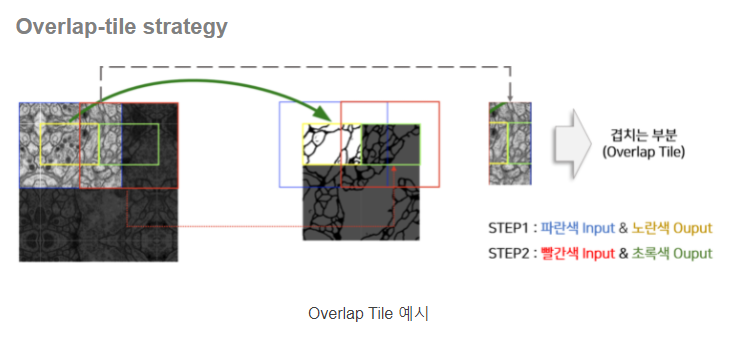 U-Net은 input과 output의 이미지가 다르기 때문에 파란색 영역을 input으로 넣으면 노란색 영역이 output으로 추출된다. 초록색 영역을 output으로 추출하기 위해선 빨간색 영역을 input으로 넣는다. 이러다 보면 겹치는 부분이 생기는데, 이 겹치는 부분이 존재하도록 이미지를 자르고 segmentation을 진행한다.
U-Net은 input과 output의 이미지가 다르기 때문에 파란색 영역을 input으로 넣으면 노란색 영역이 output으로 추출된다. 초록색 영역을 output으로 추출하기 위해선 빨간색 영역을 input으로 넣는다. 이러다 보면 겹치는 부분이 생기는데, 이 겹치는 부분이 존재하도록 이미지를 자르고 segmentation을 진행한다.
- Mirroring Extrapolate : 이미지의 경계(Border)부분을 거울이 반사된 것처럼 확장하여 Input으로 활용
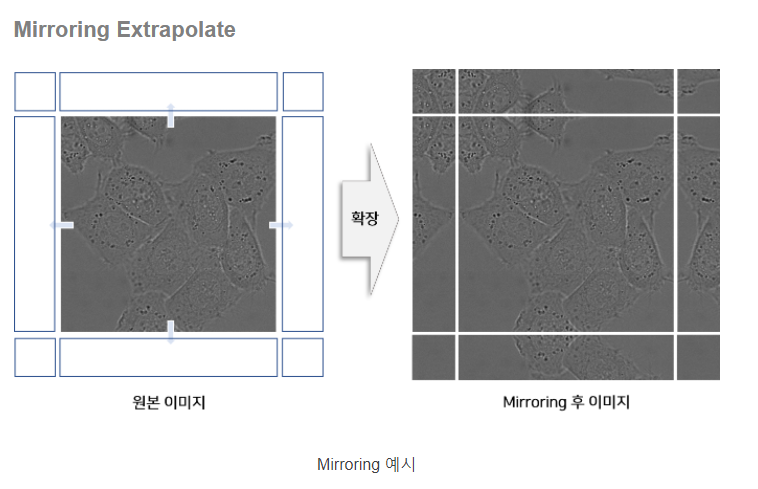 근데 이는 세포라서 가능할 것 같고 자율주행에서의 segmentation에는 그렇게 큰 도움이 되지 않을 것 같다.
근데 이는 세포라서 가능할 것 같고 자율주행에서의 segmentation에는 그렇게 큰 도움이 되지 않을 것 같다.
- weight loss : 모델이 객체간 경계를 구분할 수 있도록 Weight Loss를 구성하고 학습
 K : 전체 class의 수 , k : 해당 class를 나타낸다.
K : 전체 class의 수 , k : 해당 class를 나타낸다.
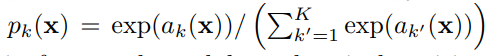 위 식은 softmax인데, ak(x) 가 maximum이라면 Pk(x) = 1에 가깝다. 그렇다면 다른 ak(x)들은 Pk(x) = 0 에 해당되어 진다.
위 식은 softmax인데, ak(x) 가 maximum이라면 Pk(x) = 1에 가깝다. 그렇다면 다른 ak(x)들은 Pk(x) = 0 에 해당되어 진다.
또한, 논문의 저자들은 momentum을 사용하였는데, 이는 학습 안정성과 속도를 높여 학습하기 위함이다. momentum이 높을 수록 과거의 weight에 영향을 많이 받아서 update를 진행한다.
Data Augmentation
의학 데이터의 양이 적기 때문에 데이터 증강을 통해 모델이 Noise에 강건하도록 학습시킨다. 데이터 증강 방법으로 Rotation(회전), Shift(이동), Elastic distortion 등이 있다. 직관적으로 Rotation과 shift는 알겠지만 Elastic distortion은 모를테니 그림으로 이해해 보도록 하자.
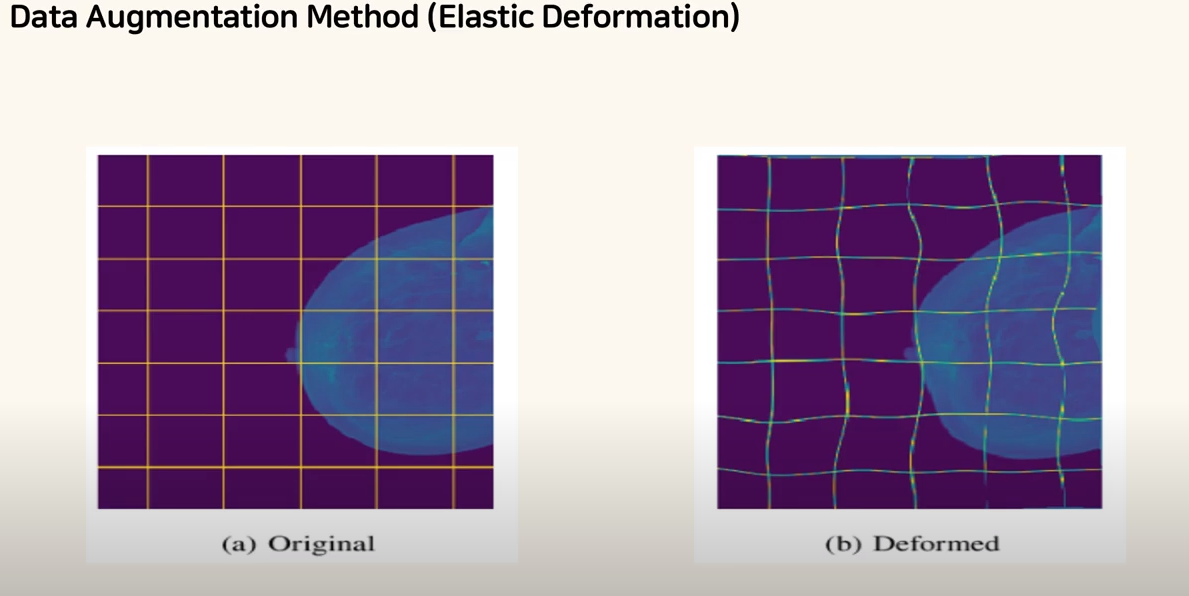 기본의 이미지에서 일부러 변형을 주어 Linear을 갖기 못하도록 만드는 것이다. 세포가 Linear할 순 없고 대부분이 deformed하므로 Elastic distortion방법을 채택한 것 같다.
기본의 이미지에서 일부러 변형을 주어 Linear을 갖기 못하도록 만드는 것이다. 세포가 Linear할 순 없고 대부분이 deformed하므로 Elastic distortion방법을 채택한 것 같다.
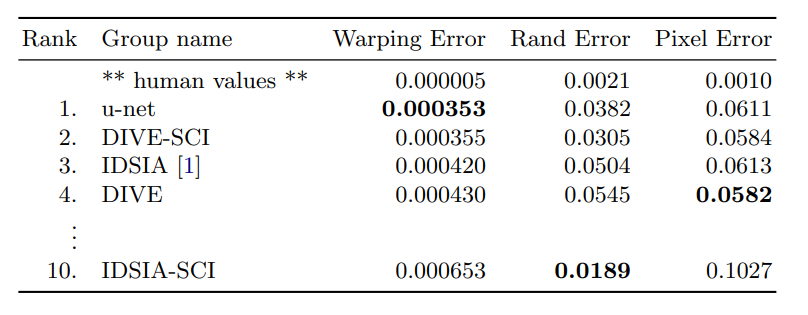
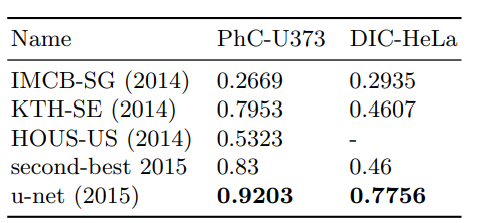
Experiments