흔히 MSE라 불리는 평균제곱오차는 다음과 같은 공식을 갖는다.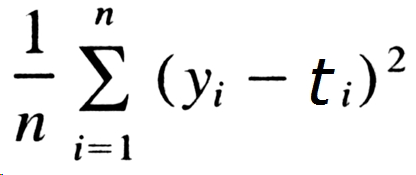
순서는 다음과 같다.
1. 각 성분에 대한 추정값과 정답 사이의 오차(차이)를 구한다.
2. 오차를 제곱한다.
3. 각 성분에 대한 오차를 모두 합한다.
4. 합한 값을 전체 성분 값으로 나눈다.
오차를 제곱하므로 절대 0 미만으로 떨어질 이유가 없다. 항상 0보다 크거나 같아야 한다. 0에 가까워 지도록 학습을 수행한다.
MSE는 loss function 혹은 cost function이라 불린다. "도대체 이게 왜 함수죠?" 라고 한다면, 신경망의 가중치에 따라 그 값이 변하기 때문이다.
예제도 없이 그냥 넘어가면 이해하기 어려울 수 있기 때문에 간단한 예제를 들어보자.
2020 한국, 중국, 일본 메달 수를 예측해보는 것이다.
준우 : 25, 65, 32
AI : 20, 80, 35
한국, 중국, 일본 순서대로 예측을 했다고 가정해보자. 누가 더 예측을 잘했을까? MSE를 사용하여 계산을 해보자.
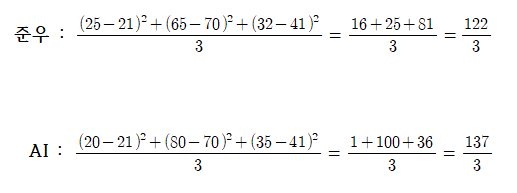
MSE를 사용하여 승자를 가린다면 준우가 승리했다. 그런데 오차 합을 따지면 준우 : 18, AI : 17이 나오게 된다. 오차 합을 MSE로 사용하면 AI가 승리하게 되는 것이다. 하지만 이런 방법은 좋지 않다. 오차 합을 사용하는 경우 미분 불가능한 지점이 있게 되고 학습 효과도 좋지 않다.

멋진 인생을 살기 위한 footprint
미분 불가능한 점이 생기면 안되는 이유가 뭔가요?