
일단 로컬 환경 기준으로 코드를 구현한 뒤 테스트를 해보자!
1. 플라스크 서버 구축
일단 내가 선정한 모델이 잘 수행 되는지 확인할 필요가 있었다.
from flask import Flask, request
from transformers import BartForConditionalGeneration, PreTrainedTokenizerFast
app = Flask(__name__)
tokenizer_kobart = None
model_kobart = None
def load_model():
global tokenizer_kobart, model_kobart
tokenizer_kobart = PreTrainedTokenizerFast.from_pretrained("ainize/kobart-news")
model_kobart = BartForConditionalGeneration.from_pretrained("ainize/kobart-news")
@app.route('/test', methods=['GET'])
def test():
text = "This is Flask Server Test"
return text
@app.route('/testSummarize', methods=['POST'])
def test_summarize():
text = request.json.get("text")
if not text:
return {"error": "No text provided for summarization"}, 400
test_summary = text
return test_summary
@app.route('/kobartSum', methods=['POST'])
def kobart_summarize():
if not tokenizer_kobart or not model_kobart:
load_model()
text = request.json.get("text")
if not text:
return {"error": "No text provided for summarization"}, 400
input_ids = tokenizer_kobart.encode(text, return_tensors='pt')
output = model_kobart.generate(input_ids, eos_token_id=1, max_length=512, num_beams=5)
summary = tokenizer_kobart.decode(output[0], skip_special_tokens=True)
return summary
if __name__ == '__main__':
app.run()
간단하게 텍스트를 요약해주는 플라스크 코드를 구현한 뒤 테스트 해보았다.
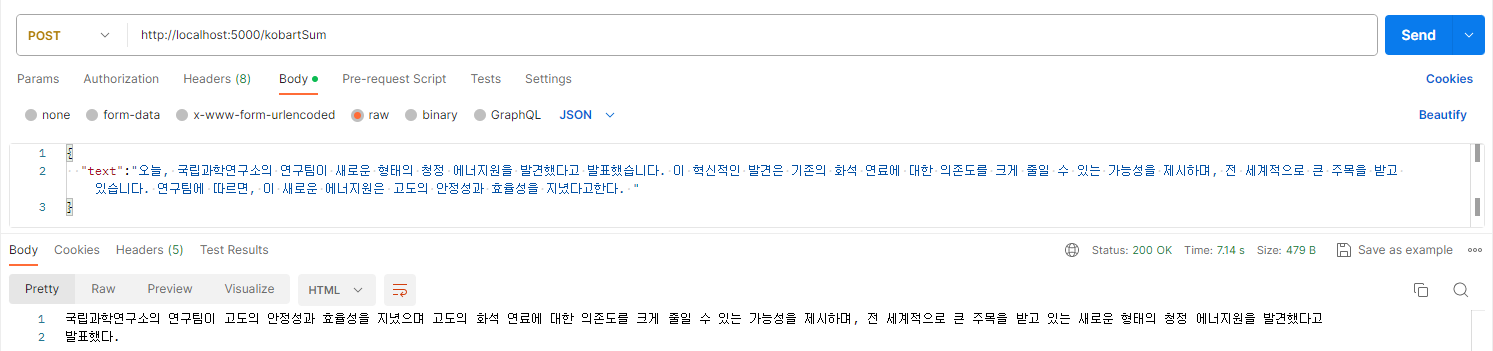
굉장히 잘 수행되는 모습을 볼 수 있다.
2. 스프링 서버 구축
사용자의 요청을 받고 플라스크 서버에 텍스트를 이용하여 요약 요청을 보내줄 스프링 서버도 구현해야한다.
중요한 부분만 기록하자면
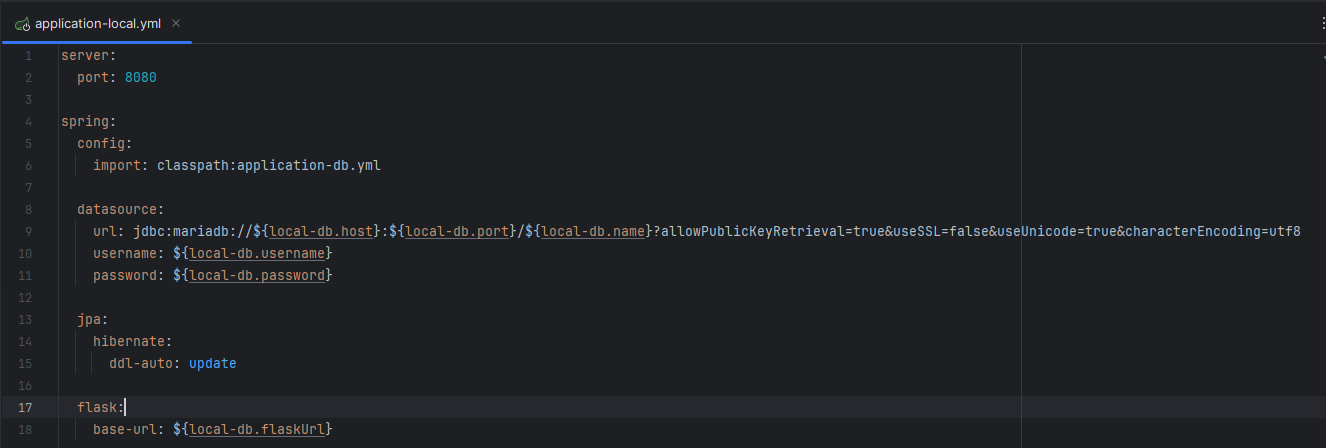
사진과 같이 로컬 환경 전용 데이터 베이스 설정 및 플라스크 URL을 설정한다.
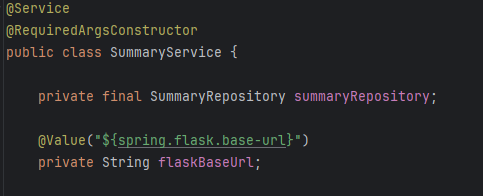
그리고 서비스 계층에서 플라스크 URL을 입력 받고
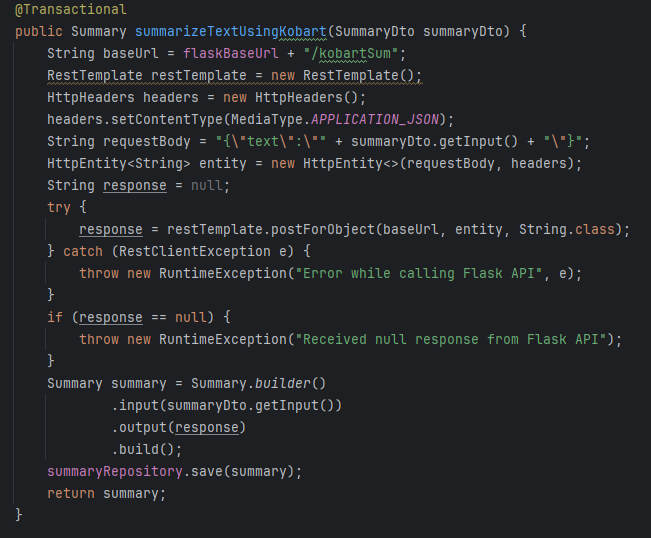
사진과 같이 플라스크 서버에 POST 요청을 보내주고 데이터 베이스 서버에 저장 해주면 된다.
이전 사진에서 서비스 계층에서 @value를 이용한 변수로 플라스크URL을 입력 받았는데, 해당 이유는 Loacal, dev, prod 실행 환경을 간편하게 구별하기 위해서이다.
해당 실행 환경 설정은 여기서 하면 된다.
다른 코드는 생략하겠다.
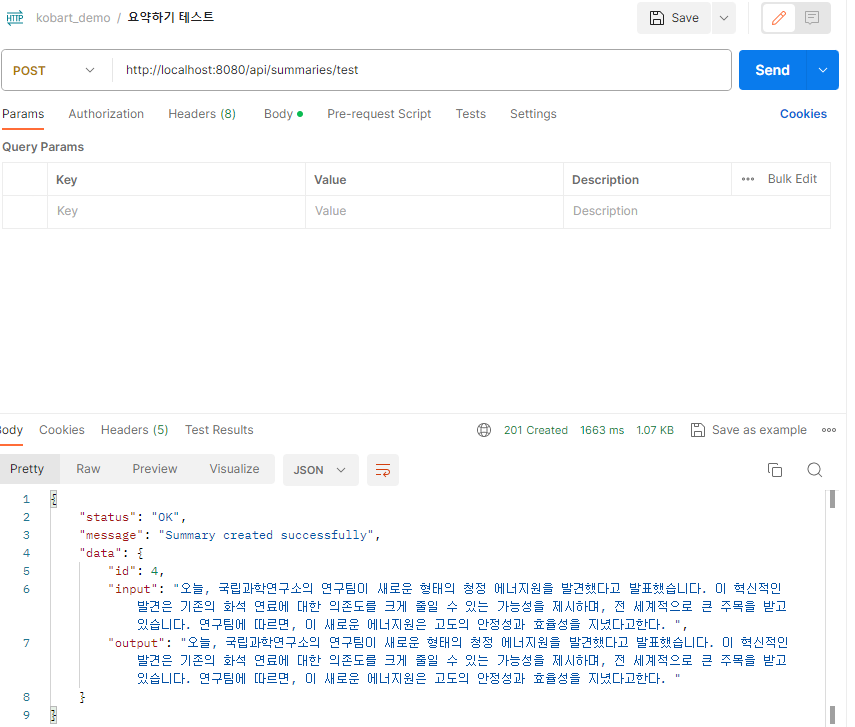
잘 실행 되는 모습이다.
다음 게시글을 도커를 사용해서 서버들을 돌려보겠다.

노를 젓다 보면 언젠가는 물이 들어오겠지.