[일단 박죠] O2O Object Detection 스프링 서버 webClient 적용에서 언급한 바와 같이, 스프링 서버와 플라스크 서버 사이의 결합을 느슨하게 만들기 위해 메시지 큐(Message Queue)를 도입하는 방안을 고려 중이다. 그러나 메시지 큐 도입이 올바른 방향인지에 대한 의문이 드는 상황이다. 그래서 이번 게시글에서 현재 구조의 문제점을 분석하고, 이 문제들을 해결하기 위해 메시지 큐를 어떻게 활용할 수 있을지에 대한 계획을 세우기로 했다.
1. 현재 구조의 문제점
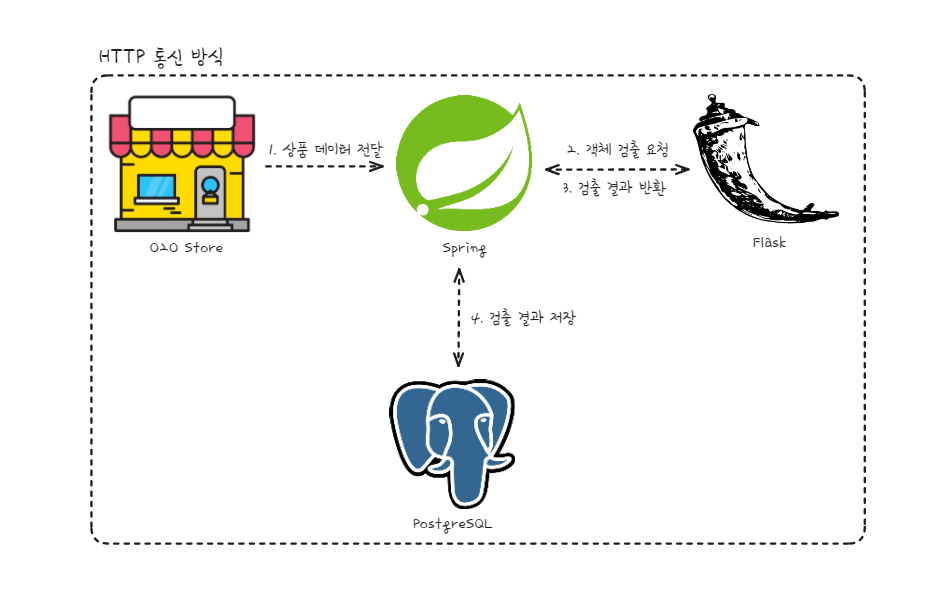
현재 구조는 스프링 서버와 플라스크 서버가 WebClient를 통해 HTTP 통신을 진행하고 있다. 이 과정에서 두 시스템 간의 의존성이 강해지며, 다음과 같은 문제점들이 발생할 수 있다
- 스프링 서버가 요청을 보내도 플라스크 서버가 이를 받지 못하는 경우, 오류가 발생할 수 있다.
- 스프링 서버로부터 요청을 받아 플라스크 서버가 처리에 성공했으나, 결과 데이터를 다시 스프링 서버로 전송하지 못해 데이터베이스에 저장되지 않는 문제가 있다. 이를 해결하기 위해 플라스크 서버 내에 데이터베이스 저장 로직을 구현할 수는 있지만, 이 경우 플라스크 전용의 별도 데이터베이스를 사용해야 하는 비용 문제가 생긴다. 또한, 스프링 서버와 동일한 데이터베이스를 사용하더라도, 두 서버가 하나의 데이터베이스에 접근하는 것은 바람직하지 않은 구조로 여겨진다.
- 플라스크 서버에서 오류 발생 시, 요청된 데이터가 유실될 수 있다. 이 경우, 해당 데이터에 대한 요청을 재전송해야 복구가 가능하다.
- 스프링 서버는 HTTP 요청을 보낸 후 응답이 도착할 때까지 기다려야 한다. 이는 동기 방식의 통신이며, 스프링 MVC에서 쓰레드가 낭비되는 상황을 초래한다.
2. 문제점의 해결 방안
2-1. 공유 데이터 베이스 사용
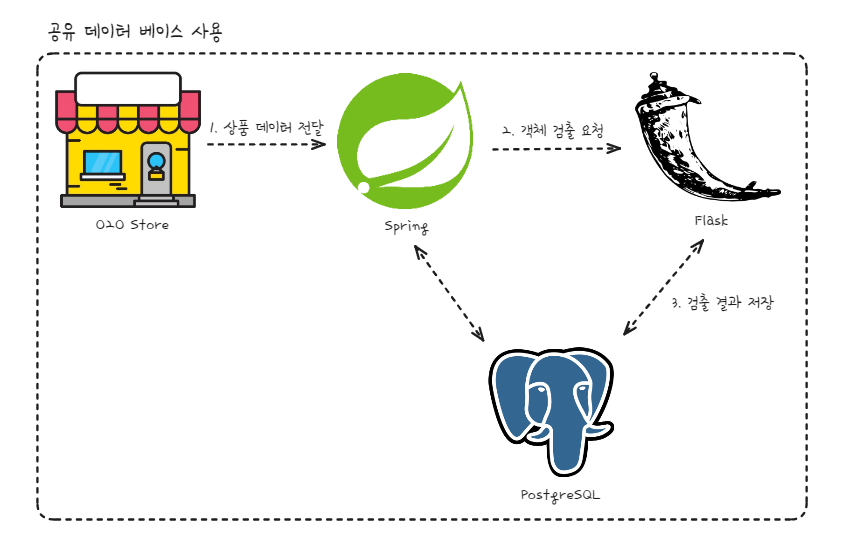
Flask와 Spring 서버가 동일한 데이터베이스를 공유함으로써 데이터 일관성과 접근성을 향상시키는 방안이다. Flask와 Spring 서버가 동일한 데이터베이스에 접근하여 데이터를 관리하고 공유한다. 각 서버는 필요 시 데이터베이스에 직접 접근하여 데이터를 읽고 쓸 수 있다.
이 접근 방식의 이점으로는 데이터 일관성 향상, 데이터 동기화 필요성 감소, 관리 용이성이 있다. 각 서버가 동일한 데이터를 직접 참조할 수 있어 데이터 일관성이 향상되고, 별도의 데이터 동기화 과정이 필요 없어 시스템 복잡성을 줄일 수 있으며, 하나의 데이터베이스를 관리함으로써 데이터베이스 관리 비용과 노력을 절감할 수 있다.
하지만 이 방법에는 리소스 경쟁과 성능 저하 가능성이라는 단점도 존재한다. 두 서버가 동일한 데이터베이스에 접근하는 경우 성능 저하나 데이터 충돌 문제가 발생할 수 있다. 또한, 데이터베이스 구조가 변경되면 이 변경이 모든 서버에 영향을 미친다. 이러한 구조는 유지 관리 작업의 복잡성을 증가시키며, 시스템의 유연성을 저하시킬 수 있다.
2-2. 메시지 큐 도입
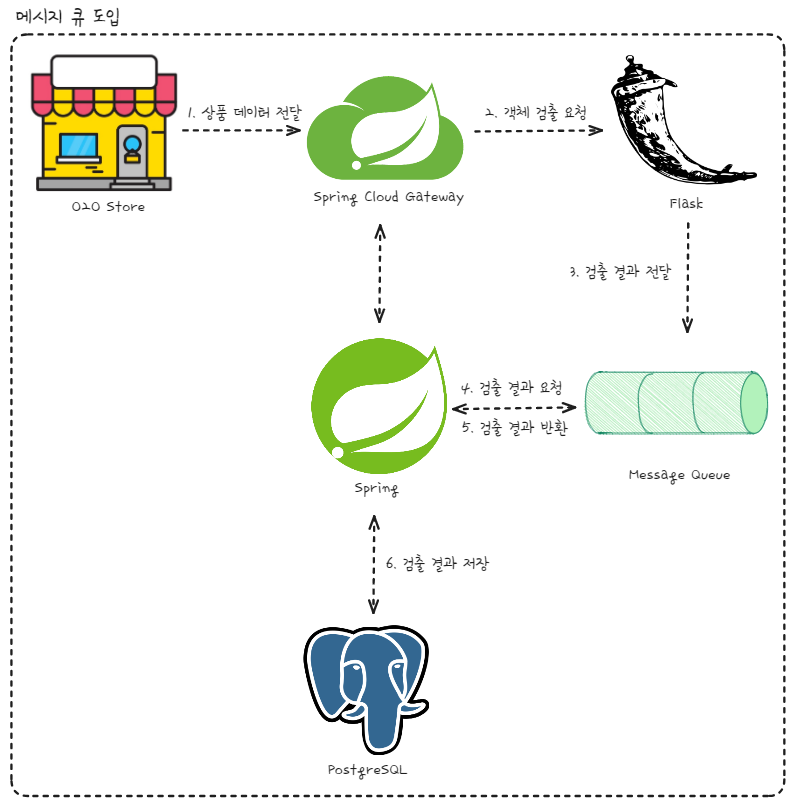
공유 데이터 베이스 사용 말고, 앞서 언급한 문제점들을 해결할 방법을 모색해보자. 이번 프로젝트의 핵심 주제인 Message Queue 도입이 이러한 문제들에 대한 해결책이 될 수 있는지 검토해볼 필요가 있다.
- 메시지 큐는 서비스 간의 결합도를 낮추는 데 큰 도움을 준다. 각 서비스는 메시지 큐를 통해 비동기적으로 메시지를 전달하므로, 한 서비스가 다운되더라도 다른 서비스의 작업에는 직접적인 영향을 미치지 않는다.
- 메시지 큐를 사용하면 메시지를 저장하고, 서비스가 준비될 때까지 메시지를 보관할 수 있다. 이는 스프링 서버와 플라스크 서버 사이의 통신에 있어서, 요청을 처리할 준비가 되지 않았을 때 데이터 유실을 방지할 수 있다는 것을 의미한다. 예를 들어, 플라스크 서버가 일시적으로 다운된 상황에서도 스프링 서버는 메시지 큐에 데이터를 보낼 수 있고, 플라스크 서버가 다시 온라인 상태가 되었을 때 메시지 큐에서 데이터를 가져와 처리할 수 있다.
- 메시지 큐는 또한 시스템 간의 통신을 비동기적으로 만들어, 요청을 보낸 후 응답을 기다리지 않아도 된다는 장점을 제공한다. 이는 특히 HTTP 통신을 사용할 때 발생하는 스프링 MVC의 쓰레드 낭비 문제를 해결하는 데 유용하다. 서비스는 메시지 큐에 작업을 전달하고, 자신의 다른 작업을 계속 진행할 수 있으므로, 시스템의 전반적인 처리량과 효율성이 향상된다.
결국, 메시지 큐의 도입은 스프링 서버와 플라스크 서버 간의 의존성 문제를 해결하고, 시스템의 안정성과 유연성을 높이며, 처리 효율성을 개선할 수 있을 것으로 생각한다.
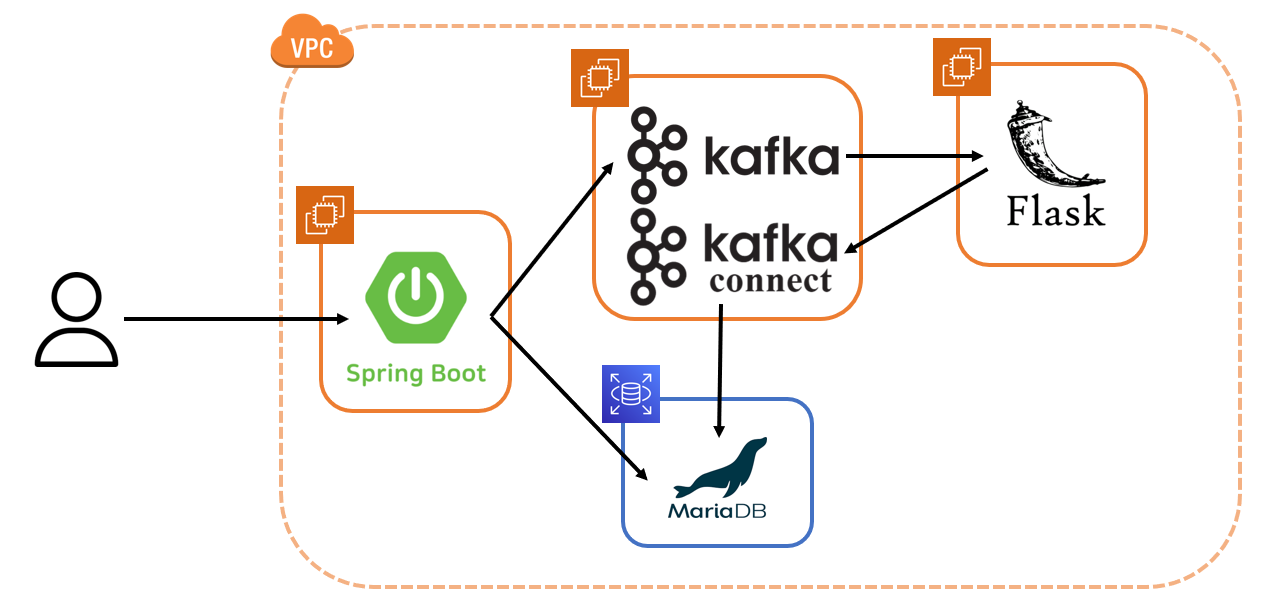
그래서 어떤 Message Queue 서비스를 선택할지 고민 중에, RabbitMQ와 Kafka 사이에서 Kafka의 도입을 생각하고 있다. Kafka를 선택하는 주된 이유는 데이터베이스와의 의존성을 줄이려는 목적 때문이다. Kafka Connect를 활용해 플라스크 서버에서 처리한 결과를 데이터베이스에 저장함으로써, 데이터베이스 저장 과정을 서버가 아닌 Kafka가 담당하게 하려 한다. 이러한 접근은 서버 각각이 본연의 역할에 집중하도록 함으로써 전체 시스템의 효율성을 높일 수 있다고 판단하고 있다.
3. 메시지 큐 도입의 단점
메시지 큐를 도입하는 것이 오직 장점만 있는 것은 아니다. 고려해야 할 몇 가지 단점이 있다
- 관리 비용이 증가할 수 있다.
- 메시지 큐 서비스에 대한 의존성이 생긴다.
- 전체 처리 속도가 느려질 가능성이 있다.
- 사용자가 요청에 대한 응답을 받는 데 어려움을 겪을 수 있다.
그러나 현재 상황에서 이러한 단점들은 O2O 프로젝트에 크게 중요한 문제가 아니라고 생각한다. O2O 프로젝트의 규모를 고려할 때, 메시지 큐를 도입해도 관리 가능한 수준이라고 본다. 또한 O2O 프로젝트의 경우, 사진을 이용한 물품 등록 같은 작업은 정해진 시간마다 자동으로 수행하는 기능이기 때문에 채팅기능과 같이, 물품 등록이 실시간으로 빠르게 업데이트 될 필요가 없으며, 등록에 대한 즉각적인 응답도 필요없다. 해당 이유 때문에 스프링 서버의 부담을 줄인 메시지 큐가 적합하다고 생각한다.
