
PanoHead
PanoHead를 활용한 아바타 자동 생성 #1에서 이미 PanoHead를 이용해서 가상 아바타 생성에 대해서 다룬적이있다. 해당 내용을 세미나때 발표하니, 교수님께서 자세히 다루어보라고 하셔서 조금 더 자세하게 다루어보려고한다.
본래 "PanoHead를 활용한 아바타 자동 생성 #1"에서는 간단하게 제공해준 데이터를 가지고 3D 모델을 출력하는 과정만 다루었다.
이제부터는 조금 더 나아가서 사진 한장을 기반으로 정보를 뽑아내고 해당 정보를 이용하여 3D 모델을 생성하는 과정을 다루어 보도록 하겠다.
실행 과정
아래는 PanoHead 폴더 아래 gen_pti_script.sh 파일의 내용이다.
PTI 과정을 이용하여, 사진을 이용하여 3D 모델을 출력하는 명령 파일이다. 참고로 나는 명령파일을 수정하였는데, --shapes True 옵션을 주어 3D 모델 파일을 출력하도록 하였다. 다른 간단한 수정들은 이해하기 쉬우니 설명을 생략하도록 하겠다.
#!/usr/bin/env bash
models=("easy-khair-180-gpc0.8-trans10-025000.pkl")
in="models"
out="pti_out"
for model in ${models[@]}
do
for i in 0
do
# perform the pti and save w
python projector_withseg.py --outdir=${out} --target_img=dataset/testdata_img --network ${in}/${model} --idx ${i} --shapes True
# generate .mp4 before finetune
python gen_videos_proj_withseg.py --output=${out}/${model}/${i}/PTI_render/pre.mp4 --latent=${out}/${model}/${i}/projected_w.npz --trunc 0.7 --network ${in}/${model} --cfg Head --shapes True
# generate .mp4 after finetune
python gen_videos_proj_withseg.py --output=${out}/${model}/${i}/PTI_render/post.mp4 --latent=${out}/${model}/${i}/projected_w.npz --trunc 0.7 --network ${out}/${model}/${i}/fintuned_generator.pkl --cfg Head --shapes True
done
done
- Projection 단계
python projector_withseg.py --outdir=${out} - target_img=dataset/testdata_img --network ${in}/${model} --idx ${i} --shapes True:타겟 이미지에 대한 latent vector를 찾고, 이를 저장한다. 여기서 --shapes True 옵션은 3D shape 정보도 함께 저장하도록 지시한다.
- Finetuning 전 비디오 생성
python gen_videos_proj_withseg.py --output=${out}/${model}/${i}/PTI_render/pre.mp4 --latent=${out}/${model}/${i}/projected_w.npz --trunc 0.7 --network ${in}/${model} --cfg Head --shapes TrueProjection 단계에서 찾은 latent vector를 사용하여 비디오를 생성하고 저장한다. 이 비디오는 finetuning 전의 결과를 보여준다.
- Finetuning 후 비디오 생성
python gen_videos_proj_withseg.py --output=${out}/${model}/${i}/PTI_render/post.mp4 --latent=${out}/${model}/${i}/projected_w.npz --trunc 0.7 --network ${out}/${model}/${i}/fintuned_generator.pkl --cfg Head --shapes TrueFinetuning 단계를 거친 모델을 사용하여 새로운 비디오를 생성하고 저장한다. 이 비디오는 finetuning 후의 결과를 보여준다.
발생한 오류
TypeError: write_frames() got an unexpected keyword argument 'audio_path'
write_frames() 함수에 'audio_path'라는 예상치 못한 키워드 인자가 전달되었다.
해결방법
/anaconda3/envs/panohead/lib/python3.9/site-packages/imageio/plugins/ffmpeg.py" 파일에 접근하여 630번째 줄에 있는 코드를 아래와 같이 수정한다.
self._write_gen = self._ffmpeg_api.write_frames(
self._filename,
self._size,
pix_fmt_in=self._pix_fmt,
pix_fmt_out=pixelformat,
fps=fps,
quality=quality,
bitrate=bitrate,
codec=codec,
macro_block_size=macro_block_size,
ffmpeg_log_level=ffmpeg_log_level,
input_params=input_params,
output_params=output_params,
# audio_path=audio_path, # 이 줄을 제거
# audio_codec=audio_codec, # 이 줄을 제거
)이렇게 하면 TypeError 오류가 해결될 것이다. 그러나 audio_path와 audio_codec 인자를 제거하면 이 인자들을 사용하려던 기능은 더 이상 작동하지 않을 것이다.
FileNotFoundError: [Errno 2] No such file or directory: 'pti_out/easy-khair-180-gpc0.8-trans10-025000.pkl/0/PTI_render/pti_out/easy-khair-180-gpc0.8-trans10-025000.pkl/0/PTI_render/post.ply'
해당 오류는 gen_videos_proj_withseg.py파일에서 본래 .mrc 파일을 생성하는 코드를 .ply로 수정했을때 발생하는 오류이다.
if output_ply:
from shape_utils import convert_sdf_samples_to_ply
convert_sdf_samples_to_ply(np.transpose(sigmas, (2, 1, 0)), [0, 0, 0], 1, os.path.join(outdirs, mp4.replace('.mp4', '.ply')), level=10)자세히 설명하자면, 경로가 중복으로 삽입되어 발생하는 문제이다. 즉, outdirs 변수에 이미 전체 경로가 저장되어 있는데, 이 경로 내에 다시 mp4 파일 경로가 삽입되어 경로가 중복되는 문제가 발생하고있다.
해결방법
이를 해결하기 위해, os.path.join(outdirs, mp4.replace('.mp4', '.ply')) 부분을 수정하여 경로 중복 문제를 해결해야 한다. 아래와 같이 수정하면 된다.
if output_ply:
from shape_utils import convert_sdf_samples_to_ply
convert_sdf_samples_to_ply(np.transpose(sigmas, (2, 1, 0)), [0, 0, 0], 1, mp4.replace('.mp4', '.ply'), level=10)결과
타겟 이미지

결과 3D 모델
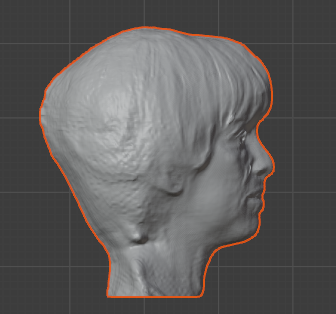
보는 것과 같이, 나름 좋은 수준의 3D 모델을 뽑아주는 모습이다.
지금까지는 PanoHead에서 제공해주는 데이터로만 이용해서 3D 모델을 뽑아내는 과정을 수행하였다. 다음 게시글에는 내가 원하는 사진을 타겟 이미지로 제시하고 해당 이미지에서 정보를 뽑아내어 3D 모델을 뽑아보도록 하겠다.
