JPA N+1 문제, 페이징과 함께 해결하기

개요
요즘 과거 프로젝트들을 하나씩 리팩토링하고 있습니다.
그중 1년 전쯤 개발했던 이력서 기반 AI 면접 및 화상 면접 서비스 ‘Interview Partner’를 다시 살펴보던 중, 배포된 운영 서버 로그에서 아래와 같은 Hibernate 경고 메시지를 발견했습니다.
HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
단순한 페이징 API 호출이었는데도, 쿼리에 LIMIT, OFFSET이 적용되지 않고 전체 데이터를 메모리에 올려 처리한다는 Hibernate 경고가 출력됐습니다. 코드를 다시 보니, 그때의 저는 “N+1 문제는 피해야 하니까” 정도의 인식만으로, 제대로 학습하지 않은 채 단순히 @EntityGraph를 적용해 문제를 해결했다고 여겼습니다.
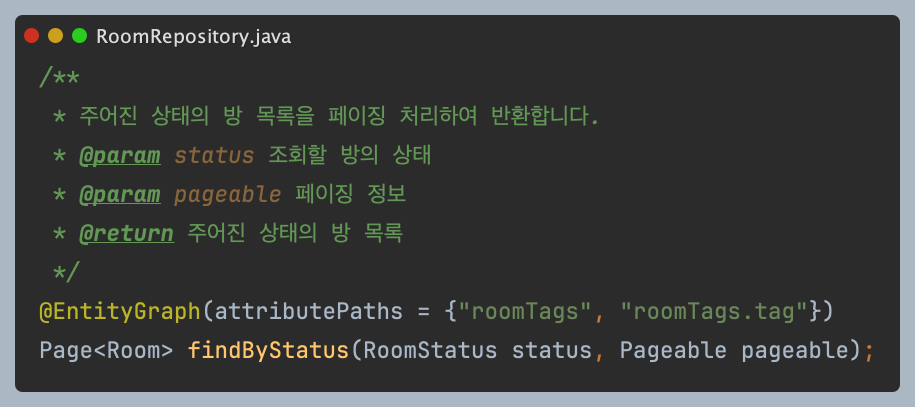
위 사진은 당시 적용했던 Repository 메서드입니다.
하지만 결과적으로 페이징은 제대로 동작하지 않았고, 모든 데이터를 메모리에 불러온 뒤 애플리케이션 레벨에서 잘라내는 비효율적인 방식으로 처리되고 있었습니다.
이는 성능 저하로 이어지고, 데이터가 많아질 경우 OOM(Out Of Memory)과 같은 심각한 문제로도 발전할 수 있습니다.
1년 전 작성한 코드를 보며, ‘그때의 선택이 정말 최선이었을까’라는 생각이 들었고, 부족했던 점에 부끄러움을 느꼈습니다.
이번 기회에 관련 내용을 제대로 학습하고, 문제가 되었던 부분을 리팩토링하게 되었습니다.
현재 테이블 구조
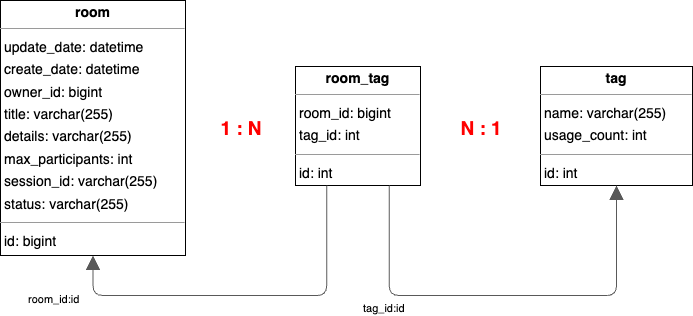
room과 tag는 다대다(N:M) 관계이며,
관계형 데이터베이스에서는 정규화된 두 테이블만으로는 다대다 관계를 표현할 수 없기 때문에,
중간 연결 테이블인 room_tag를 추가하여 이를 1:N - N:1 관계로 풀어냈습니다.
하나의 room은 여러 개의 room_tag를 가질 수 있고, 하나의 tag도 여러 room_tag에 참조될 수 있습니다.
N+1 문제
JPA를 사용하다 보면 자주 마주치는 대표적인 성능 이슈 중 하나가 바로 N+1 문제입니다.
예를 들어, 다음과 같은 코드가 있습니다.
@OneToMany(mappedBy = "room", orphanRemoval = true, cascade = CascadeType.ALL)
private List<RoomTag> roomTags = new ArrayList<>();List<Room> rooms = roomRepository.findAll(); //10개가 반환된다고 가정, 각 Room 당 RoomTag는 5개씩
for (Room room : rooms) {
for (RoomTag roomTag : room.getRoomTags()) {
log.info("roomTag.getId() = {}", roomTag.getId());
}
}❓ 이 코드는 총 몇 번의 쿼리를 실행할까요?
👉 총 11번의 쿼리가 발생합니다.
1번의 쿼리로 10개의 Room을 가져온 뒤, 각 Room의 roomTags를 조회하기 위해 각각 별도의 쿼리가 실행되기 때문입니다.
즉, 1(조회 쿼리) + 10(Room마다 roomTags 조회) = 총 11번의 쿼리가 나가게 됩니다.
이것이 바로 N+1 문제의 대표적인 예입니다.
❓ 왜 이런 문제가 발생할까요?
@OneToMany의 기본 fetch 전략은 LAZY입니다. 즉, Room 엔티티만 먼저 조회되고, roomTags 컬렉션은 프록시 객체(proxy) 로 남아 있게 됩니다. 이 프록시는 Hibernate가 실제 데이터를 즉시 로딩하지 않고, 필요한 시점에 쿼리를 날려 데이터를 가져오기 위한 일종의 ‘가짜 객체’입니다.
따라서 다음 코드에서:
for (Room room : rooms) {
for (RoomTag roomTag : room.getRoomTags()) {
log.info("roomTag.getId() = {}", roomTag.getId());
}
}- room.getRoomTags()에는 실제 데이터를 아직 로딩하지 않은 프록시 객체가 담겨져있습니다.
- 이 루프를 돌며 roomTag.getId()와 같이 프록시 내부 필드에 접근하는 순간, Hibernate는 각 Room의 RoomTag를 개별 쿼리로 조회하게 됩니다.
그 결과로 Room 조회 쿼리 1번, 각 Room의 RoomTag 조회 쿼리 10번
총 11번의 쿼리가 실행되며, 이것이 바로 대표적인 N+1 문제입니다.
❓ 그럼 fetch 전략을 EAGER로 바꾸면 되지 않나요?
EAGER는 ‘언제’ 로딩할지를 결정하는 전략일 뿐, ‘어떻게’ 로딩할지를 제어하지는 못합니다. 특히 컬렉션 연관관계에서 EAGER를 설정하면, Hibernate는 각 연관 데이터를 개별 쿼리로 불러오는 방식을 사용하기 때문에, N+1 문제는 여전히 발생할 수 있습니다. 또한 EAGER를 사용하면 모든 조회 시점에 연관 엔티티까지 항상 함께 로딩되기 때문에, 예를 들어 단순히 Room만 조회하고 싶은 상황에서도 불필요하게 RoomTag까지 함께 조회되는 문제가 발생합니다.
이 때문에 fetch 전략은 LAZY로 사용하되, 다른 방법으로 문제를 해결해야합니다.
N+1 문제 해결 방법
N+1 문제를 해결하기 위해 JPA에서는 대표적으로 아래 세 가지 방법이 있습니다:
1. Fetch Join
JPQL에서 JOIN FETCH 구문을 사용하면 연관된 엔티티를 즉시 로딩하면서도 단일 쿼리로 조회할 수 있습니다.
@Query("SELECT r FROM Room r JOIN FETCH r.roomTags")
List<Room> findAllWithRoomTags();
List<Room> rooms = roomRepository.findAllWithRoomTags();
for (Room room : rooms) {
for (RoomTag roomTag : room.getRoomTags()) {
System.out.println("roomTag.getId() = " + roomTag.getId());
}
}기존에는 Room 10개 조회 시, RoomTag를 각각 LAZY 로딩하면서 총 11개의 쿼리가 실행되었지만, Fetch Join을 사용하면 단 1개의 쿼리로 모든 데이터를 불러올 수 있습니다.
아래는 실제 실행되는 SQL 예시입니다.
select
r1_0.id,
r1_0.create_date,
r1_0.details,
r1_0.max_participants,
r1_0.owner_id,
rt1_0.room_id,
rt1_0.id,
rt1_0.tag_id,
r1_0.session_id,
r1_0.status,
r1_0.title,
r1_0.update_date
from
room r1_0
join
room_tag rt1_0
on r1_0.id=rt1_0.room_idJOIN FETCH는 내부적으로 INNER JOIN으로 번역되며, 연관 엔티티를 함께 조회하므로 N+1 문제를 해결할 수 있습니다.
List<Room> rooms = roomRepository.findAllWithRoomTags();
System.out.println("Room 갯수 = " + rooms.size());select
count(r1_0.id)
from
room r1_0
join
room_tag rt1_0
on r1_0.id = rt1_0.room_id;이 둘의 결과는 같을까요?
❗ 아니요, 두 결과는 다릅니다.
- 실제 SQL 쿼리를 실행하면 50개가 조회됩니다.
- 하지만 자바 코드에서 rooms.size()를 출력하면 10개만 나옵니다.
왜 그럴까요?
SQL 쿼리는 조인 결과의 row 수를 모두 세기 때문에, Room 하나에 여러 RoomTag가 있다면 그만큼 중복된 Room ID가 포함되어 row 수가 많아집니다.
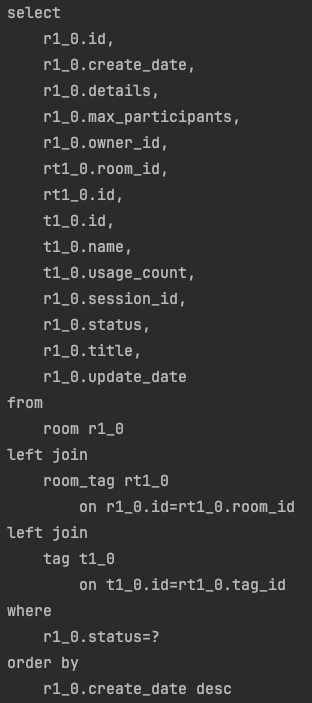
이를 해결하기 위해 Hibernate 6 이전 버전에서는 중복 제거를 위해 distinct 키워드를 사용해야 했습니다.
@Query("SELECT DISTINCT r FROM Room r JOIN FETCH r.roomTags")
List<Room> findAllWithRoomTags();그러나 Hibernate 6부터는 아래처럼 중복된 엔티티를 메모리에서 제거해 주므로 distinct 없이도 안전하게 사용할 수 있습니다.

https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html#hql-distinct
2. @EntityGraph
JPA는 연관 엔티티를 로딩할 때 @EntityGraph라는 어노테이션을 통해 Fetch 전략을 설정할 수 있습니다.
이를 사용하면 JPQL을 별도로 작성하지 않아도 연관 엔티티를 함께 로딩할 수 있습니다.
// 1. JPQL 명시적 사용 (복잡한 쿼리 시)
@EntityGraph(attributePaths = {"roomTags"})
@Query("SELECT r FROM Room r")
List<Room> findAllWithRoomTags();
//2. 메서드 이름 기반 사용 (간단할 때)
@EntityGraph(attributePaths = {"roomTags"})
List<Room> findAll();위와 둘 중 하나를 선택해서 실행하면 아래와 같은 쿼리가 나갑니다.
select
r1_0.id,
r1_0.create_date,
r1_0.details,
r1_0.max_participants,
r1_0.owner_id,
rt1_0.room_id,
rt1_0.id,
rt1_0.tag_id,
r1_0.session_id,
r1_0.status,
r1_0.title,
r1_0.update_date
from
room r1_0
left join
room_tag rt1_0
on r1_0.id=rt1_0.room_id- @EntityGraph는 기본적으로 LEFT OUTER JOIN 방식으로 작동합니다. 즉, Room은 존재하지만 연관된 RoomTag가 없더라도 해당 Room은 결과에 포함됩니다.
Room은 있는데, RoomTag가 없으면 해당 필드들은 NULL로 채워집니다.

- 반면, Fetch Join은 기본적으로 INNER JOIN 방식으로 작동합니다. 따라서 Room과 연관된 RoomTag가 존재하지 않으면 해당 Room은 결과에서 제외됩니다.
EntityGraph도 Fetch Join과 마찬가지로 따로 Distinct을 하지 않아도 중복된 엔티티를 내부에서 Set으로 처리해서 제거해 줍니다.
https://stackoverflow.com/questions/70988649/why-does-not-entitygraph-annotation-in-jpa-need-to-use-distinct-keyword-or-s/73348400#73348400
Fetch Join과 @EntityGraph의 공통 한계: 페이징 쿼리와 같이 사용 ❌
결론부터 말하면, Fetch Join과 @EntityGraph는 페이징 쿼리와 함께 사용할 수 없습니다.
바로 이 부분이 제가 작년에 작성한 코드의 핵심적인 문제점이었습니다.
문제가 발생하는 이유
- 두 방법 모두 데카르트 곱(Cartesian Product) 방식으로 SQL 결과를 반환합니다.
- 이후 중복된 엔티티를 Hibernate가 메모리에서 제거 하기 때문에, 이로 인해 LIMIT과 OFFSET이 적용되지 않고, 모든 데이터를 먼저 조회한 뒤 메모리에서 페이징을 수행하게 됩니다.
@Query("SELECT r FROM Room r JOIN FETCH r.roomTags")
Page<Room> findAllWithRoomTags(Pageable pageable); // fetch join 잘못된 사용
@EntityGraph(attributePaths = {"roomTags"})
@Query("SELECT r FROM Room r")
Page<Room> findAllWithRoomTags(Pageable pageable); // EntityGraph 잘못된 사용- 이를 사용하면 Hibernate는 아래와 같은 경고를 출력합니다.
WARN: HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory - 즉, 페이징 처리가 데이터베이스가 아닌 애플리케이션 메모리에서 수행되며, 모든 결과를 가져온 후 메모리에서 수행한다는 의미입니다.
이는 전체 결과를 메모리로 가져오기 때문에, 데이터일 대량일 경우 OutOfMemory(OOM) 위험이 존재합니다.
https://vladmihalcea.com/join-fetch-pagination-spring/?utm_source=chatgpt.com
예방 방법
application.yml 또는 application.properties에 다음 설정을 추가하면 됩니다.
로컬에서 개발 시 해당 옵션을 켜고 개발을 하면, 메모리 페이징 시 경고가 아닌 에러를 발생시킵니다.
이때문에 사전에 인지할 수 있습니다.
spring:
jpa:
properties:
hibernate:
query:
fail_on_pagination_over_collection_fetch: trueorg.springframework.orm.jpa.JpaSystemException:
setFirstResult() or setMaxResults() specified with collection fetch join
(in-memory pagination was about to be applied, but 'hibernate.query.fail_on_pagination_over_collection_fetch' is enabled)참고 링크: Join fetch and pagination in Spring (vladmihalcea.com)
- 페이징이 필요 없는 경우에는 Fetch Join 또는 @EntityGraph를 자유롭게 사용할 수 있습니다.
- 하지만 페이징이 필요한 경우, 이 방식들은 적절하지 않으며, 대신 Batch Size을 사용하는 것이 좋습니다.
3. Batch Size 방식
- Batch Size는 연관 컬렉션을 지연 로딩(LAZY) 하면서도, 한 번에 일정량씩 묶어서 로딩하도록 설정하는 방식입니다.
- 즉, Room을 먼저 페이징 쿼리로 조회한 후, 그와 연관된 RoomTag들을 설정한 Batch Size만큼 묶어서 데이터베이스 in 절로 한 번에 가져옵니다.
- 지연 로딩 성능 최적화를 위해
hibernate.default_batch_fetch_size,@BatchSize를 적용합니다.- hibernate.default_batch_fetch_size: 글로벌 설정
- @BatchSize: 개별 최적화
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회
글로벌
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100개별로 설정하려면 @BatchSize 를 적용하면 됩니다. (컬렉션은 컬렉션 필드에, 엔티티는 엔티티 클래스에 적용)
- 1차 쿼리: 페이징 처리된 Room만 먼저 조회
- 2차 쿼리: 지연 로딩(LAZY) 설정된 연관 엔티티 RoomTag를 가져오기 위해 추가 쿼리 실행
- 이때 Batch Size 단위로 묶어서 IN 쿼리를 보냅니다.
default_batch_fetch_size는 100~1000 사이가 적절하며, 1000이 가장 성능이 좋지만,
데이터베이스의 IN 절 한계나 DB 순간 부하를 고려해 선택해야 합니다.
메모리 사용량은 동일하므로, 결국 DB와 애플리케이션의 감당 가능 수준에 따라 결정하면 됩니다.
결론
기존에는 @EntityGraph를 사용하면서 페이징 처리를 함께 적용해 N+1 문제를 해결하려고 했지만, 내부적으로는 Hibernate가 메모리에서 페이징을 처리하기 때문에 성능 문제가 발생했습니다.
이에 따라, 저는 @EntityGraph를 제거하고 Batch Size 설정 방식으로 리팩토링하여 정상적인 페이징 처리와 함께 N+1 문제도 해결할 수 있도록 개선하였습니다. 또한, 로컬 개발 환경에서는 fail_on_pagination_over_collection_fetch 설정을 활성화하여 실수로 컬렉션 Fetch Join과 페이징을 함께 사용하는 잘못된 쿼리가 실행되지 않도록 예방하였습니다.
회고
어떤 기술이나 라이브러리를 사용할 때 단순히 기능 구현만을 목적으로 사용하는 것이 아니라, 내부 동작 원리에 대한 이해가 반드시 필요하다는 것을 이번 경험을 통해 느꼈습니다. 겉으로 보기엔 잘 동작하는 것처럼 보여도, 내부에서 어떻게 처리되는지를 모르고 사용하면 예상치 못한 성능 문제나 장애로 이어질 수 있다는 것을 직접 겪으며 깨달았습니다.
또한 이번 계기로 N+1 문제에 대해 보다 근본적인 원인과 해결 방식(Batch Size 설정, DTO 조회 방식, Fetch 전략 등)을 학습하고 적용하는 계기가 되었고, 성능을 고려한 개발의 중요성을 체감하게 되었습니다.
