MySQL에 대용량 데이터를 삽입해야 할 일이 발생했습니다.
기존에 JPA를 사용하여 데이터를 저장하는 메서드인 Save()와 SaveAll()의 차이에 대해서 알아보고 위 2가지의 단건 삽입과 반대대는 Bulk 삽입의 차이에 대해서 알아보겠습니다.
그래서 Save() vs SaveAll() vs Bulk Insert
총 3가지 경우를 알아보고 특징과 성능 차이에 대해서 알아보겠습니다.
위 3가지 경우는 모두 10만건의 데이터를 기준으로 비교했습니다.
Save()
@Test
@DisplayName("글 등록하기 Save")
public void createPostOneTest(){
long startTime = System.currentTimeMillis();
for (int i =1; i< 100000; i++){
Post post = Post.builder()
.postTitle("title title title"+i)
.postContent("content content content"+i+1)
.build();
postRepository.save(post);
}
System.out.println("taken time = "+(System.currentTimeMillis() - startTime)+"ms");
}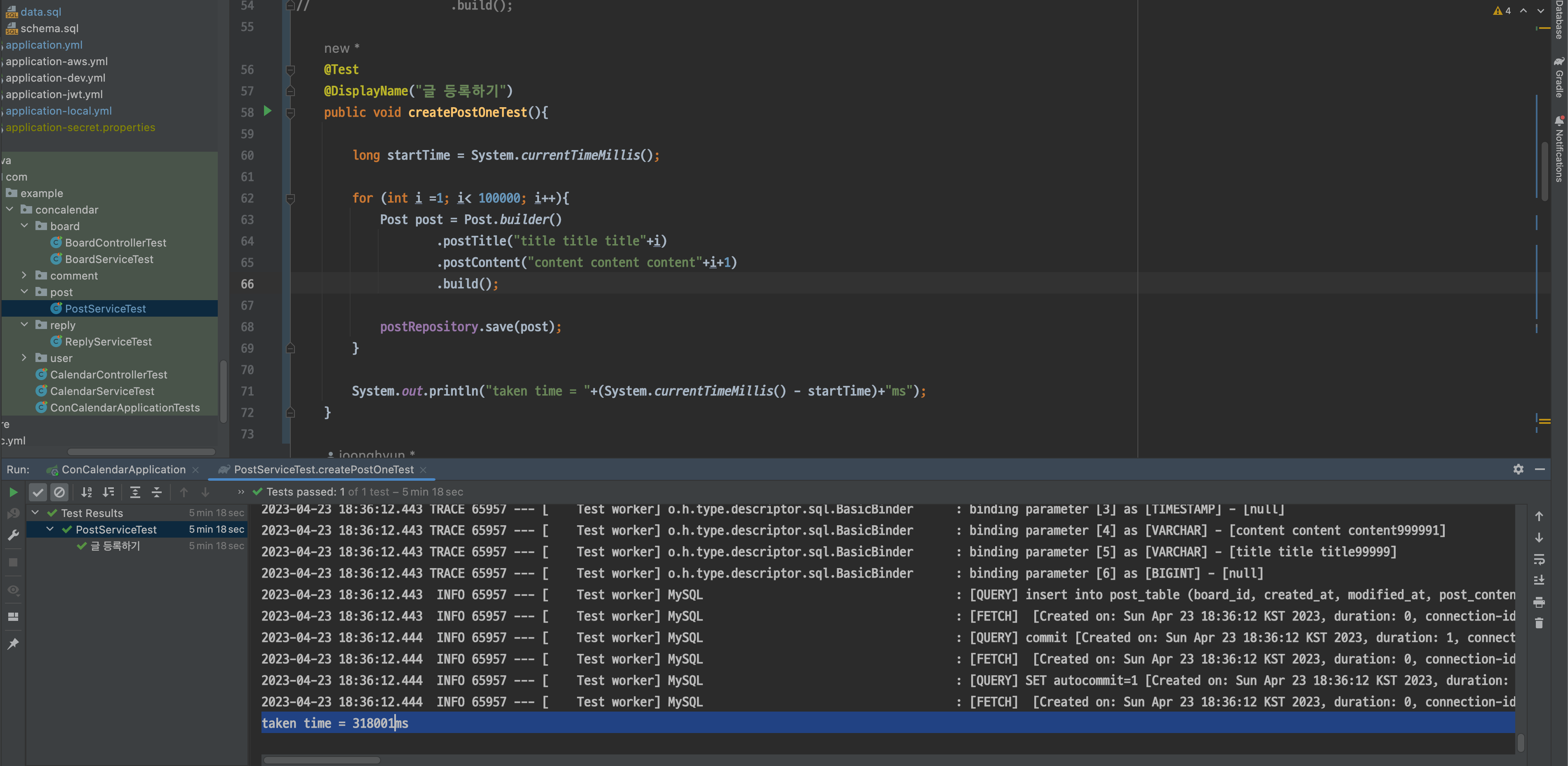
save() 메서드를 사용했을 때는 310081ms의 긴 시간이 사용됐습니다.
save() 메서드의 특징은 @Transactional 로 감싸져 있어 프록시 기반 동작을 합니다. 때문에 10만번동안 save() 메서드가 호출될 때 불필요한 프록시 과정이 발생할 수 있습니다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}따라서, 대용량 데이터를 삽입할 때는 효과적인 방법은 아닙니다.
SaveAll()
@Test
@DisplayName("글 등록하기")
public void createPostTest(){
long startTime = System.currentTimeMillis();
List<Post> list = new ArrayList<>();
for (int i =1; i< 100000; i++){
Post post = Post.builder()
.postTitle("title title title"+i)
.postContent("content content content"+i+1)
.build();
list.add(post);
}
postRepository.saveAll(list);
System.out.println("taken time = "+(System.currentTimeMillis() - startTime)+"ms");
}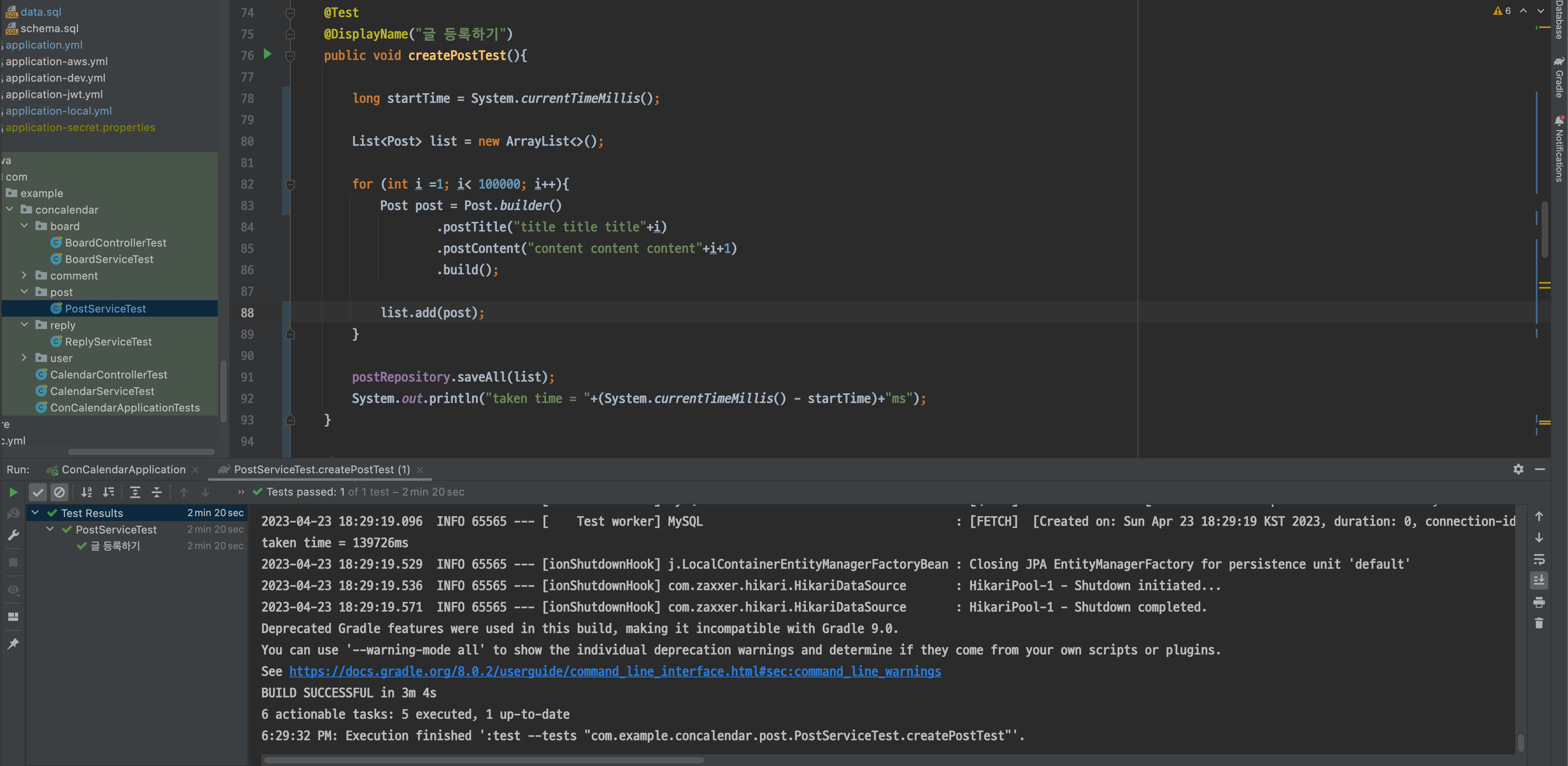
saveAll() 메서드를 사용했을 때는 139726ms의 시간이 소요됐습니다. 확실히 save() 메서드를 사용했을 때 보다 약 2배 이상 시간이 절약됐습니다.
saveAll() 메서드가 save() 메서드 보다 효율적인 결과가 나온 이유는 무엇일까요?
saveAll()의 특징에 정답이 있습니다.
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}saveAll()은 save()와 다르게 한 번의 트랜잭션을 생성하고, save()를 여러 번 호출하여 같은 인스턴스에서 내부 호출을 하기 때문에 프록시 로직을 타지 않게 됩니다.
따라서 다건의 데이터를 insert할 때는 save() 보다는 saveAll()이 훨씬 효과적이라는 것을 알 수 있습니다.
Bulk Insert
그렇다면 Bulk 삽입을 사용해야 하는 이유는 무엇일까요??
먼저 단건 삽입과, Bulk 삽입의 차이에 대해서 알아봐야 합니다.
단건 삽입
insert into post_table (post_title, post_content) values (title1, content1)
insert into post_table (post_title, post_content) values (title2, content2)
insert into post_table (post_title, post_content) values (title3, content3)
insert into post_table (post_title, post_content) values (title4, content4)Bulk 삽입
insert into post_table (post_title, post_content)
values
(title1, content1),
(title2, content2),
(title3, content3),
(title4, content4)이렇게 여러 건의 삽입을 할 때 여러 개의 쿼리가 나가는게 단건 삽입, 하나의 쿼리로 나가는게 Bulk 삽입입니다.
쿼리를 던지고 응답을 받은 뒤 다음 쿼리를 전달하기 때문에 Insert의 경우에는 지연이 많이 발생하지만 하나의 트랜잭션으로 묶이는 Batch Insert는 하나의 쿼리문으로 수행하기 때문에 성능이 훨씬 좋습니다.
save()와 saveAll()은 모두 단건 삽입에 해당합니다.
따라서 이 2가지 메서드가 아닌 Bulk Insert를 사용해보겠습니다.
JPA와 MySQL을 사용하는 경우에는 일반적으로 IDENTITY 전략으로 PK 값을 자동으로 증가시켜 생성하는 방식을 사용합니다.
하지만, 이 IDENTITY 방식 때문에 Batch Insert를 JPA에서 사용할 수 없습니다. 이유는 DB에 Insert가 되어야 id 값을 알 수 있다는 JPA의 쓰기지연 특성 때문입니다. 이 특징은 Id 값을 알아야하는 Batch 특성과 충돌하게 됩니다.
그러면 기본키의 전략을 바꾸면 되지 않을까라고 생각도 했지만 이 경우에는 테이블의 구조를 또 변경해야 하는 번거로움이 있습니다.
저는 Spring JDBC를 이용하여 Batch Insert를 실행할 수 있었습니다.
JdbcTemplate에는 Batch를 지원하는 batchUpdate() 메서드를 지원합니다.
application.yml의 MySQL에 Bulk Insert를 사용하기 위해 DB-URL에 아래와 같이 rewriteBatchedStatements=true 파라미터를 추가해야 합니다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/batch_test?&rewriteBatchedStatements=true
username: root
password: 1234
driver-class-name: com.mysql.cj.jdbc.DriverrewriteBatchedStatements를 true로 설정해야만 Insert 쿼리가 단건이 아닌 Bulk로 수행이 됩니다.
Batch Insert가 정확하게 나가는지 확인하고 싶으면 url에 옵션을 추가해주면 됩니다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/db명?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999postfileSQL = true: Driver에 전송하는 쿼리를 출력합니다.logger=Slf4JLogger: Driver에서 쿼리 출력 시 사용할 로거를 설정합니다.
- MySQL 드라이버 : 기본값은 System.err로 출력하도록 설정되어 있기 때문에 필수로 지정해 줘야 합니다.
- MariaDB 드라이버 : Slf4j 를 이용하여 로그를 출력하기 때문에 설정할 필요가 없습니다.maxQuerySizeToLog=999999: 출력할 쿼리 길이
- MySQL 드라이버 : 기본값이 0으로 지정되어 있어 값을 설정하지 않을 경우 아래처럼 쿼리가 출력되지 않습니다.
- MariaDB 드라이버 : 기본값이 1024로 지정되어 있습니다. MySQL 드라이버와는 달리 0으로 지정 시 쿼리의 글자 제한이 무제한으로 설정됩니다.
저는 BulkRepository를 하나 만들어서 Bulk 메서드를 입력했습니다.
@Repository
@RequiredArgsConstructor
public class PostBulkRepository {
private final JdbcTemplate jdbcTemplate;
@Transactional
public void saveAll(List<Post> postList){
String sql = "INSERT INTO post_table (post_title, post_content)"+
"VALUES (?, ?)";
jdbcTemplate.batchUpdate(sql,
postList,
postList.size(),
(PreparedStatement ps, Post post) -> {
ps.setString(1, post.getPostTitle());
ps.setString(2, post.getPostContent());
});
}
}
그리고 테스트코드는 아래와 같이 작성했습니다.
@Test
@DisplayName("글 벌크 등록하기")
public void createPostBulkTest(){
long startTime = System.currentTimeMillis();
List<Post> list1 = new ArrayList<>();
for (int i =1; i< 100000; i++){
Post post = Post.builder()
.postTitle("title title title"+i)
.postContent("content content content"+i+1)
.build();
list1.add(post);
}
postBulkRepository.saveAll(list1);
System.out.println("taken time = "+(System.currentTimeMillis() - startTime)+"ms");
}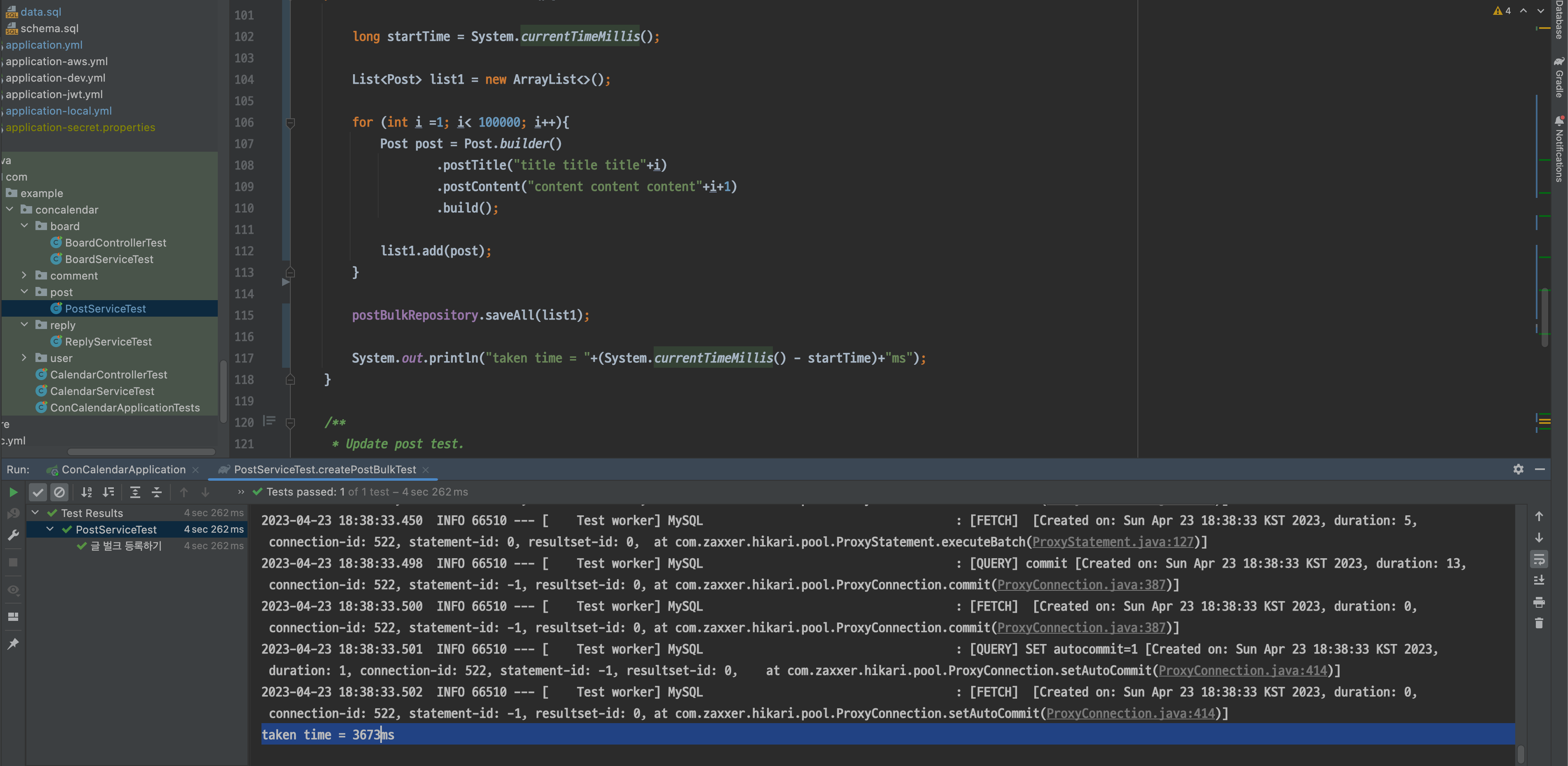
3673ms의 시간이 소요됐는데 시간이 굉장히 많이 절약된것을 확인할 수 있습니다. save() 메서드에 비해 시간 차이가 약 86배 정도로 꽤나 많은 효과를 볼 수 있습니다.
이 비교 연구를 바탕으로 대규모 데이터를 삽입해야 할 경우에는 JPA를 사용하기 보다는 Bulk Insert를 사용하는 것이 훨씬 좋다는 것을 배우게 됐습니다.
참고
https://dkswnkk.tistory.com/682
https://velog.io/@ssuh0o0/Spring-JPA%EC%97%90%EC%84%9C-save%EC%99%80-saveAll-%EB%B9%84%EA%B5%90

오 JPA가 무조건 좋지만은 않군요??
실제 초 단위로 비교해보니 흥미롭네요