자바에서 크롤링을 할 때 주로 많이 사용되는 라이브러리는 Jsoup입니다.
하지만, Jsoup의 가장 큰 단점은 동적 웹페이지를 크롤링하지 못한다는 점입니다.
Jsoup는 HTTP Request를 던져서 웹 서버에서 응답 결과를 받아옵니다. 서버 사이드 랜더링을 사용하는 웹 사이트에서는 서버에서 랜더링을 한 후 화면을 그리기 때문에 크롤링이 가능하지만, 클라이언트 사이드 랜더링을 사용하는 웹 사이트는 최소한의 페이지만 서버에서 랜더링하고 클라이언트에서 나머지 화면을 랜더링하기 때문에 HTTP Request로는 실제 브라우저에서 보여지는 화면을 스크랩할 수 없습니다.
반대로 Selenium은 브라우저 드라이버를 사용하기 때문에 현재 브라우저에서 사용하는 페이지 소스를 파싱할 수 있기 때문에 CSR을 사용하는 웹 사이트도 크롤링이 가능합니다.
Selenium은 파이썬으로 사용하시는 분들이 많지만 자바에서도 사용이 가능합니다.
크롬 드라이버 설치
https://chromedriver.chromium.org/downloads
웹 드라이버 for Chrome을 다운 받습니다.
의존성 추가
그리고 build.gradle에 해당 의존성을 추가해줍니다.
implementation 'org.seleniumhq.selenium:selenium-java:4.1.2' ## 크롤링 로직 설계
서비스 단에서 크롤링 로직을 설계해주면 됩니다.
원하는 크롤링 url을 미리 준비하고 선언해줍니다.
그리고 System에 프로퍼티 설정을 해줘서 webdriver(Chrome)을 사용할 수 있도록 해줍니다.
String url = "http://ticket.interpark.com/TPGoodsList.asp?Ca=Liv&SubCa=For&tid4=For";
// 시스템에 프로퍼티 설정
System.setProperty("webdriver.chrome.driver", "/Users/joonghyun/Downloads/chromedriver_mac64/chromedriver");
webDriver = new ChromeDriver(); // 크롬 드라이버 사용
webDriver.get(url); // 해당 url로 접속그리고 나서 HTML 태그의 선택자를 통해서 어떤 데이터를 가져올 지 생각하면 됩니다.
예를 들어, webDriver.findElements(By.cssSelector("td .fw_bod a");
라고 한다면, td 태그 안 fw_bod 클래스를 가진 태그 안 a 태그의 데이터를 가져온다는 뜻입니다
참고로, WebDriver의 findElements 메소드는 리스트 형태의 데이터를 가져올 때 사용합니다.
저 같은 경우에는 아래 리스트의 아이템에 각각 접속해서 해당 페이지 내 데이터를 크롤링하는 로직을 설계했습니다.
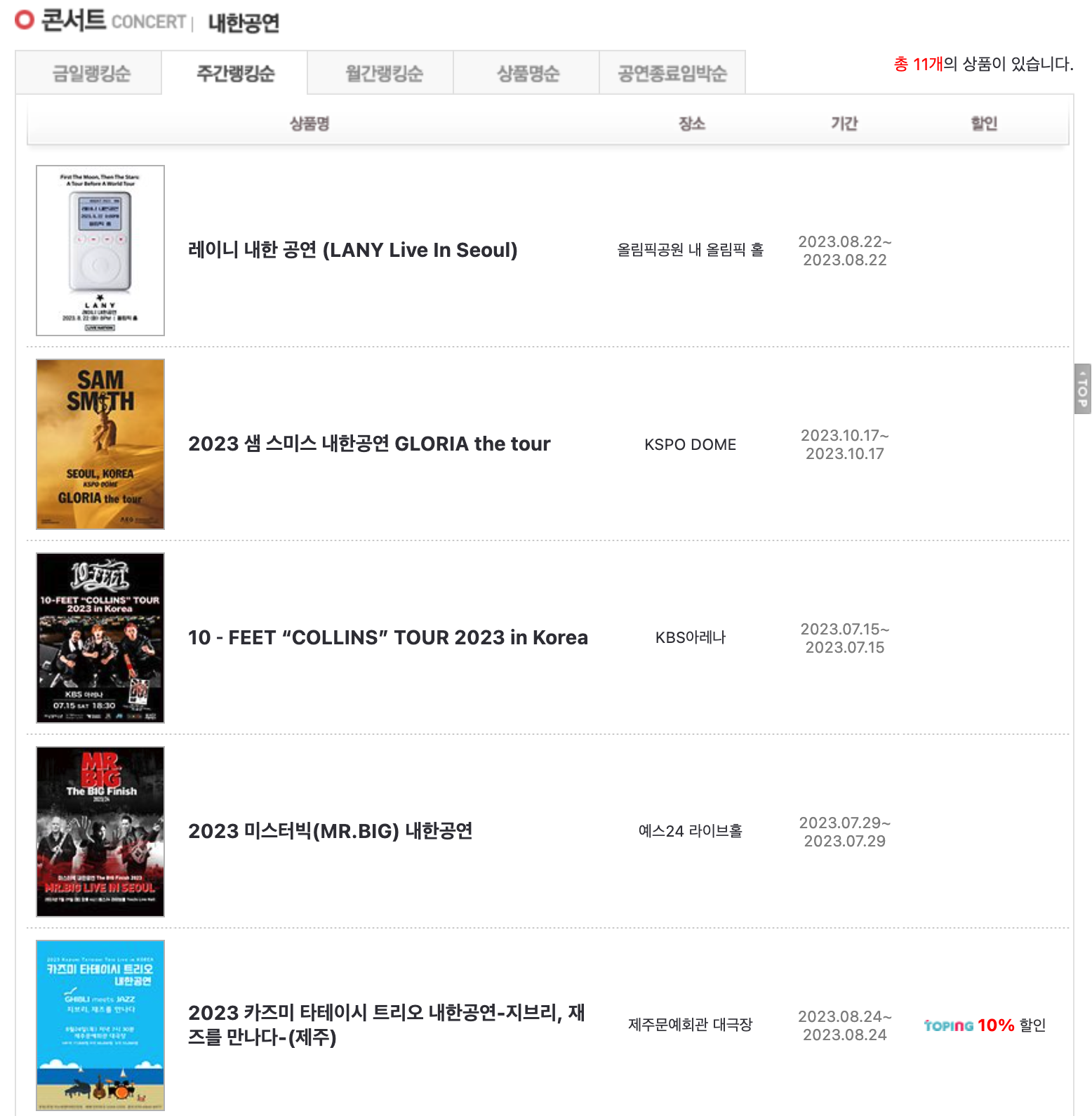
리스트의 아이템에 접속

하지만 위 로직에는 2가지 문제점이 발생했습니다.
- 아이템 별로 표시되는 정보가 달랐습니다. -> NoSuchElementException 발생
예를 들어, 같은 사이트에서도 어떤 공연 페이지에는 캐스팅 정보가 있고 어떤 페이지에는 캐스팅 정보가 없습니다.

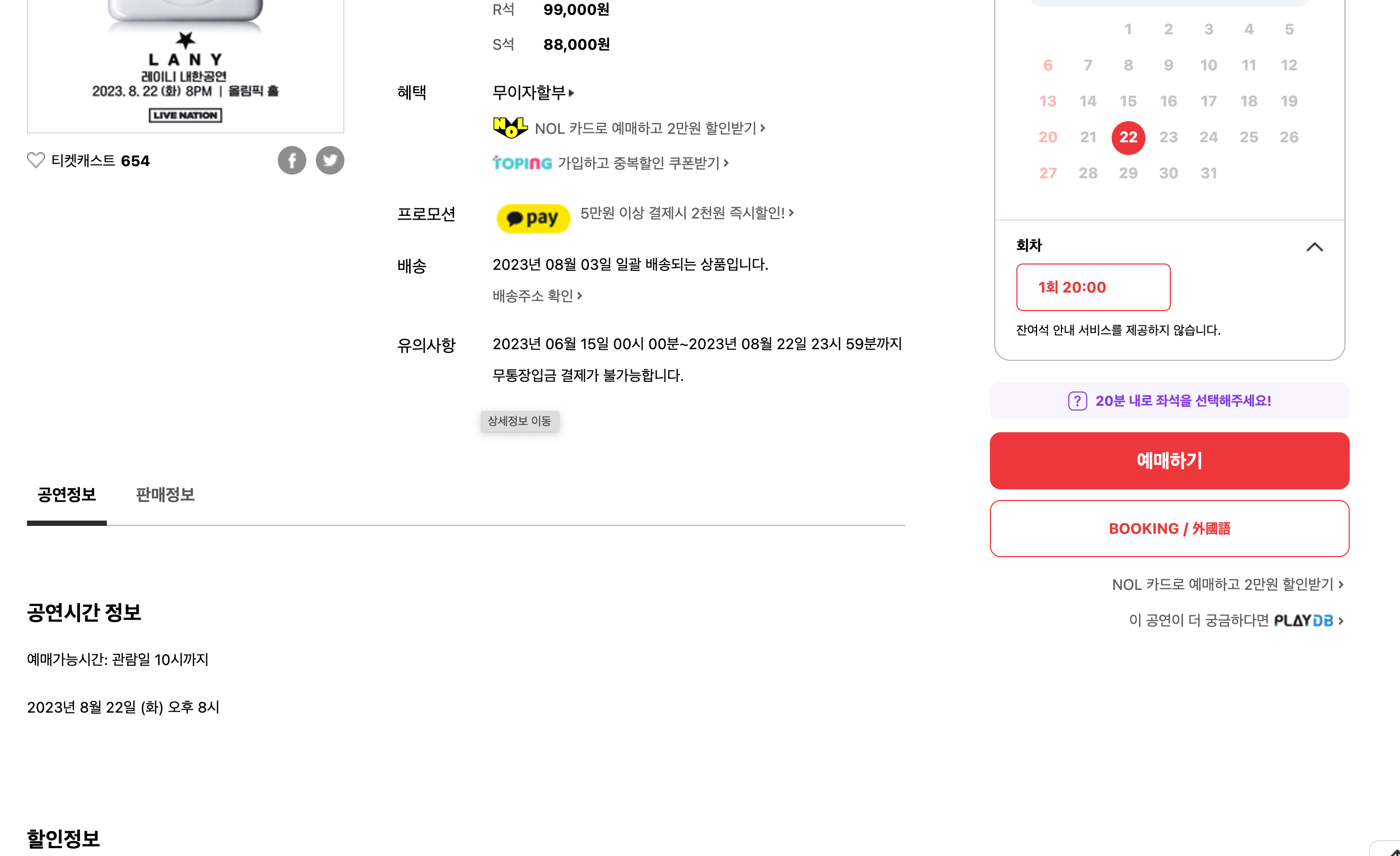
따라서, 만약 존재하지 않는 태그를 크롤링하려고 하면 NoSuchElementException이 발생하게 되며 크롤링이 중단됩니다.
이렇게 크롤링이 중단될 경우를 대비하기 위해 try-catch문을 사용해서 해결했습니다.
따로 try-catch문을 만들어서 NoSuchElementException이 발생할 때도 값을 반환받을 수 있도록 메소드를 따로 만들어주면 됩니다.
catch(NoSuchElementException e)를 넣어서 필요한 데이터를 NULL로 처리해주는 방법을 사용했습니다.
private String getCrawlingSinger(WebDriver webDriver){
String crawlingSinger = "";
try{
WebElement webElement = webDriver.findElement(By.cssSelector(".castingName"));
crawlingSinger = webElement.getText();
}
catch (NoSuchElementException e){
crawlingSinger = "NULL";
}
return crawlingSinger;
}
- 리스트를 for-loop문으로 아이템에 접속하고 뒤로 가기를 했을 때 리스트 값이 초기화가 되어 StaleElementReferenceException이 발생
StaleElementReferenceException은 DOM에 해당 요소가 존재하지 않을 때 발생하는 에러입니다. 처음에는 페이지가 완전히 로딩되지 않아서 발생하는 문제라고 생각했습니다.
그래서 Thread.sleep() 메소드로 로딩이 완료되길 기다렸습니다.
하지만, 충분한 시간이 주어졌음에도 여전히 StaleElementReferenceException이 발생했습니다.
결국 페이지 접속 후 뒤로가기로 가는 플로우로 인해서 해당 요소가 초기화되어 찾을 수 없다는 이유를 발견했습니다.
그래서 제가 생각해낸 해결책은 리스트에 존재하는 아이템 접속 주소를 크롤링해서 자바의 리스트에 저장 후 해당 url을 하나 하나씩 접속해서 페이지 내 정보를 크롤링하는 방법입니다.
아래 방법으로 페이지 리스트에 존재하는 아이템 접속 url을 전부 자바 리스트에 저장합니다.
List<WebElement> concertElementList = webDriver.findElements(By.cssSelector("td .fw_bold a"));
List<String> urlLIst = new ArrayList<>();
for (WebElement concertEl : concertElementList){
urlLIst.add(concertEl.getAttribute("href"));
}그리고 해당 url에 접속할 수 있도록 for-loop문과 WebDriver의 get()메소드를 사용해서 아이템에 각각 접속 후 원하는 데이터를 크롤링해줍니다.
이후에 MongoDB에 Repository의 save() 메소드로 객체를 저장해줍니다.
for (String concertUrl : urlLIst) {
webDriver.get(concertUrl);
Thread.sleep(15000);
WebElement elementTitle = webDriver.findElement(By.cssSelector(".prdTitle"));
WebElement elementPlace = webDriver.findElement(By.cssSelector(".infoBtn"));
WebElement elementDate = webDriver.findElement(By.cssSelector(".infoText"));
String elementTime = getCrawlingTime(webDriver);
String elementSigner = getCrawlingSinger(webDriver);
List<String> priceList = getMinMaxPrice(webDriver);
CrawlingInfo crawlingInfo = CrawlingInfo.builder()
.title(elementTitle.getText())
.place(elementPlace.getText())
.date(elementDate.getText())
.singer(elementSigner)
.time(elementTime)
.maxPrice(priceList.get(0))
.minPrice(priceList.get(1))
.build();
crawlingRepository.save(crawlingInfo);
crawlingInfoList.add(crawlingInfo);
}2가지 방법으로 문제를 해결한 뒤 크롤링 데이터가 MongoDB에 제대로 저장이 되었는지 확인해줍니다.
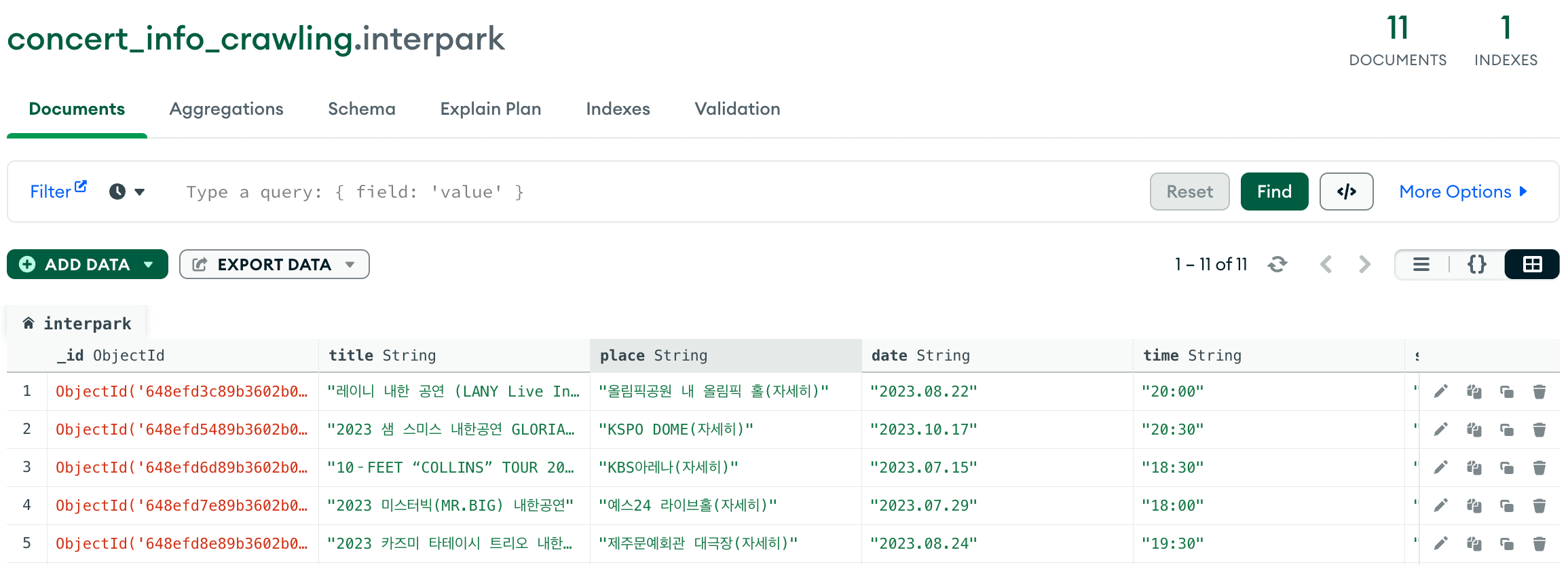
데이터가 잘 저장이 된 걸 확인할 수 있습니다!
전체 코드는 아래와 같습니다
@Slf4j
@Service
@RequiredArgsConstructor
public class CrawlingService {
private final CrawlingRepository crawlingRepository;
private WebDriver webDriver;
public List<CrawlingInfo> getCrawlingInfos() throws IOException, InterruptedException {
List<CrawlingInfo> crawlingInfoList = new ArrayList<>();
String url = "http://ticket.interpark.com/TPGoodsList.asp?Ca=Liv&SubCa=For&tid4=For";
log.info("interpark 크롤링 시작");
System.setProperty("webdriver.chrome.driver", "/Users/joonghyun/Downloads/chromedriver_mac64/chromedriver");
webDriver = new ChromeDriver();
webDriver.get(url);
Thread.sleep(1000);
List<WebElement> concertElementList = webDriver.findElements(By.cssSelector("td .fw_bold a"));
List<String> urlLIst = new ArrayList<>();
for (WebElement concertEl : concertElementList){
urlLIst.add(concertEl.getAttribute("href"));
}
Thread.sleep(10000);
for (String concertUrl : urlLIst) {
webDriver.get(concertUrl);
Thread.sleep(15000);
WebElement elementTitle = webDriver.findElement(By.cssSelector(".prdTitle"));
WebElement elementPlace = webDriver.findElement(By.cssSelector(".infoBtn"));
WebElement elementDate = webDriver.findElement(By.cssSelector(".infoText"));
String elementTime = getCrawlingTime(webDriver);
String elementSigner = getCrawlingSinger(webDriver);
List<String> priceList = getMinMaxPrice(webDriver);
CrawlingInfo crawlingInfo = CrawlingInfo.builder()
.title(elementTitle.getText())
.place(elementPlace.getText())
.date(elementDate.getText())
.singer(elementSigner)
.time(elementTime)
.maxPrice(priceList.get(0))
.minPrice(priceList.get(1))
.build();
crawlingRepository.save(crawlingInfo);
crawlingInfoList.add(crawlingInfo);
}
webDriver.close();
webDriver.quit();
return crawlingInfoList;
}
private String getCrawlingTime(WebDriver webDriver){
String crawlingTime = "";
try{
WebElement webElement =webDriver.findElement(By.cssSelector(".timeTableLabel span"));
crawlingTime = webElement.getText();
}
catch (NoSuchElementException e){
crawlingTime = "NOT OPENED";
}
return crawlingTime;
}
private String getCrawlingSinger(WebDriver webDriver){
String crawlingSinger = "";
try{
WebElement webElement = webDriver.findElement(By.cssSelector(".castingName"));
crawlingSinger = webElement.getText();
}
catch (NoSuchElementException e){
crawlingSinger = "NULL";
}
return crawlingSinger;
}
private List<String> getMinMaxPrice(WebDriver webDriver){
List<String> priceList = new ArrayList<>();
try {
List<WebElement> elementPriceList = webDriver.findElements(By.cssSelector(".infoPriceItem .price"));
Optional<String> maxPriceOptional = elementPriceList.stream().map(WebElement::getText).findFirst();
Optional<String> minPriceOptional= Optional.empty();
if (elementPriceList.size()==0){
minPriceOptional = Optional.of("0");
}
else {
minPriceOptional = elementPriceList.stream().skip(elementPriceList.size() - 1).map(WebElement::getText).findFirst();
}
priceList.add(maxPriceOptional.orElse("0"));
priceList.add(minPriceOptional.orElse("0"));
}
catch (NoSuchElementException e){
priceList.add("0");
priceList.add("0");
}
return priceList;
}
}


Jsoup은 동적 데이터를 수집할 수 없는 경우가 많은 대신 정적 데이터를 좀 더 빠르게 수집할 수 있고,
Selenium은 Jsoup에 비해 속도는 느려도 브라우저 드라이버를 사용해 동적 데이터도 수집이 가능하군요..!
자바로 크롤링 해본적은 없는데 한번 해봐야겠네요.
포스팅 잘 읽었습니다 :)