최근 NLP에선 BERT계열 모델을 활용한 Trnasfer-Learning이 굉장히 🔥hot🔥하다. 사실 Transfer-Learning이 유명해지게된 것은 Computer Vision 분야인데 BERT가 나오면서 NLP 분야에서도 Transfer-Learning이 hot해지기 시작하였다. NLP에 관심이 많은 사람들이라면 다 아는 이야기이니 전이학습, Transfer-Learning에 대한 이야기는 이정도로 하고 전이학습에서 주로 사용되는 용어인 PLM, Fine-tuning 등에 대해 간략히 설명해보겠다.
PLM이란?
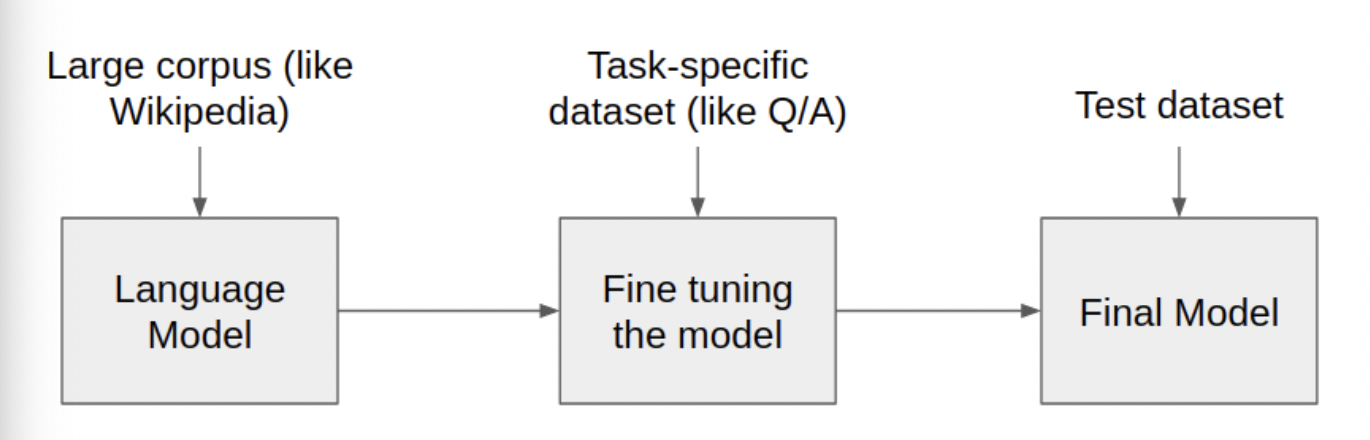
PLM(Pretrained Language Model)
많은 양의 텍스트 데이터를 활용하여 일반적인 수준의 언어 이해(language understanding)가 가능하도록 단어 시퀀스에 확률을 부여하는 모델인 LM(Language Model)을 사전에 학습시킨 모델을 의미한다.
Fine-tuning이란?
Fine-tuning
사전에 학습시킨 언어 모델 PLM을 text_classification, QA(Question Answering), NER(Name Entity Recognintion) 과 같은 downstream task를 수행함으로써 PLM의 파라미터들을 재업데이트하는 과정을 fine-tuning이라고 말할 수 있다.
Inference란?
Inference
infernece란 fine-tuning처럼 학습을 마친 모델에 실제 데이터(test-data)를 input으로 적용하는 행위로 말할 수 있다.
자, 이제 간단하게 fine-tuning을 위한 기본적인 개념을 설명해보았고 이번 포스트에서 기술하려는 fine-tuning 프로젝트의 스펙(?)에 대해 간략하게 설명해보겠다.
- 학습 데이터: daum 뉴스에서 크롤링한 약 10만여개의 기업 관련 뉴스 데이터(사전 라벨링된)
- 사용한 언어: pytorch lightning⚡️
pytorch lightning이란?
- PyTorch에 대한 High-level 인터페이스를 제공하는 오픈소스 Python 라이브러리.
- 코드의 추상화를 통해, 정돈된 코드 스타일을 갖추게 된다는게 pytorch lightning의 장점이다.
- trainer 클래스가 매력적.
- 사용한 PLM: KLUE(Korean Language Understanding Evaluation Benchmark)를 통해 배포된 RoBERTa 모델(HuggingFace Model Hub에 배포되어있음), pretrain에 사용된 corpus의 size만 62GB.... ㅎㄷㄷ 🤪
Fine-tuning 단계
1. Import Packages
- Fine-tuning 프로젝트에서 사용될 package들을 불러온다.
import transformers
import torch
import numpy as np
import pandas as pd
import random
import os
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
from datasets import load_dataset, load_metric
from transformers import Trainer,TrainingArguments,AutoTokenizer,AutoModelForSequenceClassification,DataCollatorForTokenClassification,EarlyStoppingCallback
from datasets import Dataset
import time2. Setting Hyperparameter
- 학습에서 중요한 모델의 하이퍼파라미터들을 사전에 정의한다.
- 학습 결과가 만족스럽지 못하다면 아래의 파라미터들을 재조정해야한다.
model_checkpoint = "klue/roberta-large"
batch_size = 32
wd = 0.01
lr = 2e-5
epochs = 3
task = "binary_classification"
label_list = [0,1]
num_labels = 2- For Reproducibility
def seed_everything(seed:42):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed) # type: ignore
torch.backends.cudnn.deterministic = True # type: ignore
torch.backends.cudnn.benchmark = True # type: ignore
# fix seed
seed_everything(42)3. Data Load
- 해당 데이터는 해당 기사가 기업의 실적과 관련된 기사인지(1) 아닌지(0) 사전에 labeling 된 약 10만여개의 텍스트 데이터이다.
- 해당 데이터의 class를 비교해보았다.

- 위의 그림을 보면 알 수 있듯이 데이터 class imbalance 이슈가 있는 것을 확인할 수 있다.
Class Imbalance의 문제는 무엇일까?
- 대부분의 머신러닝 모델은 class간의 데이터의 비율이 비슷하다는 가정에서 성립된다.
- binary classification에서 class 0에 90%의 샘플이 있고, class 1에 10%의 샘플이 있을 때, loss 값에는 class 0가 90%, class 1이 10% 기여를 하는 셈이고 모든 예측을 0으로 한다고해도 90%의 정확도를 갖는 예측을 할 수 있게된다.
- 즉, 학습을 수행하는 loss 값에 각각 데이터 샘플 별로 기여를 하기 때문에, 샘플 수가 많은 majority class만을 잘 예측하도록 학습된다.
- 이러한 class imbalance를 해결하기 위해 minority class를 oversampling하는 SMOTE와 같은 기법도 있으나 필자는 fine-tuning하기에 2만개의 데이터면 충분하다는 경험적 판단이 들어 majority class(0)의 뉴스 개수를 minority class(1)의 뉴스 개수와 똑같이 맞췄다.

4. Training, Validation Data Random Split
- Training , Validation Data를 각가 8:2의 비율로 Random하게 Split하였다.
train_data, val_data = train_test_split(data, random_state=42,test_size=.2)df_train = pd.DataFrame({"title":train_data["title"],'label':train_data["label"]})
dataset_train = Dataset.from_pandas(df_train)df_val = pd.DataFrame({"title": val_data["title"],'label':val_data["label"]})
dataset_val = Dataset.from_pandas(df_val)5. Model & Tokenizer Load
- 위에서 언급한 klue/RoBERTa 모델과 해당 모델의 토크나이저를 transformers 라이브러리의 AutoTokenizer,AutoModelForSequenceClassification를 통해 불러온다.
- 해당 모델을 학습하는데 쓰인 tokenizer로 fine-tuning 단계에서도 동일하게 사용해야하는건 다들 알고 있을 것이다...!
try:
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
except:
time.sleep(5)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)import transformers
assert isinstance(tokenizer, transformers.PreTrainedTokenizerFast)6. Make Dataset
- tokenizer의 max_length는 최대 512이나 gpu_memory 할당을 고려하여 50으로 지정하였다.
- 사실 뉴스 기사들의 제목 길이가 보통 50을 넘는 경우가 거의 없다.
- 물론 학습 뉴스 기사들의 제목을 plot으로 찍어보고 max_length를 판단하는게 가장 바람직....🤫
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", max_length = 50,truncation=True)tokenized_train_datasets = dataset_train.map(tokenize_function, batched=True)
tokenized_val_datasets = dataset_val.map(tokenize_function, batched=True)7. Instantiate Trainer Arguments
- 각각의 파라미터는 https://pytorch-lightning.readthedocs.io/en/stable/common/trainer.html 을 통해 각자 공부해보는 것을 권장한다 (설명하기 귀찮아서 절대 아님, 무튼 아님).
model_name = model_checkpoint.split("/")[-1]
args = TrainingArguments(
f"test-{task}",
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate= lr,#2e-5
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=epochs,
seed = 42,
weight_decay=wd,load_best_model_at_end=True,)8. Define Metrics
- Remember that all 🤗 Transformers models return the logits
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='macro')
acc = accuracy_score(labels, preds)
return {
'accuracy': acc,
'f1': f1,
'precision': precision,
'recall': recall
}9. Create a new Trainer for our fine-tuned model
- EarlyStopping은 자원의 낭비를 막아준다!
trainer = Trainer(
model,
args,
train_dataset=tokenized_train_datasets,
eval_dataset=tokenized_val_datasets,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)],
)10. Train and Evaluate model
- 학습하면서 주의깊게 봐야하는 것은 어느 시점에서 training loss와 validation loss가 비슷해지는가이다.
- 필자는 딥러닝 시각화 tool인 wandb(https://wandb.ai/site)를 활용하여 실시간으로 모델의 학습 경과를 모니터링하였다.
trainer.train()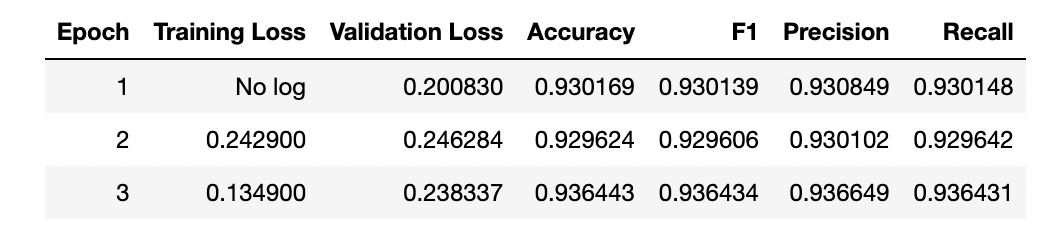
trainer.evaluate()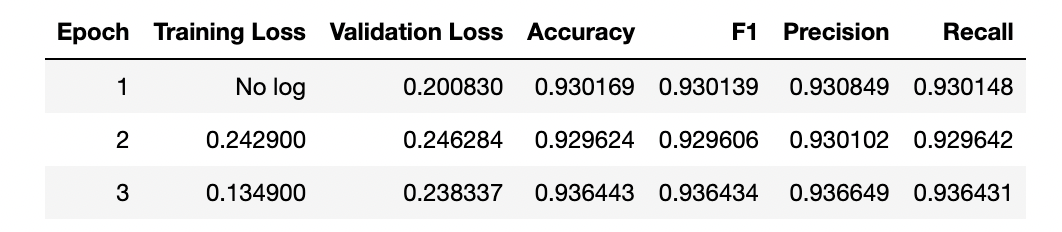
11. Inference with Test Data
- training, validation과 독립적인 Test Data를 사전에 지정해둔다.
- 하나의 프로젝트에서 Test Data는 절대 변동되어서는 안되며 최종 모델의 성능은 이 Test Data를 fine-tuning한 모델에 넣어서 나온 결과로 말할 수 있다.
- 위에서 학습한 모델을 pipeline에 장착한다.
- 해당 pipeline에 들어가는 model 과 tokenizer는 위에서 학습을 하고 best-model의 weight이 저장되어있는 checkpoint를 가져온 것이다.
from transformers import pipeline
pipe = pipeline(task = "text-classification",
model = model,
tokenizer = tokenizer,
device = 0)- test data를 통해 해당 모델의 최종 성능을 확인한다.
- 만약 만족스럽지 못한 결과가 나온다면 다시 학습단계로 돌아가 learning rate 과 같은 파라미터들을 재조정해보는 것을 권장한다.
- 파라미터들을 재조정해도 결과가 만족스럽지 못하다면 Data의 Quality를 의심해볼 것을 권장한다.
from sklearn.metrics import classification_report
print(classification_report(list(test_data["실적"]), list(test_data['filter'])))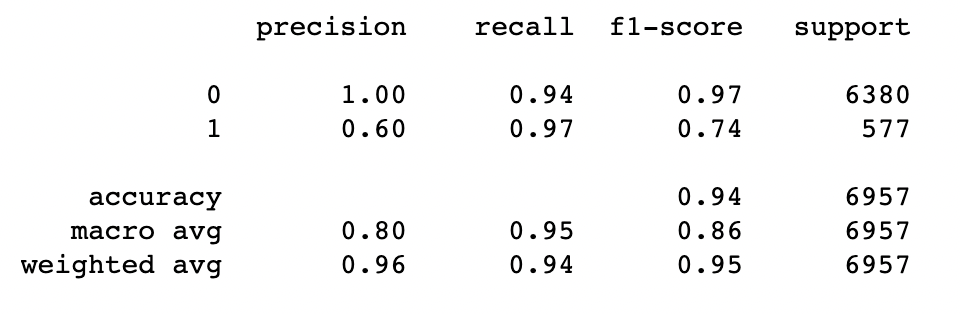
해당 프로젝트는 필자가 이전 회사에서 진행하였던 NLP 프로젝트 중 하나였다.
binary classification 이외에도 QA,NER, Document Clustering 등 다양한 NLP 프로젝트들을 수행하였고 계속하여 관련 프로젝트에 대한 포스트를 올리도록 하겠다.
혹시 개념에서의 오류나 코드상에서의 오류 ,미숙함, 오타, 이것은 궤변이다, 등등 다양한 의견을 받고 있으니 언제든지 부족한 필자의 발전을 위해 남겨주면 감사하겠다 매우매우....!!!!!!!!
🙏Reference🙏
(https://medium.com/data-folks-indonesia/modeling-using-hugging-face-transformers-f956bccf7ccd)
(https://baeseongsu.github.io/posts/pytorch-lightning-introduction/)
(https://github.com/klue-benchmark/klue?utm_medium=social&utm_source=medium&utm_campaign=everyone%20ai&utm_content=klue)
(https://hyeonchan523.github.io/ds/class-imbalance/)
(http://blog.hwahae.co.kr/all/tech/tech-tech/5876/)

코드 구현하는데 큰 도움이 됐어요 감사합니다!