Image by Freepik

왜 비동기 코드를 작성하시나요?
질문에 바르게 답하기 위해서 먼저 동기식, 비동기식에 대한 개념을 정리하고, 코드 구현 상에 어떤 차이가 있는지 직접 Java 예제 코드를 작성해 봅니다. 그리고 두 코드를 실행해서 어떤 성능적 차이가 있는지 직접 측정해 본 다음 결과를 분석하고, 성능 이외에 어떤 장단점을 가지고 있는지 정리해 보겠습니다. 마지막으로 그래서 왜 비동기 코드를 작성하는지 그리고 어떤 분야에 적용하기 좋은지 정리해 보도록 하겠습니다.
1. 개념
협력 모델
동기식(Synchronous)또는 비동기식(Asynchronous)이라는 개념은 둘 이상의 프로그램 요소(클래스, 컴포넌트, 서비스 등)들이 작업을 요청하고 결과를 응답하는 협력 관계 안에서 정의될 수 있습니다.
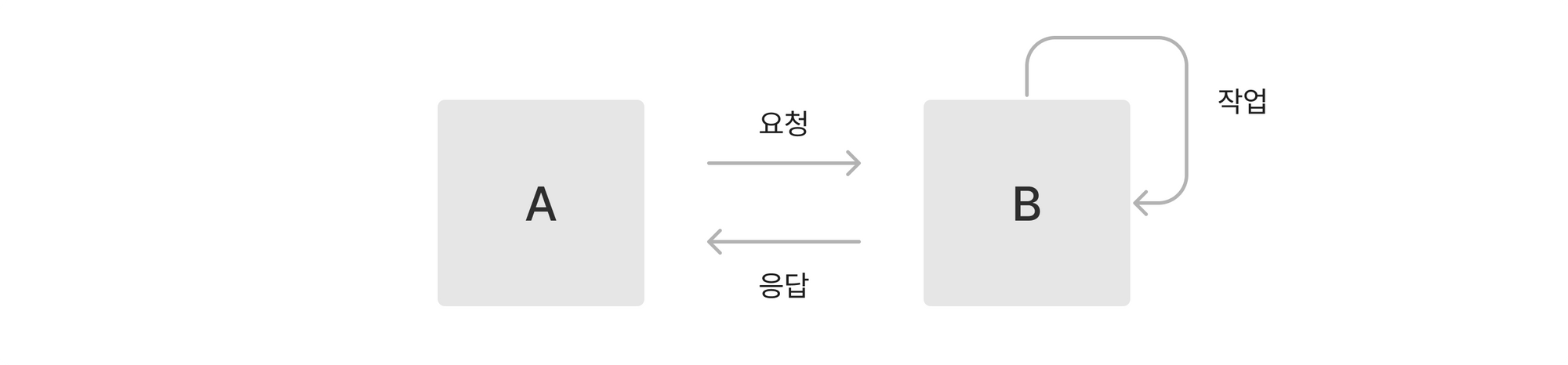
동기식 모델
먼저 동기식 모델에서는 A가 B에게 어떤 작업을 요청한 후에 B가 요청된 작업을 완료 할 때 까지 (선택의 여지 없이) 대기하게 됩니다. A는 B에게 요청한 작업이 완료되어야 그때 부터 다른 일을 할 수 있게 됩니다. A가 만약 전체 작업 완료를 위해 B, C에게 부분적인 작업을 요청해야 한다면 부분적인 작업은 순서대로 하나씩 실행되게 됩니다.
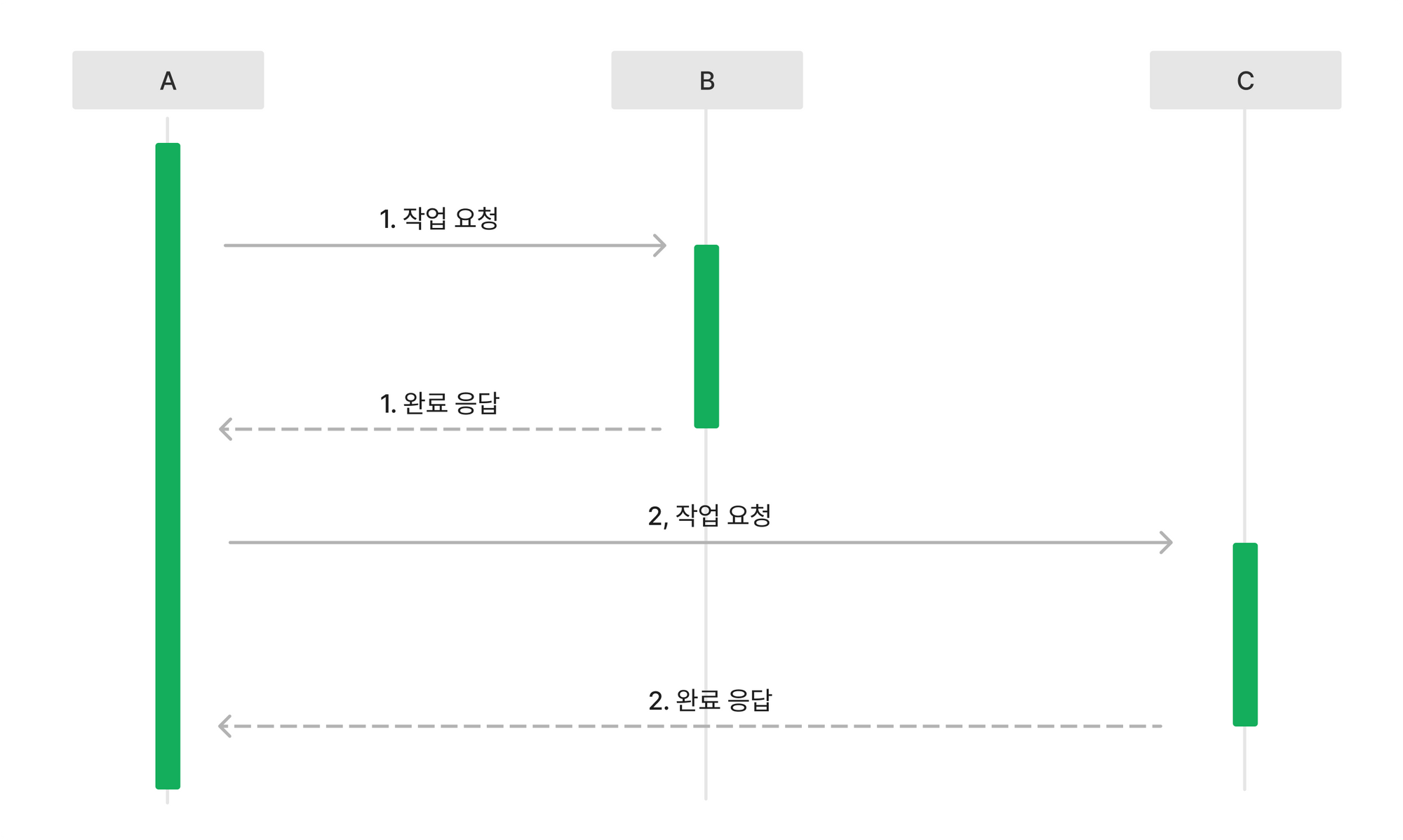
비동기식 모델
반면 비동기식 모델에서는 A가 B에게 어떤 작업을 요청한 후에 B가 작업을 완료하기 전에 또 다른 요청을 C에게 보내거나 스스로 다른 일을 할 수 있습니다. A는 B가 작업을 완료할 때까지 기다리지 않습니다. 대신 B에게 요청한 작업 결과는 내가 원하는 시점에 직접 확인(Polling)하거나, B가 작업을 완료하면 A에게 알려주도록(Event Driven) 설정할 수 있습니다. A가 전체 작업 완료에 B, C에게 요청이 필요하다면 두 작업은 동시에 실행될 수 있습니다.

사전적 의미와 연결
동기식(Synchronous)이라는 단어를 영어사전에 검색해 보면 ‘함께 발생하는’ 이라는 뜻을 가지고 있습니다. 종종 ‘동기식’이라는 단어의 의미와 프로그래밍에 적용되는 개념이 잘 연결이 안되곤 하는데 왜 그런지 생각해 봅니다. 아마도 함께 발생하는 두 가지가 무엇인지 명확히 설명하기 힘들기 때문인 것 같습니다. 개인적으로 두 가지 해석을 생각해 봅니다. 우선 동기식 모델에서 작업 요청은 곧 완료 응답으로 해석 할 수 있습니다. 요청을 하면 성공이든 실패든 예외가 발생하든 어떤 결과든 그 자리에서 나옵니다. 작업 요청과 처리 완료 사이에 시간적인 간격은 있지만 이 둘이 분리될 수 없는 하나의 단위로 함께 일어난다고 볼 수 있겠습니다. 또 다른 해석도 생각해 볼 수 있습니다. 함께 발생하는 또 다른 요소는 요청한 작업이 완료되는 이벤트와 요청자가 다음 작업 수행을 이어가는 이벤트로 볼 수 있습니다. 동기식 모델에서는 요청한 작업이 완료되어야 다음 작업을 이어갈 수 있기 때문입니다.
2. 코드
그럼 이제 동기식, 비동기식 모델을 코드로 구현해서 코드와 실행 흐름에는 어떤 차이가 있는지 살펴보겠습니다. 코드로 구현해 볼 요구사항은 사용자에게 정수 N과 M을 입력받아 N factorial (n x (n-1) x … x 2 x 1)과 1부터 M까지의 합을 구한 다음 두 결과를 더하여 반환하는 겁니다. 단순한 코드를 위해 모든 예외 상황은 무시하겠습니다. 두 코드의 실행 결과를 극명하게 비교하기 위해 다음과 같은 가정도 추가하겠습니다. 우리 프로그램이 실행되는 시스템은 쿼드 코어 (4개의 CPU 코어)로 구성되어 있고, N factorial을 구하는데 1초가 걸리고, 1부터 M까지 합을 계산하는데 0.5초의 시간이 걸리는 시스템이라고 가정하겠습니다. 코드 상에서도 처리 시간을 모의하기 위해 의도적으로 가정한 시간을 지연할 겁니다.
동기식 코드
동기식 코드는 다음과 같이 구현할 수 있습니다. 먼저 Server는 Calculator에게 N factorial 계산을 요청하고 Calculator의 계산이 완료될 때까지 대기합니다. factorial 계산이 완료되면 이어서 1부터 M까지의 합계를 다시 Calculator에게 요청하고 이번에도 계산이 완료될 때까지 대기합니다. 동기식 코드에서는 factorial과 sum 계산이 차례대로 수행되고 Server는 두 결과를 더해 최종 결과를 반환합니다.
public class Server {
private final Calculator calculator = new Calculator();
public long work(int n, int m) {
long factorial = calculator.factorial(n);
long sum = calculator.sum(m);
return factorial + sum;
}
}
public class Calculator {
public long factorial(int n) {
// 1-N 팩토리얼 계산
long factorial = LongStream.rangeClosed(1, n)
.reduce(1, (subTotal, x) -> subTotal * x);
// 계산 시간 모의
simulateProcessingTime(1000);
return factorial;
}
public long sum(int n) {
// 1-N 합계 계산
long sum = LongStream.rangeClosed(1, n)
.reduce(0, Long::sum);
// 계산 시간 모의
simulateProcessingTime(500);
return sum;
}
public void simulateProcessingTime(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}비동기식 코드
비동기식 코드는 다음과 같이 구현할 수 있습니다. Server는 Calculator에게 N factorial 계산을 요청합니다. 이때 Calculator는 요청을 받고, 작업을 별도의 쓰레드에 할당한 후 곧바로 클라이언트에게 응답합니다. 여기서 응답은 작업 완료를 의미하지 않습니다. 대신 “요청을 잘 받았고, 작업을 시작했다”는 의미를 가집니다. Server는 Calculator가 N factorial 작업을 수행하는 동안 다시 Calculator에게 1부터 M까지의 합계를 계산해 줄 것을 요청합니다. 두 작업은 서로 독립적이기에 동시에 실행될 수 있습니다. 이번에도 역시 Cacluator는 요청을 받고 작업을 별도의 쓰레드에 할당한 후 곧바로 클라이언트에게 응답합니다. 비동기식 코드에서는 factorial과 sum 계산이 동시에 실행되고 두 작업 모두 완료되는 대로 Server는 두 결과를 더하여 최종 결과를 반환합니다.
public class Server {
private final Calculator calculator = new Calculator();
public long workAsync(int n, int m) {
CompletableFuture<Long> factorialFuture = calculator.factorialAsync(n);
CompletableFuture<Long> sumFuture = calculator.sumAsync(m);
return factorialFuture.join() + sumFuture.join();
}
}
public class Calculator {
...
public CompletableFuture<Long> factorialAsync(int n) {
// 별도의 쓰레드에 작업 할당
return CompletableFuture.supplyAsync(() -> {
return factorial(n);
});
}
public CompletableFuture<Long> sumAsync(int n) {
// 별도의 쓰레드에 작업 할당
return CompletableFuture.supplyAsync(() ->{
return sum(n);
});
}
}3. 성능 측정
위에서 동일한 요구사항을 동기식과 비동기식 코드로 구현해 보았습니다. 두 가지 코드를 테스트하는 메서드를 작성하여 실행시켜 보고 어떤 성능 상의 차이가 있는지 확인해 보겠습니다.
public class SyncModelTest {
@Test
void synchronous() {
Server server = new Server();
long result = server.work(10, 10_000_000);
Assertions.assertEquals(50_000_008_628_800L, result);
}
@Test
void asynchronous() {
Server server = new Server();
long result = server.workAsync(10, 10_000_000);
Assertions.assertEquals(50_000_008_628_800L, result);
}
}결과를 보면 두 모델은 똑같은 계산 코드를 사용하지만 동기 모델을 사용하는 경우 약 1.5초 시간이 소요되었습니다. factorial 계산에 1초, sum 계산에 0.5초가 걸린 것입니다. time(work)를 work를 수행하는데 걸린 시간이라고 한다면 전체 작업에 소요되는 시간은, time(work) = time(factorial) + time(sum)과 같이 표현할 수 있습니다. 동기식에서는 전체 작업을 구성하는 부분 작업이 많아질수록 전체 작업 시간이 선형적으로 증가합니다. 반면에 비동기 모델을 사용하는 경우 약 30% 정도 성능이 향상된 1초에 가까운 시간이 걸렸습니다. factorial 계산을 1초 동안 수행하는 중에 sum 계산이 동시에 수행되었기 때문입니다. max(x,y)를 x 작업과 y 작업에 걸린 시간 중 오래 걸린 시간이라고 한다면 전체 작업에 소요되는 시간 time(workAsync) = max(factorialAsync, sumAsync)과 같이 표현할 수 있습니다. 비동기식에서는 부분 작업이 많아지더라도 병렬로 실행될 수 있는 개수(CPU 코어 개수)까지는 작업 시간이 가장 긴 부분 작업 시간이 전체 작업 시간이 됩니다. CPU 코어 개수 보다 많은 작업이 동시에 실행될 수는 없고, 각 작업의 유휴시간에 시간을 나누어 병행 실행된다고 볼 수 있습니다. 이 방법 역시 동기식 보다 빠르게 작업을 처리하는 수단이 됩니다.

4. 장단점
성능 측면에서만 보면 비동기 모델이 무조건 좋다고 생각할 수 있습니다. 그러나 성능 이외에 두 모델에는 장단점이 있고 각자 적합한 영역이 있습니다.
비동기식 장점
비동기식의 장점부터 살펴보겠습니다. 앞서 성능 측정 결과에서 볼 수 있듯이 똑같은 일을 하는데 동기식 보다 빠르기 때문에 시스템의 응답성을 높일 수 있습니다. CPU 코어 개수가 N개라면 동시에 (독립적인) N개의 일을 할 수 있으며, CPU 코어가 1개라도 서브 작업 수행 중 네트워크, 파일 I/O 등으로 대기 시간이 생기면 중간 중간 놀지 않고 CPU가 다른 일들을 하게 할 수 있기 때문입니다. 또한 빠르기 때문에 단위 시간 당 서비스가 더 많은 요청을 처리할 수 있게 됩니다.
비동기식 단점
비동기식의 성능 이점이 크지만 단점도 있습니다. 먼저 코드의 흐름이 여러 가지로 나누어집니다. 그래서 코드를 눈으로 읽는 순서가 코드의 실행 순서가 아닐 수 있게 되고, 코드의 실행 흐름을 예측하면서 읽기 어렵게 됩니다. 디버깅을 할 때에도 여러 실행 흐름을 함께 쫒아야 하기 때문에 동기식 보다 디버깅이 어렵습니다. 뿐만 아니라 요청과 작업의 흐름이 나누어 지면서 복잡한 처리 조건들이 더 생길 수 있습니다. 예를 들면 N개의 서브 작업에 모두 작업 요청을 했는데 중간에 한 작업이 실패한 경우에 이미 요청된 다른 서브 작업들을 롤백해 주어야 할 수 있습니다. 이 때 어떤 부분 작업은 실행이 완료되었을 수도 있고, 어떤 부분 작업은 실행 중에 있을 수도 있는데 그러면 실행을 취소해 주는 메커니즘이 추가로 필요하다거나 또는 롤백을 위해 실행 완료를 대기해야 할 수도 있습니다. 마지막으로 비동기식 코드는 멀티쓰레드 환경에서 동작하기 때문에 상태를 가지는 공유 데이터가 있는 경우 Race condition이 발생하지 않도록 주의를 기울어야 합니다.
동기식 장점
그럼 이제 동기식 코드의 장점에 대해 살펴보겠습니다. 비동기식 코드의 단점과 반대된다고 볼 수 있겠습니다. 우선 실행 흐름이 하나이기 때문에 코드를 따라가면서 읽으면 곧 실행되는 흐름이 됩니다. 그래서 코드 실행 흐름을 이해하기 쉽고, 문제가 생겼을 때도 디버깅하기도 상대적으로 쉽습니다. 또한 하나의 쓰레드에 의해 차례대로 실행되기 때문에 Race condition을 고민할 필요가 없습니다.
동기식의 단점
단점은 성능 측정에서 극명히 드러났습니다. 같은 일을 하는데 비동기식 방식에 비해 처리 속도가 느립니다. 우리 시스템이 쿼드 코어(4개의 CPU)로 구성되어 있는데도 한 번에 하나의 CPU만을 써서 작업을 순차적으로 처리하기 때문입니다. 상황에 따라서 사용될 수 있는데 아무일도 하지 않은 자원들이 생기고, 자연스레 단위 시간 당 처리할 수 있는 시스템의 처리량도 제한적이게 됩니다.
5. 왜 비동기 코드를 작성하나요?
이제 처음의 질문으로 돌아가 보겠습니다. 왜 우리가 비동기 코드를 작성하는 걸까요? 답은 비동기 코드의 장점을 활용하기 위해서 라고 답할 수 있겠습니다.
비동기 코드를 작성하면 병렬 작업을 통해 시스템 자원을 최대한 활용하여 동기식 보다 빠르게 일을 처리할 수 있습니다. 이로 인해 시스템의 응답성을 높이고, 단위 시간 당 더 많은 요청을 처리할 수 있게 됩니다. 이러한 장점을 취하기 위해 비동기 코드를 작성합니다.
6. 어떤 서비스에 적합할까요?
앞서 동기, 비동기 방식의 장단점을 살펴보았기 때문에 절대적으로 어떤게 좋다고 할 수 없다는 것을 이해했습니다. 그럼 비동기식 모델이 적합한 서비스에는 어떤 것이 있을까요? 이번에도 비동기식의 장점을 활용해야하는 서비스라고 할 수 있겠습니다. 바로 단위 시간당 많은 요청을 빠르게 처리해야 하는 대규모 서비스에 비동기 모델이 적합합니다. 지금 당장 사용자가 많지 않더라도 우리가 바라보는 규모가 크다면 처음부터 비동기 모델을 적용해서 서비스를 개발하는 것이 좋습니다. 사용자가 많은 대규모 서비스가 아니더라도 적합한 응용도 있습니다. 만약에 한 명의 사용자를 서비스 하더라도 특정 비지니스 로직이 여러 서브 모듈들과 협력하고 각 서브 모듈이 부분적인 작업을 수행하는데 많은 시간이 걸리는 경우 응답 성능을 높이기 위해 부분적으로 비동기 코드를 적용하는 예도 적절합니다.
7. 마치며
저는 개인적으로 동시 사용자가 많은 대규모 서비스를 경험해 보지 못했습니다. 앞서 설명 드린 후자와 같이 일부 비지니스 로직에 실행 시간이 긴 여러 모듈이 참여하고 빠른 응답성이 요구되는 경우 부분적으로 비동기 모델을 적용하곤 했습니다. 그럼에도 불구하고 제가 비동기 코드를 자주 접했던 건, 주로 사용했던 프레임워크가 기본적으로 비동기 모델로 되어 있었기 때문이었습니다. 비동기 코드가 처음에는 조금 어렵고 낯설었던 것 같은데 계속 만들고 사용하다보니 동기식 코드만큼 익숙해 지는 것도 사실인 것 같습니다. 그럼 글을 마치겠습니다. 여기까지 읽으신 분이 계시다면 비동기식, 동기식 모델과 코드에 대해 이해하는데 조금이라도 도움이 되셨으면 좋겠습니다. 저는 글을 정리하면서 많은 공부가 되었습니다. 감사합니다.
