초기 구현 단계에서는 종목별 데이터를 순차적으로 수집하고 저장하는 구조였지만, 1000여 개의 종목을 다루다 보니 성능 개선이 필요했습니다. 이에 따라 병렬 처리를 도입하고, 수집 단계가 성공적으로 수행된 후 저장 단계가 실행되도록 동기 프로세스를 적용했습니다.
주식 데이터 수집 & 저장 Dag 개선
1. 데이터 저장 task 분리
기존 load_csv_to_mysql 태스크를 OHLCV 데이터와 시가총액 데이터를 별도로 처리하도록 분리했습니다. 이를 통해 각 데이터 유형별로 개별적으로 병렬 처리할 수 있도록 변경했습니다.
load_ohlcv_to_mysql = PythonOperator(
task_id='load_ohlcv_data',
python_callable=load_ohlcv_data,
op_kwargs={'start_date': start_date, 'today_date': today_date},
provide_context=True,
dag=dag,
)
load_market_cap_to_mysql = PythonOperator(
task_id='load_market_cap_data',
python_callable=load_market_cap_data,
op_kwargs={'start_date': start_date, 'today_date': today_date},
provide_context=True,
dag=dag,
)2. 데이터 수집과 로딩 task 간 의존성 설정
수집과 저장 과정의 의존성을 명확히 하여 정해진 순서로 실행되도록 개선했습니다.
get_tickers_task >> [
collect_ohlcv_task,
collect_market_cap_task
]
collect_ohlcv_task >> load_ohlcv_to_mysql
collect_market_cap_task >> load_market_cap_to_mysql이를 통해 종목 리스트를 가져온 후, OHLCV 데이터와 시가총액 데이터를 병렬로 수집하고, 각 수집 작업이 성공적으로 완료되면 해당 데이터를 데이터베이스에 저장하도록 변경했습니다.
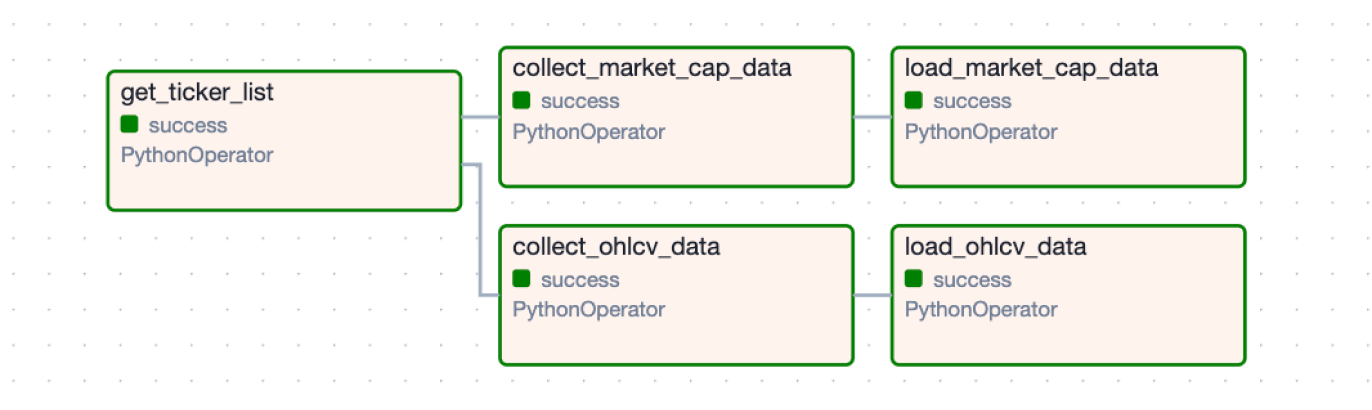
완성된 주식 데이터 수집 파이프라인은 아래와 같습니다.
주식 종목을 수집
➡️ 종목들에 대한 ohlcv, 시가총액 데이터를 수집하여 csv파일로 저장
➡️ csv 파일을 변환하여 mysql 에 저장

백엔드 개발자 ˚₊✩‧₊ ໒꒱