1. 합성곱 신경망
(1) 특징
일반적으로 합성곱 신경망(Convolutional Neural Networks)에는 3종류의 층이 있다.
Convolution Layer (CONV)
Pooling Layer (POOL)
Fully connected Layer (FC)
합성곱 신경망의 크기는 층이 늘어날 수록 이미지의 높이와 크기가 점점 줄어들고 채널의 수는 늘어나는 특징이 있다.
보통 딥러닝에서 말하는 '층'은 두가지 버전이 있다.
하나는 가중치와 변수를 가진 층만 층이라고 칭하고 그 외의 층은 그냥 포함시켜버리는것이다. 이런 경우에는, 풀링 층은 가중치가 없기 때문에 다른층에 포함되게 된다.
나머지 하나는, 무조건 층 단위로 층이라고 부르는 것이다.
(2) CNN을 사용하는 이유
합성곱 신경망을 사용하면 변수를 적게 사용할 수 있는데, 이유는 2가지가 있다.
Parameter Sharing
하나의 필터가 입력 이미지의 여러 위치에서 동일하게 사용되기 때문에, 별개의 속성 검출기를 사용할 필요가 없다.
Sparsity of Connections
결과 이미지의 각 픽셀의 결과값은 입력이미지에서 오직 필터에 해당하는 입력 부분만 연결되어있고 이미지의 나머지 부분은 결과값에 아무런 영향을 미치지 않는다.
2. Convolution Layer
(1) 합성곱 연산
모서리 감지를 위한 예시를 보면서, 합성곱 연산에 대해 배우게 되었다.
합성곱 연산을 할때 필터(커널)을 사용하게 되는데 가로 윤곽선을 검출할때는 아래와 같은 필터를 사용한다.
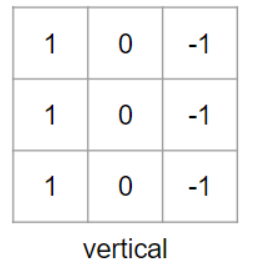
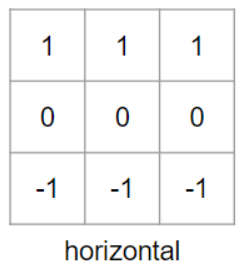
필터를 들어보기만 했는데, 영상을 통해 공부하면서 검출 목적에 따라 다양한 필터가 존재한다는것을 이해하게 되었다. 위의 가로 윤곽선을 검출하는 3*3 필터를 이해한다면, 세로 윤곽선을 검출하는 필터는 아래와 같은 모습이라는 것이 이해가 될것이다.
합성곱 연산을 할때, 각 프로그래밍 언어나 프레임워크에서 제공하는 합성곱 함수가 있다.
예를 들자면 아래와 같다.
📌 python에서는 conv-forward
📌 tensorflow에서는 tf.nn.conv2d
📌 keras에서는 Conv2D
(2) Padding
일반적으로 합성곱 연산을 하게 되면 두가지 문제점이 있다.
☝🏻 첫 번째 문제점은, 합성곱 연산을 할때마다 이미지가 축소된다는 것이다.
만약, n x n 이미지를 f x f 필터로 합성곱하게 되면 결과로, (n-f+1) x (n-f+1) 이미지가 나올 것이다.
따라서 만약 합성곱을 반복하게 되면 이미지는 축소될 수 밖에 없다.
✌🏻 두 번째 문제점은, 이미지의 가장자리 정보들을 거의 날리는 것이다.
합성곱 연산을 하게 되면, 이미지의 가장자리 픽셀은 합성곱 연산을 할때 쓰이는 횟수가 가장 적기 때문에 정보가 날라가는 문제가 있다.
❗ 위 두 문제점을 해결하기 위해서는 합성곱 연산을 하기 전에 이미지에 이미지를 덧대는 것이다.
가장자리에 픽셀 하나씩을 더 추가해주는 경우를 생각해보면, padding은 1이다.
(보통 0을 덧대는게 일반적이다.)
Valid Padding
패딩이 0일때 valid padding이라고 한다.
Same Padding
입력이미지와 출력이미지의 크기가 같게끔 하는 padding을 same padding이라고 한다.
🔎만약 입력 이미지와 결과 이미지의 크기를 같게 하고 싶다면, 얼만큼의 padding을 사용해야 할까?🔎
n x n 이미지에 p픽셀만큼 패딩을 더하고 f x f 필터를 사용한다면, 결과 이미지는 (n+2p-f+1) x (n+2p-f+1) 이미지가 될것이다.
따라서 n = n+2p-f+1 식을 통해 p = (f-1)/2 만큼 픽셀을 더해줘야 입력이미지와 결과 이미지의 크기를 같게 할 수 있다.
(3) Strided Convolution
Stride는 합성곱 연산시 필터의 이동 간격을 말한다.
일반적으로는 입력 이미지에서 필터를 한칸 씩 이동하면서 합성곱 연산을 하지만, Stride를 s만큼 주게 되면 s칸씩 이동하면서 합성곱 연산을 하는 것이다.
🔎n x n 이미지, 패딩 p, 스트라이드 s, 필터 f를 사용한 합성곱 연산 결과 이미지의 크기는?🔎
(((n+2p-f)/s) +1) x (((n+2p-f)/s) +1)가 될것이다.
이때, (n+2p-f)/s) +1의 값이 정수가 아니라면 내림을 해서 사용한다.
❓수학에서의 합성곱 vs 딥러닝에서의 합성곱❓
보통 수학에서의 합성곱은, 합성곱 연산 전에 필터를 미러링하여 뒤집은 다음 연산하는것을 말한다.
하지만 딥러닝에서의 합성곱은 필터를 미러링하지 않고 그대로 사용하는것을 말한다. 더 정확히 말하면, 딥러닝에서의 합성곱은 수학에서의 교차상관이지만 관습적으로 합성곱이라고 부른다.
(4) 3D 이미지에서의 합성곱 연산
흑백 이미지가 아니라 RGB 색상을 가진 이미지라면 총 3개의 색상이 있기 때문에, 채널도 3개가 생기게 된다.
따라서 합성곱 연산에 쓰이는 하나의 필터는 채널의 수만큼 증가하게 된다.
각 채널별로, 필터는 같은것을 쓸수도 있고 다른것을 쓸 수도 있다. 예를 들어, R채널에서는 가로선을 검출하고 G채널에서는 세로선을 검출하듯이 말이다.
3. Pooling Layer
풀링의 변수로는 Filter와 Stride가 있다. 일반적으로 풀링에서 패딩은 사용하지 않는다.
❗ 유의할 점은, 풀링에는 학습하는 변수가 없다. 그래서 역전파가 가능한 변수가 없다.
입력 이미지에 대한 결과 이미지 크기는 CONV 층에서 사용한 공식과 동일하다.
이때, 입력 채널의 수와 결과 채널의 수는 동일한데 풀링은 각 채널에 개별적으로 적용되기 때문이다.
풀링에는 최대 풀링과 평균 풀링 두 가지가 있는데, 보통 최대 풀링을 사용한다.
(1) Max Pooling
f 크기의 필터와 s 크기의 스트라이드를 사용하여 필터 내에서 가장 큰 값을 남기는 연산이다.
이미지의 픽셀 중 특징이 큰 픽셀 값을 남기기 때문에 이미지의 특징을 더 잘 잡아낼 수 있다는 장점이 있다.
결과 이미지의 크기는 CONV층에서 사용한 공식과 동일하다.
(2) Average Pooling
평균 풀링에서는 필터에 해당하는 픽셀의 평균값을 남기는 연산이다.
