
앞에서 아스키 코드와 유니 코드에 대해 공부하던 중 어디선가 자주 본 UTF-8에 대해 궁금증이 생겨 조금 더 알아보았다.
UTF-8 이란?
UTF-8은 유니코드의 여러 방식 중 하나이다. UTF-8 외에도 16, 32 등이 존재한다.
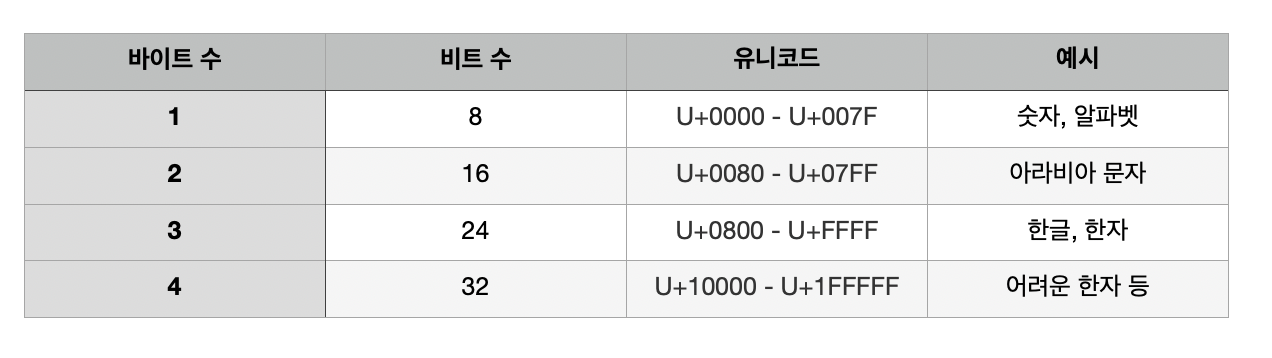
UTF-8은 하나의 문자를 나타내기 위해 1바이트에서 4바이트까지를 사용한다. 예를 들어, U+0000부터 U+007F 범위에 있는 ASCII 문자들은 UTF-8에서 1바이트만으로 표시된다.
그리고 4바이트로 표현되는 문자는 모두 기본 다국어 평면(BMP) 바깥의 유니코드 문자이며, 거의 사용되지 않는다.
UTF-8의 규칙
1. 기본 단위는 1바이트 = 8비트
문자를 위한 비트 수는 반드시 8의 배수가 된다. 이 8비트를 바이트(byte)라고 하며 유니코드의 값에 따라 바이트 수가 정해진다.
2. 바이트의 가장 앞은 고정
비트 열에 1바이트의 문자나 4바이트의 문자가 혼재되어 있어도 괜찮도록, UTF-8에서는 각각의 바이트의 제일 앞이 정해진 패턴을 하고 있다.
1바이트의 문자
제일 앞을 0으로 한다.
예시: 01000001
2바이트의 문자
첫 번째에는 110, 두 번째에는 10으로 한다.
예시: 11000110 10110010
3바이트의 문자
예시: 첫 번째는 1110, 두 번째와 세 번째는 10으로 한다.
3. 유효 비트
고정 숫자를 제외한 부분을 유효 비트라고 하며, 문자를 특정하는 역할을 한다.
예를 들어, 1바이트의 문자인 'A'는 01000001 인데, 제일 앞 고정 값인 0을 제외하면 '1000001' 이 되며 이 부분이 유효 비트이다.
이걸 16진수로 하면 유니코드 부호의 위치가 된다. (U+XXXX)
