검색유형별 로직 설계 (pseudo code)
- 단어형
1. 모든 검색요소에서 해당하는 단어가 존재하는지 찾는다.
- 가중치 적용: 유형(3), 행정구역(3), 제목(2), 하우스 설명(1), 하우스룰(1)
2. 해당된 하우스를 검색요소별 우선순위의 가중치에 따라 계산한다.
3. 가중치 총점이 가장 높은 하우스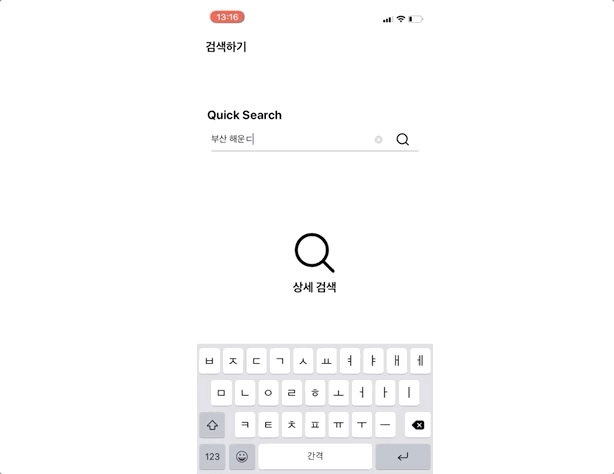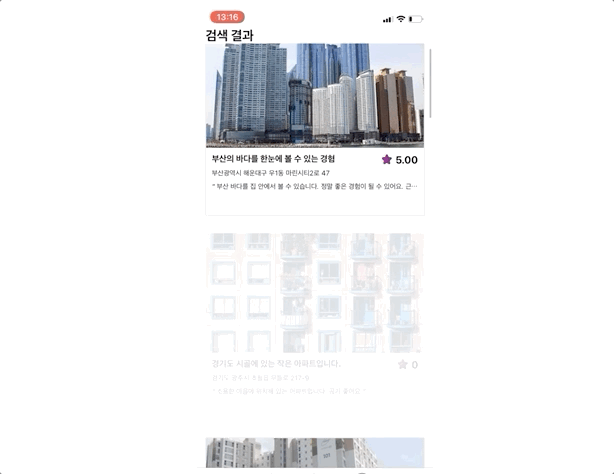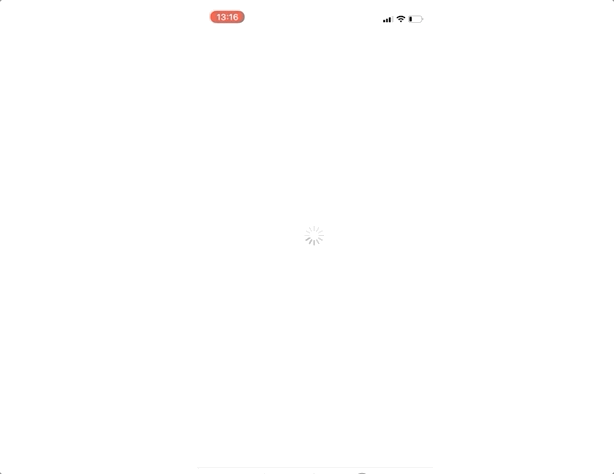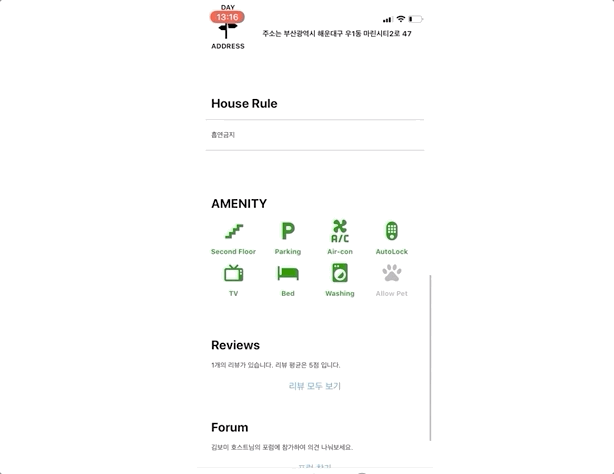부터 정렬하여 유저에게 제시한다.단어형은 ‘부산’, ‘원룸’, ‘루프탑’ 등 하나의 단어이기 때문에 따로 문장의 요소를 분류하는 과정을 거치지는 않는다. 그래서 바로 모든 검색요소에 해당 단어가 포함되어 있는지를 확인하는 작업이 진행된다.
다음, 포함되어 있는 하우스가 나오면 각 하우스를 검색요소별 우선순위의 가중치에 따라 계산한다. 예를 들어 ‘부산’이라는 단어가 유형, 행정구역에 포함되어 있는 하우스는 가중치 총점 6점이 된다.
마지막으로 가중치가 높은 하우스 순으로 정렬하여 사용자에게 제시한다.
- 문장형
1. 검색문장을 띄어쓰기 기준으로 쪼개어 배열로 만든다.
2. 배열의 각 엘리먼트의 문장요소를 구분한다.
- 해운대'에' = 부사어, 뷰'가' = 주어, 좋'은' = 서술어 등
3. 구분된 문장요소별로 모든 검색요소를 찾는다.
- 유형, 행정구역, 제목, 매물설명, 하우스룰
4. 가중치 총점이 가장 높은 매물부터 정렬하여 사용자에게 제시한다.문장형 검색유형의 경우는 먼저 검색문장을 띄어쓰기를 기준으로 쪼개어 배열로 만드는 작업이 진행된다. 그리고 쪼개진 단어들을 앞서 살펴 본 필수 문장요소 분석을 기준으로 어떤 문장 요소인지를 파악하게 된다.
그 예시는 보시는 바와 같이 해운대’에’ 마지막 글자 ‘에’ 가 포함되는 단어는 부사어, ‘가’가 포함되는 단어는 주어 이런방식으로 구분할 수 있다. 파악이 끝난 뒤에는 단어형 검색과 마찬가지로 각 쪼개진 단어를 모든 검색요소에서 찾게 된다.
그리고 부사어로 판별된 단어가 유형에 포함된 하우스가 있다면 부사어 + 유형이기 때문에 총점 6점이 된다. 이런 방식으로 모든 과정이 끝난 뒤에는 가장 총점이 높은 하우스순으로 사용자에게 제시하게 된다.
로직 실행 결과
다음으로 실제로 로직을 실행한 결과이다. 예문인 '부산 해운대에 있는 뷰가 좋은 아파트' 가 각 단어별로 6개로 쪼개어 진 후, 한 단어당 검색요소별로 5번 검색되어 가중치를 적용하게 된다.
그 다음 6개의 단어의 문장요소를 파악하여 각 문장요소 별로 가중치가 다시 한번 적용되는 것을 확인할 수 있다.
모든 가중치 적용작업이 끝난 뒤에는 하우스별 가중치 합계에 따라 검색된 하우스의 총점이 계산되고, 이 결과를 내림차순으로 정렬하여 제일 높은 총점의 하우스부터 유저에게 제공하게 된다.

구동 테스트
그럼 실제 구현된 앱에서 검색로직을 확인해 보도록 하겠다. 아래 gif 이미지를 보면 검색한 문장과 가장 관련성이 높은 하우스이 제일 상단에 위치하게 되고 그 밑으로 유사한 하우스들이 정렬되는 것을 확인할 수 있다.
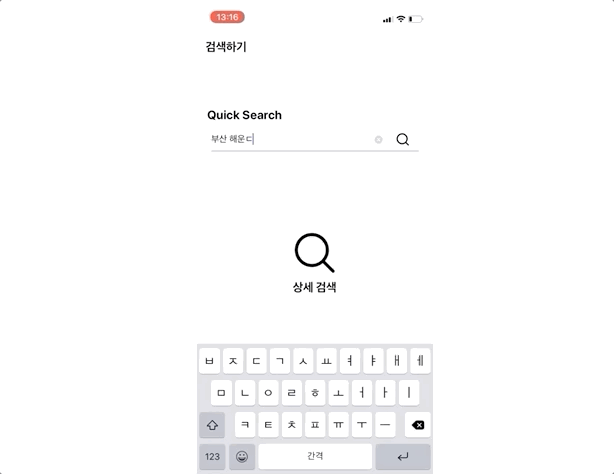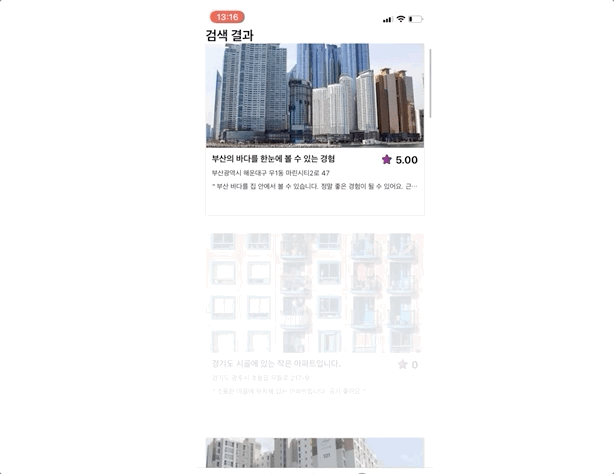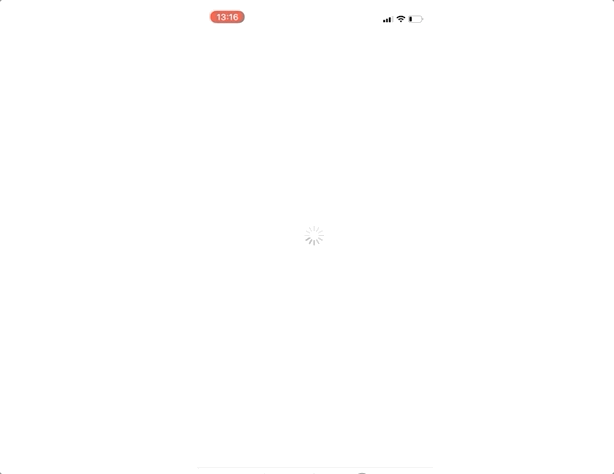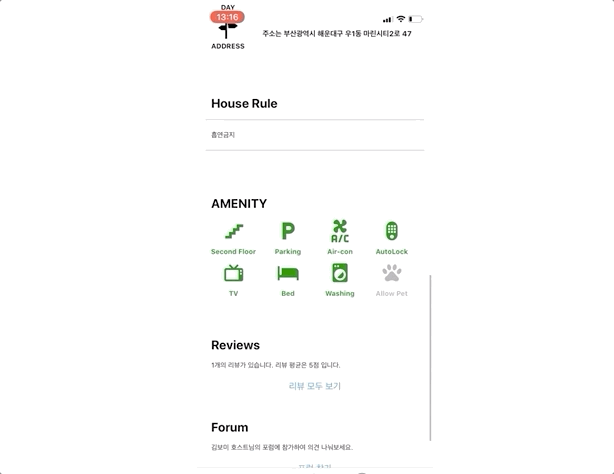
검색 로직을 구현하는 과정에서 느낀 점
- 하우스의 제목에서 일치하는 단어가 있는지 찾는 방식보다 유저 니즈에 적합한 결과물 도출
- TypeORM, Sequelize 등의 ORM의 효율성과 활용성 확인
- 정량적인 분석이 가능하도록 통계자료에 기반한 가중치 설정 필요
- 한국어의 다양한 문장형식을 정규화하여 적용하는 시도 필요
