
Python, SQLAlchemy 기반 프로젝트 작업 중 에러를 해결해 나가는 과정이다.
1. 에러 메세지
ERROR tuple indices must be integers or slices, not str
Traceback (most recent call last):
...
File "C:\Users\Journi\task\igaw_repository\dmp.crawler\commerce\services\commerce_service.py", line 37, in <listcomp>
maker_codes_with_logo = [row['maker_code'] for row in data]
File "lib\sqlalchemy\cyextension\resultproxy.pyx", line 67, in sqlalchemy.cyextension.resultproxy.BaseRow.__getitem__
TypeError: tuple indices must be integers or slices, not str2. 에러 발생 지점
with self.session_scope() as session:
data = session.query(MakerLogos.maker_code).distinct().all()
maker_codes_with_logo = [row['maker_code'] for row in data]3번 째 라인에서 TypeError: tuple indices must be integers or slices, not str 가 발생하였다. DB에서 SELECT 조회해 온 결과를 'maker_code' 로 STR KEY 값으로 가져오지 못하였다.
3. 원인 추측 및 시도
위 코드는 정상 동작하는 코드였다. 구조 개선 작업이었기 때문에 동일한 코드를 제외하면 바뀐 것은 공통 DB 연결 로직 모듈 위치, 프로젝트 환경 뿐이다.
첫 번째 시도
코드를 변경한다. (원인은 모르겠고.. 코드 수정..)
결과 : 에러 없이 코드가 동작하게 되었으나, 기존 코드를 전체적으로 수정해줘야 하는 리소스가 필요하단 단점이 있다.
maker_codes_with_logo = [row[0] for row in data]두 번째 시도
구조를 변경하기 전으로 DB 연결 로직 모듈 위치를 원상복구 하였다.
결과 : 동일한 에러 발생한다. (실패)
세 번째 시도
구조 개선 프로젝트 IDE, 기존 프로젝트 IDE 에서 각각 브레이킹 포인트(라인 3)를 잡고 디버깅하였다.
기존 프로젝트 디버깅
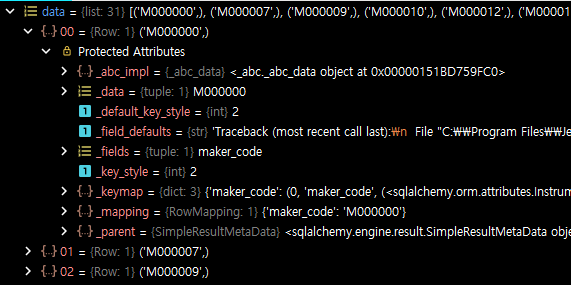
data 변수를 디버깅해보면 [(1111,), (1112), (1113), ] 과 같은 튜플들의 리스트 형식이고, 각 원소는 Row 타입의 Protected Attributes 로만 구성되어 있다. 그 안에는 data, _default_key_style, _fields, _key_style 등이 있다.
구조개선 프로젝트 디버깅
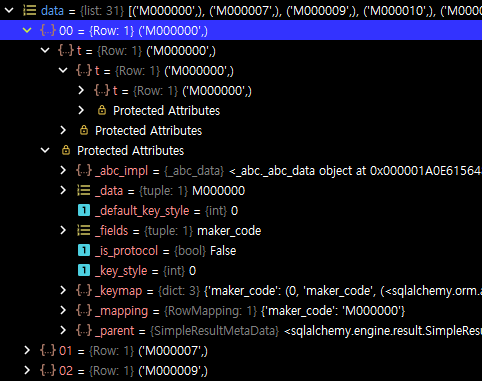
구조 개선 프로젝트에선 디버깅 결과가 달랐다. data 변수를 디버깅해보면 [(1111,), (1112), (1113), ] 과 같은 튜플들의 리스트 형식인 건 동일했으나, 각 원소는 Row 타입의 Protected Attributes 뿐 만아니라 t 라는 Row 가 재귀적으로 구성되어 있다. 그런데 자세히 보면 _key_style 값이 0으로 기존 프로젝트 값과 다른 걸 찾을 수 있다. (기존=2, 구조개선=0)
이걸 키워드로 구글링했으나 적합한 레퍼런스가 없었다. ㅠㅠ 문득 혹시 SQLAlchemy 의 버전이 문제일까 생각이 들었고 두 프로젝트의 Interpreter 구성을 확인해보니 구조 개선 프로젝트 : 2.0.0, 기존 프로젝트 : 1.4.45 버전이었다. 결국 버전이 달라 생긴 문제였다. 버전을 수정해주면 두 프로젝트의 디버깅 결과가 동일하게 작동한다.
4. SQLAlchemy 버전 변경하기
방법 1
Pycham IDE : Setting - interpreter 에서 버전 수정
방법 2
터미널 명령어 : python3 -m pip install sqlalchemy==1.4.45
가상환경 Path 에서 수행하자. (IDE 세팅-인터프리터 경로로 확인가능)
5. Why SQLAlchemy 버전에 따라 이런 일이 발생했을까?
디버깅 했을 때 차이점이 있었던 Row 타입을 깊이 파보자. By [Ctrl + B]
from sqlalchemy.engine import RowRow 클래스에서 주석(# in 2.0, this should be KEY_INTEGER_ONLY)을 보면 2.0 버전의 경우 KEY_INTEGER_ONLY 여야 한다고 한다. 즉, 2.0 버전일 땐 DB 조회한 결과 데이터를 참조할 때 getitem 이 쓰이는데, 이 때 '정수' key 로만 참조가능하다. 는 뜻이다.
class Row(BaseRow, collections_abc.Sequence):
__slots__ = ()
# in 2.0, this should be KEY_INTEGER_ONLY
_default_key_style = KEY_OBJECTS_BUT_WARN다른 상수 값들의 의미도 알아보자
KEY_INTEGER_ONLY = 0
"""__getitem__ only allows integer values, raises TypeError otherwise"""
KEY_OBJECTS_ONLY = 1
"""__getitem__ only allows string/object values, raises TypeError otherwise"""
KEY_OBJECTS_BUT_WARN = 2
"""__getitem__ allows integer or string/object values, but emits a 2.0
deprecation warning if string/object is passed"""
KEY_OBJECTS_NO_WARN = 3
"""__getitem__ allows integer or string/object values with no warnings
or errors."""-
0 : DB 조회한 결과 데이터를 참조할 때 getitem 이 쓰이는데, 이 때 '정수' key 로만 참조가능하다.
-
2 : DB 조회한 결과 데이터를 참조할 때 getitem 이 쓰이는데, 이 때 '정수/문자열/객체' key 로 참조가능하다. 단, 문자열/객체 key 가 들어오면 2.0 deprecation warning 을 발생시킨다.
추측이지만 KEY_OBJECTS_BUT_WARN 은 SQLAlchemy 버전 1일 때와 2에서 범용적으로 해당 상수를 쓰기 위해 탄생한 게 아닐까? 버전 1일 때는 문자/정수/객체를 모두 Key로 쓰고, 버전 2일 때는 정수가 아닌 key 가 들어오면 에러가 발생하도록 제한하도록. (틀린 정보일 수 있습니다.)
6. 코멘트
만약 SQLALCEHMY 버전을 2 이상으로 올린다면 어떻게 마이그레이션해야 할까? SQLAlchemy 버전 1, 2 차이 비동기 DB 쿼리를 날리는 지 여부인 것 같다. 이런 코드 수정을 하지 않은 채로 2.0 버전을 썼으니 오류가 낫을 수도 있겠다.
From:
from sqlalchemy.ext import declarative_base, declared_attr
To:
from sqlalchemy.orm import declarative_base, declared_attr 또한 2.0 마이그레이션을 할 때, SQLALCHEMY_WARN_20=True 로 설정해야 한다고 한다.
SQLALCHEMY_WARN_20 는 기본적으론 False 라서,
2.0 이 아닌 경우, _default_key_style = KEY_OBJECTS_NO_WARN (정수/문자열/객체 가능)
2.0 인 경우 True 설정해주면, _default_key_style = KEY_OBJECTS_BUT_WARN (정수만 가능) 해지는 걸 알 수 있다.
SQLALCHEMY_WARN_20 = False
if os.getenv("SQLALCHEMY_WARN_20", "false").lower() in ("true", "yes", "1"):
SQLALCHEMY_WARN_20 = True
if util.SQLALCHEMY_WARN_20:
_default_key_style = KEY_OBJECTS_BUT_WARN
else:
_default_key_style = KEY_OBJECTS_NO_WARN7. 결론
-
SQLAlchemy 2.0 에선 '정수' KEY 값을 통해,
-
SQLAlchemy 1.0 에선 '정수/문자열/객체' KEY 값을 통해,
-
DB 결과 데이터(튜플 타입들의 목록: ROW)를 조회해와야 한다.
