※ 제수기 시리즈는 '제발수업을기억하자'의 의미를 담고 있으며, 틀린 정보가 담길 수 있습니다.
https://python.langchain.com/docs/tutorials/rag/
추측 : chat GPT에서 오타가 나도 검색이 되는 이유는 store에 단어유사도 벡터로 이뤄졌기 때문이다.. 일까.. ?
환경설정&Document 생성
from dotenv import load_dotenv
load_dotenv()
!pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader('./snow-white.pdf')text_spliteer import RecursiveCharcaterTextSplitter
RecursiveCharcaterTextSplitter 클래스로 스플릿 해보자!
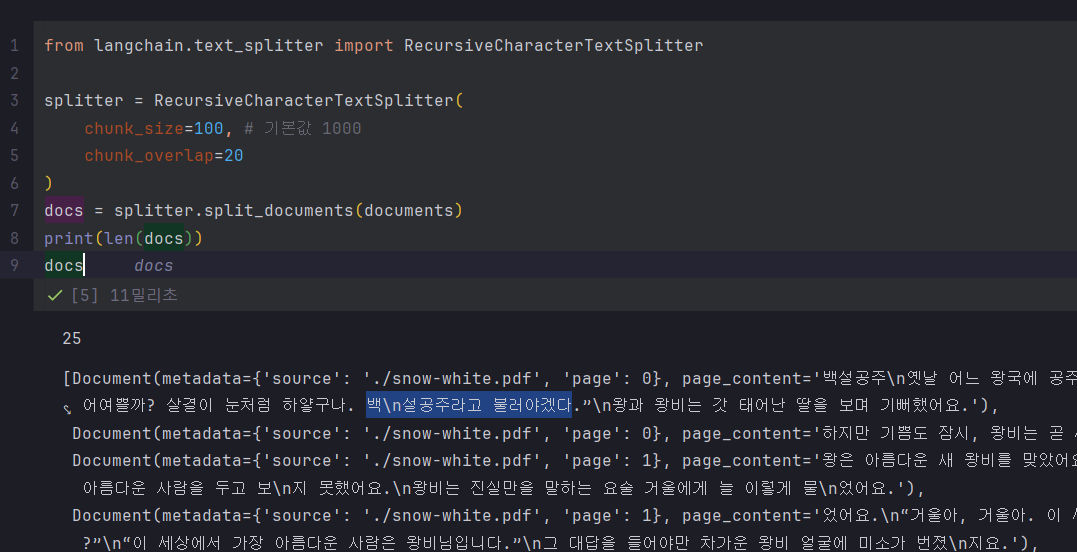
개행문자 때문에 이상하게 스플릿되는 현상이 발생
PDF 불러오자마자 개행문자 제거를 시행
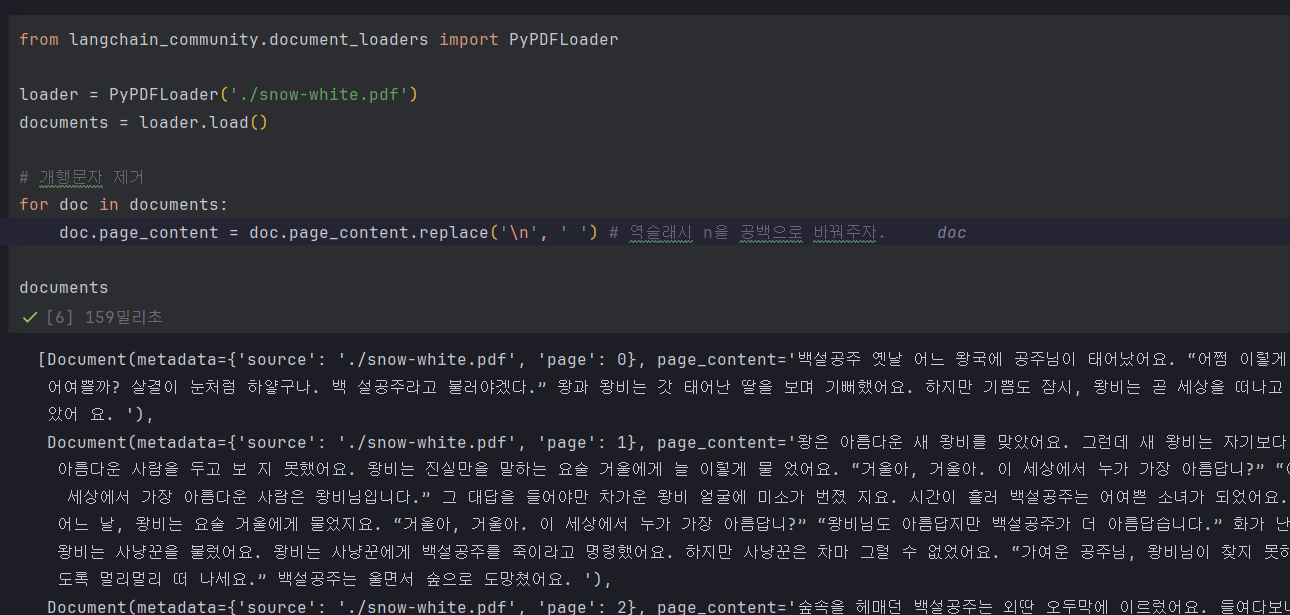
다시 스플릿해보면?
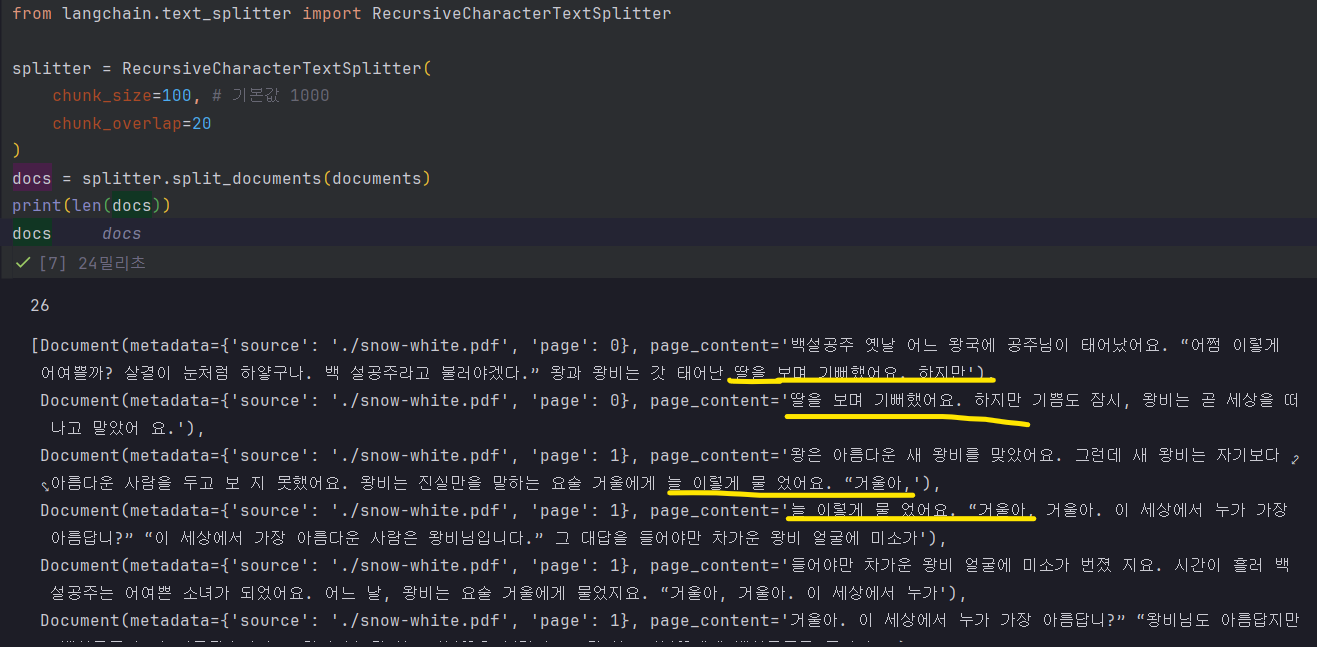
100글자씩 나뉘면서, 조금씩 겹치게 해놨음
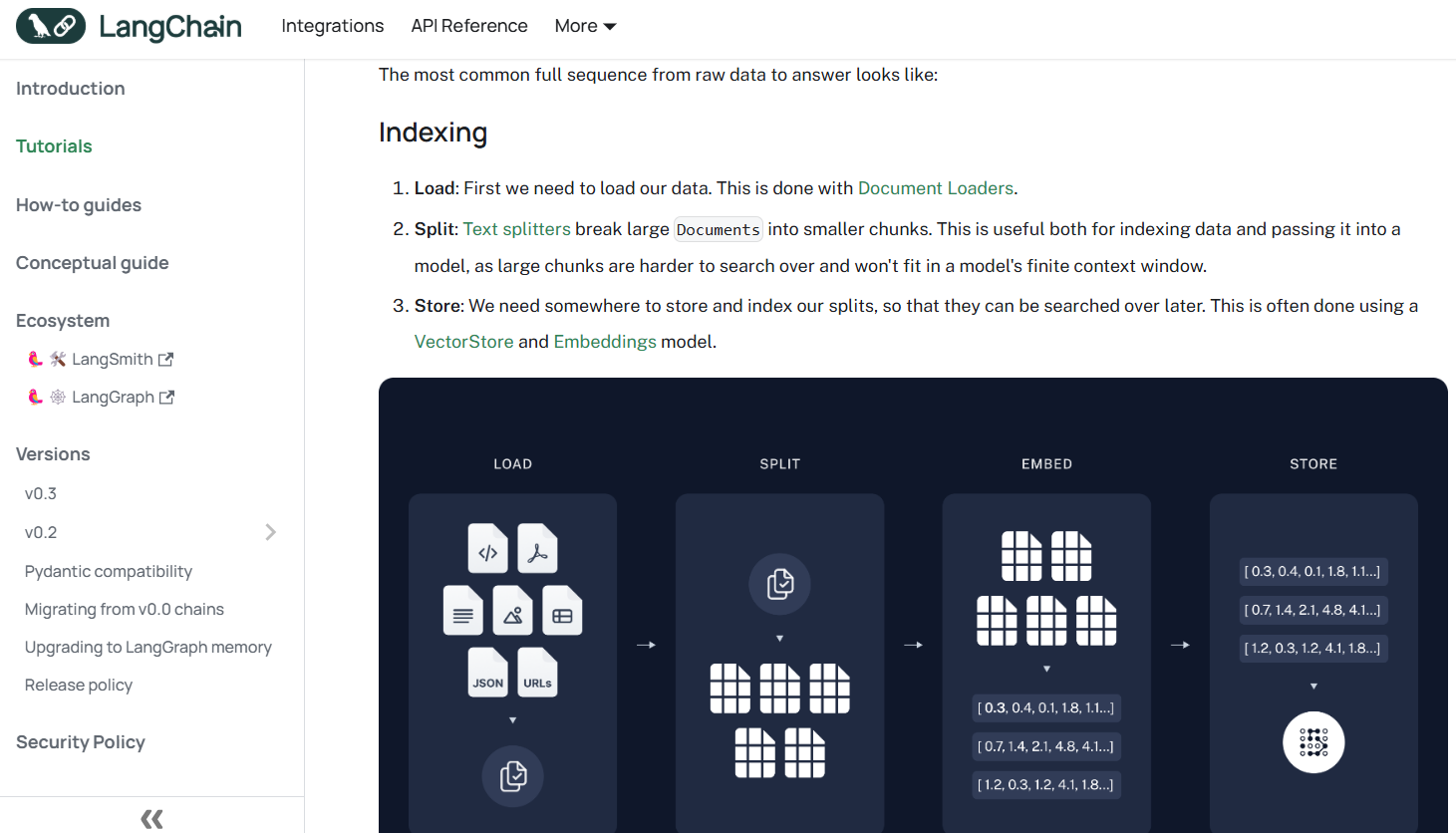
이제 뭘 해야 하나? 벡터화!
Vector Store 직접 조회, Retriever 를 사용한 유사도기반 검색
먼저 Vector Store를 만들고
벡터 스토어에서 직접 조회
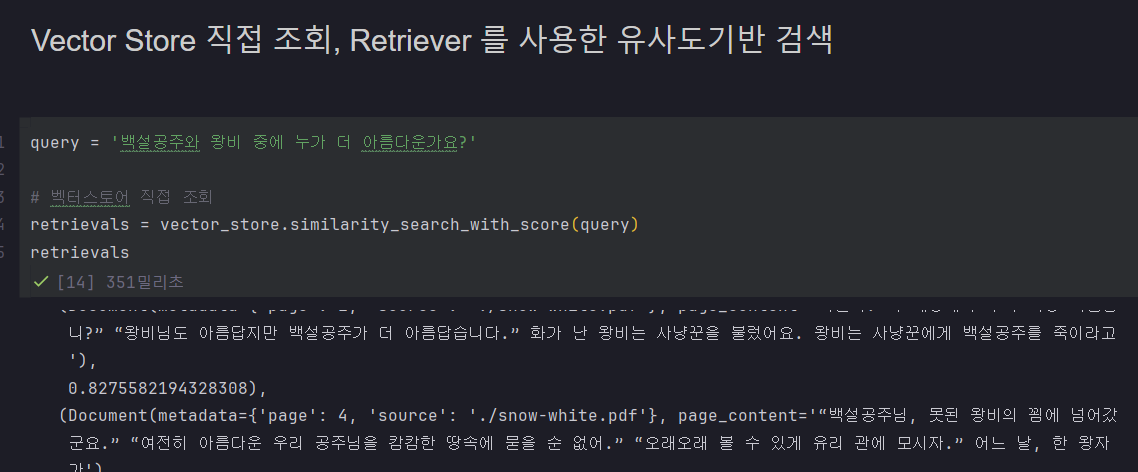
리트리버.
💥search_kwargs={'k':3} 이건 왜 들어간걸까
-> 3개 답변을 달라. 라는 뜻이었다고 한다. top k 라고 읽는다.
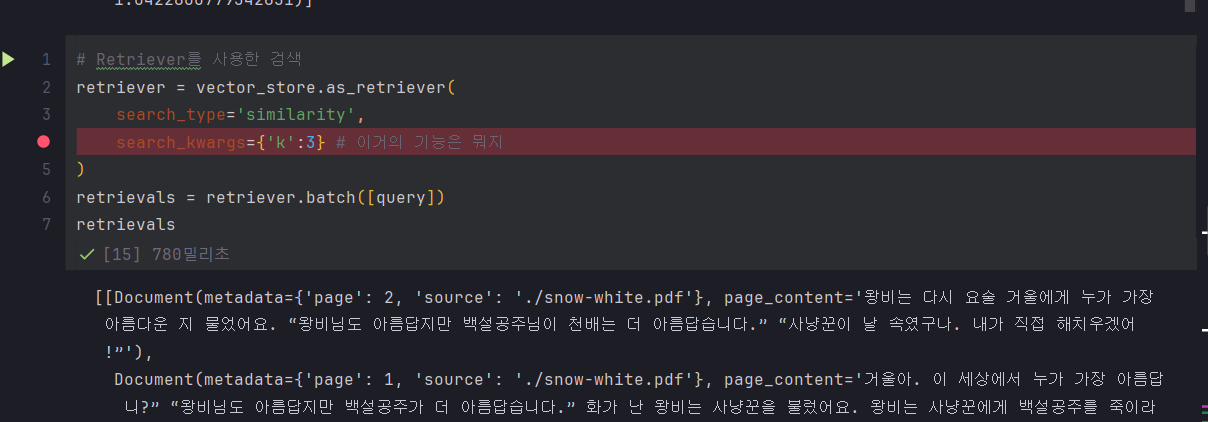
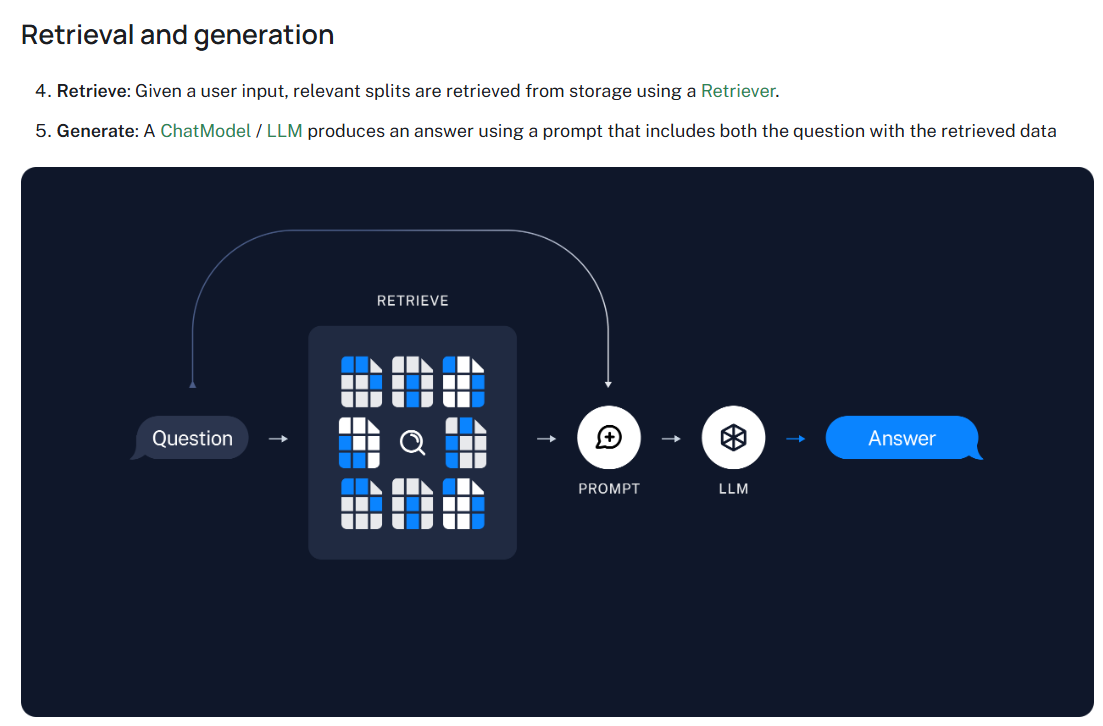
Retrieval and Generation Phase
프롬프트 생성
💥프롬프트 탬플릿, 휴먼메세지 프롬프트 탬플릿에서 벡터 유사도를 비교했다는 건가?
-> 아니다. 그냥 빈 탬플릿을 여기서 만든거고,
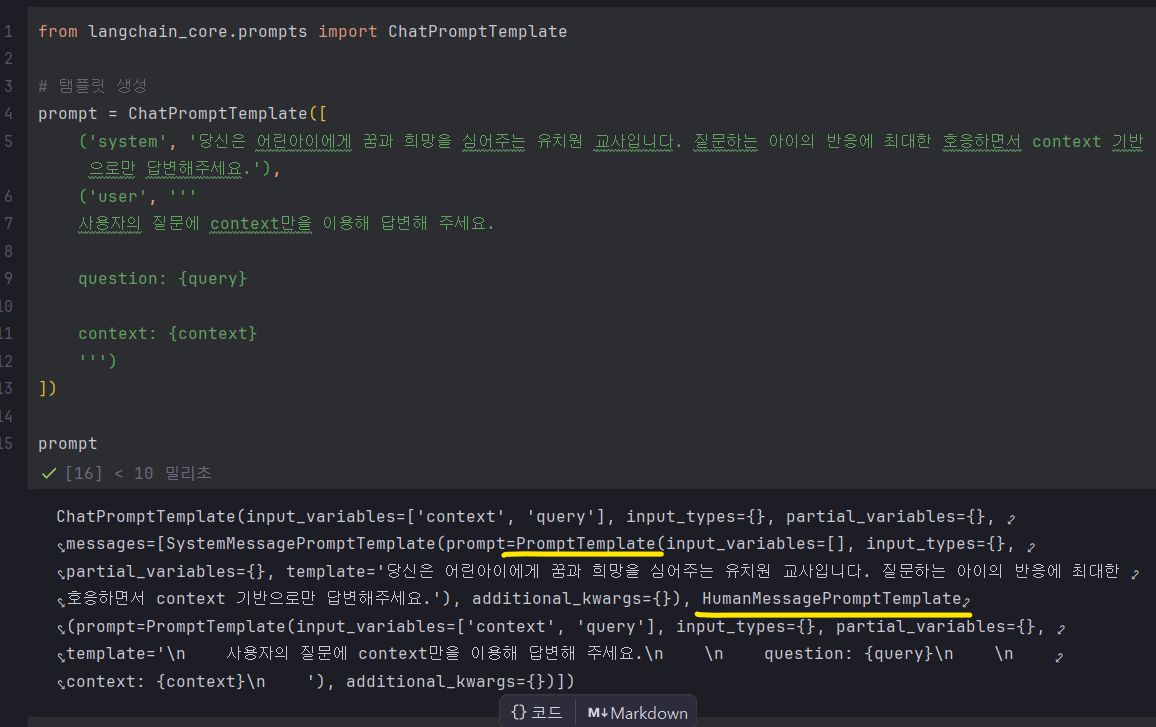
💥아래처럼 바뀐 이유는 뭘까?
-> 쿼리랑 context를 계속 치면서 물어보기 귀찮아서다.
-> 'context' : retriever에서 이미 벡터 유사도를 파악한 context 전달이 마쳐진 거다. 거의 맨 위에 있는 그림 참고.
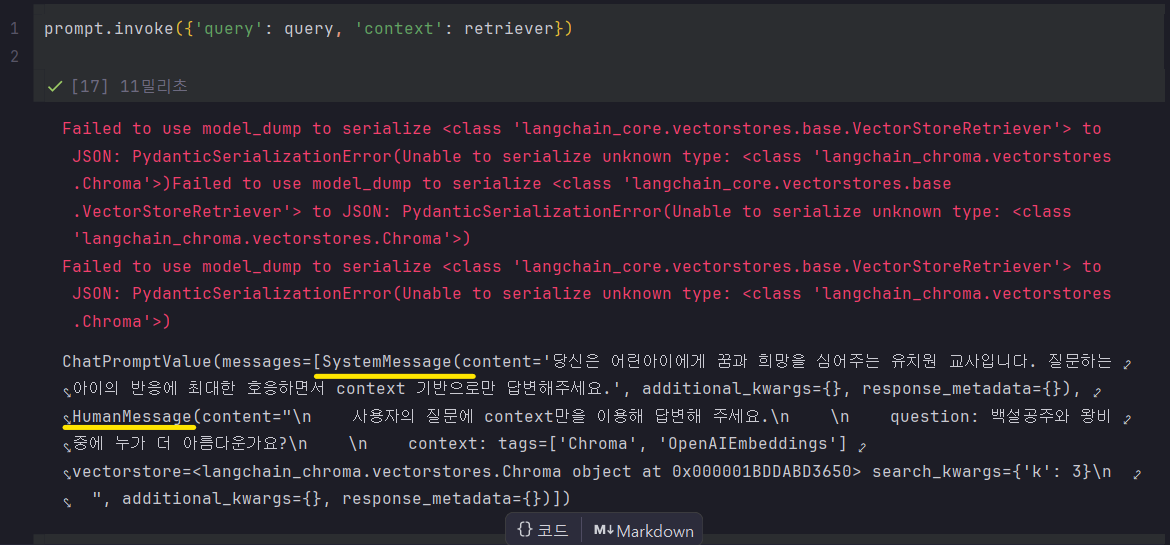
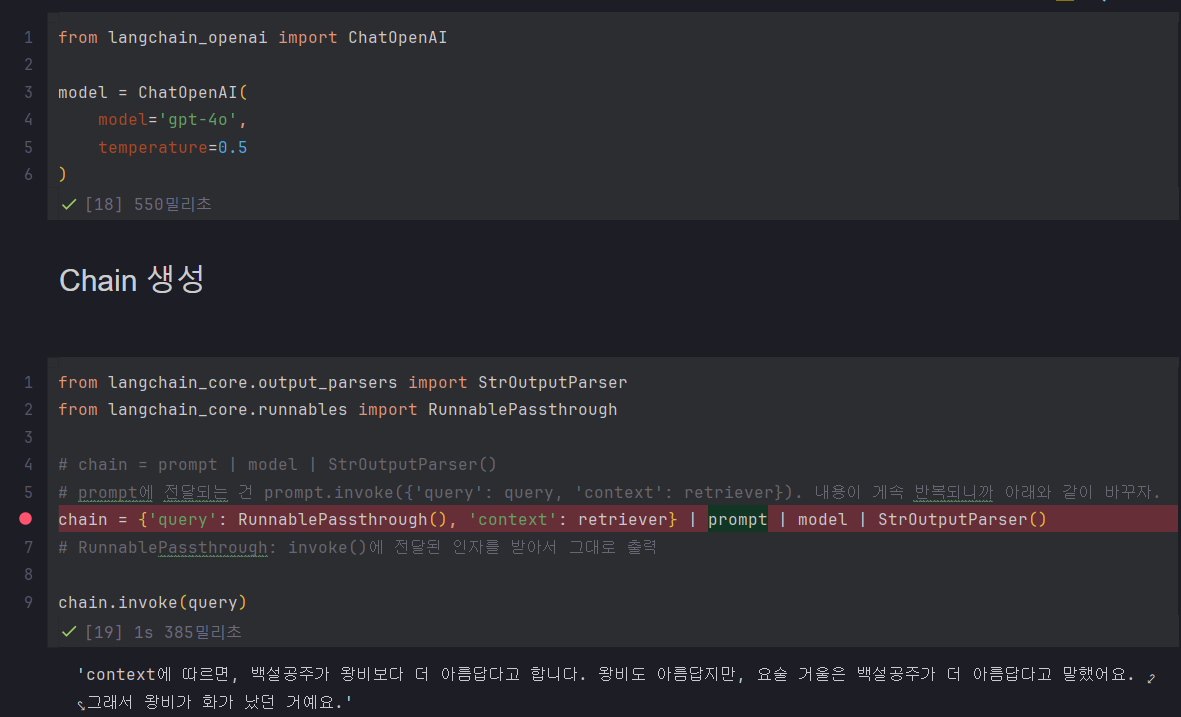
모델과 체인 생성.. 그런데
💥# chain = prompt | model | StrOutputParser()
# prompt에 전달되는 건 prompt.invoke({'query': query, 'context': retriever}).
내용이 게속 반복되니까 아래와 같이 바꾸자.chain = {'query': RunnablePassthrough(), 'context': retriever} | prompt | model | StrOutputParser()
라는 설명이 이해가 안 간다.
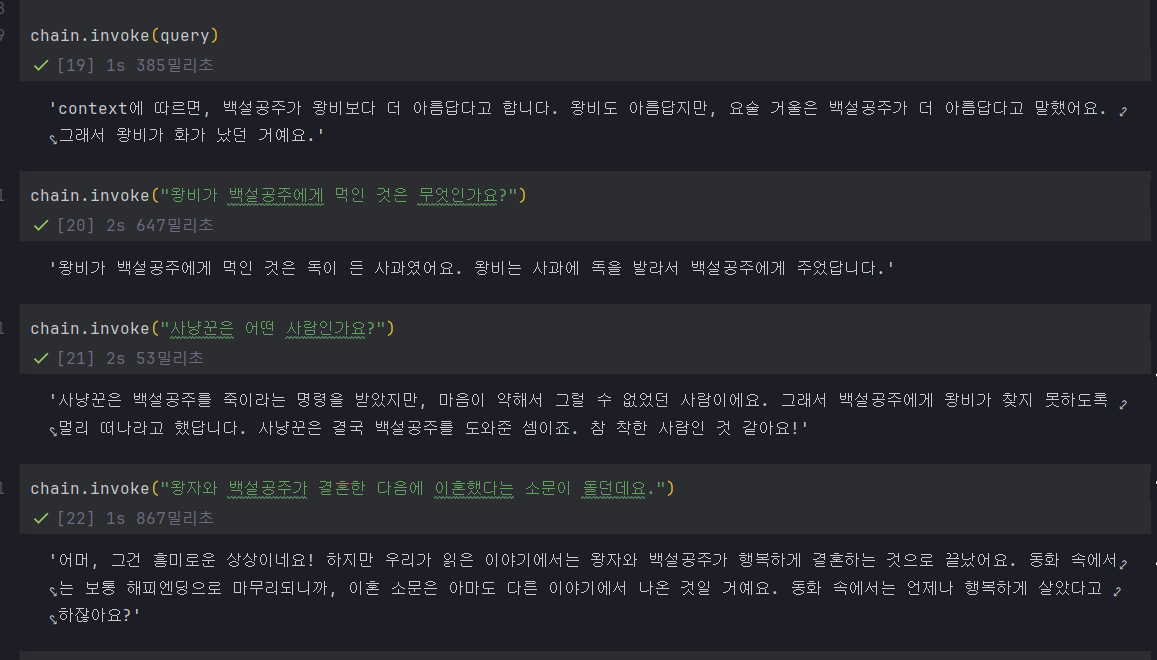
docs에 없는 내용은 흥미로운 상상이라면서 답변해준다. 재밌다.
