인터넷 네트워크
인터넷 망을 통해서 클라이언트와 서버가 연결되어있다. 하지만 이 연결망은 상당히 복잡한데 어떤 규칙을 가지고 데이터를 보내줄까? IP 주소를 부여한다.
IP(Internet Protocol)
- 클라이언트와 서버 모두 IP를 부여받는다.
- 이 지정한 IP 주소에 데이터를 전달한다. 이 때 IP 패킷이라는 통신 단위로 데이터를 전달하게 된다.
- IP 패킷 정보 : 출발지 IP, 목적지 IP, 기타..
IP의 한계
- 비연결성 : 패킷을 받을 대상이 없거나 서비스 불능 상태여도 패킷을 전송한다.
- 비신뢰성 : 중간에 패킷이 사라지거나 패킷이 순서대로 안오는 경우 해결방법이 없다.
- 프로그램 구분 : 한 PC에서 음악도 듣고 게임도 할 때 구분이 어렵다.
TCP, UDP
IP 프로토콜에서 발생했던 문제들을 TCP가 해결해준다.
인터넷 프로토콜 스택의 4계층
- 애플리케이션 계층 : HTTP, FTP
- 전송 계층 : TCP, UDP
- 인터넷 계층 : IP
- 네트워크 인터페이스 계층
*** 패킷 : pack + bucket, 네트워크에서 데이터를 주고받을때 정해놓은 규칙
프로토콜 계층
- 프로그램이 메세지를 작성 ('안녕')
- 소켓 라이브러리를 통해 전달한다.
- TCP 정보를 생성 : 출발지 PORT, 목적지 PORT, 전송 제어, 순서, 검증 정보
- IP 패킷을 생성 : 출발지 IP, 목적지 IP, 기타
TCP(Transmission Control Protocol)의 특징
- 연결지향 : TCP 3 way handshake (가상 연결)
- 클라이언트에서 서버로 SYN이란 접속 요청 보냄- 서버에서 ACK로 요청을 수락하면서 SYN 요청 보냄
- 클라이언트도 ACK로 요청 수락함
- 서로 신뢰관계가 맺어지면 데이터를 전송하게됨.
(근데 이게 물리적으로 연결된건 아님)
- 데이터 전달 보증
- 데이터가 전송되면 잘 받았다는 응답을 해줌 - 순서 보장
- 패킷이 순서대로 오지 않으면 순서가 틀린 부분부터 다시 보내달라고 요청함.
UDP (User Datagram Protocol)
- 연결지향 X, 데이터 전달 보증 X, 순서 보장 X
- 데이터 전달 및 순서가 보장되지 않지만 단순하고 빠르다
- IP와 거의 유사 + PORT + 체크섬 정도만 추가
- TCP보다 가볍고 최적화 커스터마이징 가능하다
PORT
- 같은 IP 내에서 프로세스 구분 (같은 컴퓨터 내에 여러개의 앱이 실행될때 그것을 구분해주는 것)
DNS (Domain Name System)
- IP는 기억하기 어렵다는 단점이 있고, 변경될 수 있다는 단점이 있다.
- DNS 서버에 도메인명과 IP를 등록할 수 있다. 그러면 해당 IP가 변경될 때 변경되고 우리는 그 DNS를 사용한다.
URI와 웹 브라우저 요청 흐름
URI (Uniform Resource Identifier)
- 자원 자체를 식별할 수 있다.
- URI는 로케이터, 이름 또는 둘 다 추가로 분류될 수 있다. (URL, URN)
- Uniform : 리소스 식별하는 통일된 방식
- Resource : 자원 URI로 식별할 수 잇는 모든 것(제한 없음)
- Identifier : 다른 항목과 구분하는데 필요한 정보
URL (uniform resource locator), URN(name)
- 리소스가 있는 위치 지정, 이름을 부여
- 위치는 변할 수 있지만 이름은 변경되지 않음
- 하지만 URN은 도서관 이외에 거의 사용하지 않는다.

- 프로토콜 : 어떤 방식으로 자원에 접근할 것인가 하는 약속 규칙 (http, https, ftp)
- http는 80 포트, https는 443 포트를 주로 사용 가능 => 포트 생략 가능
- userInfo, port 생략가능
- 리소스 경로 (계층적 구조) : members/100 => 멤버 파일에 100번째 멤버 보여줘
- query : key, value 형태이며 ?로 시작, &로 추가한다.
- fragment : html 내부 북마크 등에 사용하지만 서버에 전송하는 정보는 아니다.
웹 브라우저 요청 흐름
- 주소를 검색창에 치면 DNS를 조회하고 웹 브라우저가 HTTP 요청 메세지를 생성하게 된다.
- Socket 라이브러리를 통해 전달한다 (이 때 TCP/IP 연결하고 데이터를 전달한다)
- TCP/IP 패킷을 생성하고 HTTP 메세지를 포함시킨다
- 이 요청 패킷을 던지고 해당 주소에 도달한다.
- 서버에서는 패킷을 다 열어서 내부 메세지를 확인한다.
- 해당 메세지에서 요구한 데이터를 찾고 HTTP 응답 메세지에 담고 응답 패키지를 만든다
- 웹 브라우저에서는 해당 응답 패키지를 열어 화면에 출력한다.
HTTP (HyperText Transfer Protocol)
- 모든 것을 HTTP에 담아서 전송한다.
- 서버간의 데이터를 주고 받을때도 HTTP로 통신한다.
HTTP/1.1 vs HTTP/2
- 우리가 사용하는 대부분의 기능은 1.1일때 다 개발이 되었다.
- 그 이후 버전은 성능 개선에 초점이 맞추어져있다.
- TCP는 HTTP/1.1과 HTTP/2 기반으로 만들어졌다.
- UDP는 HTTP/3를 기반으로 만들었다.
- 현재는 HTTP/3까지 나왔다. 공식 문서에서 업데이트버전 확인하기
클라이언트와 서버 구조
- 이전에는 클라이언트와 서버를 구분하지 않아 문제가 많았다. 하지만 이것을 성공적으로 분리시켰다
- 서버 : 데이터, 비지니스 로직에 집중
- 클라이언트 : UI 그려내는 것과 사용성에 집중
-> 이렇게 분리하면서 독립적으로 성장이 가능해짐.
HTTP 특징 1: 무상태 프로토콜
-
statless : 상태를 유지하지 않음
-
서버가 클라이언트의 상태를 보존하지 않는다
-
장점 : 중간에 다른 서버로 바뀌어도 상관이 없음. (stateful하다면 중간에 다른 서버로 바뀔때 모든 정보를 다 넘겨줘야함. 그래서 상태 유지의 경우 항상 같은 서버가 유지되어야 한다) 그래서 갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있다 👉 무한한 서버 증설 가능
- 스케일 아웃 : 서버를 수평 확장하는 것이 유리하다. -
단점 : 단순한 서비스 소개 화면이라면 상관없지만 로그인처럼 상태를 유지해야하는 경우에 한계가 있다. (일반적으로 브라우저 쿠키, 서버 세션을 사용해서 상태를 유지한다)
- 전송시키는 데이터가 stateless보다 많다.
HTTP 특징 2: 비연결성
- 연결을 유지하는 모델: 클라이언트가 요청을 보내지 않는 경우에도 계속 연결을 유지해 서버 자원을 소모한다는 단점이 있다.
- 연결을 유지하지 않는 모델 : 요청이 올때만 연결을 해 최소한의 자원을 사용.
- 1시간 동안 수천명이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로 매우 작음 -> 서버의 자원을 효율적으로 사용 가능
한계
- TCP/IP 연결을 새로 맺어야하니 3 way handshake 시간이 추가된다.
- 웹 브라우저로 사이트를 요청하면 HTML, JS, CSS, 이미지 등 수 많은 자원이 함께 다운로드 되어야한다.
극복
- HTTP 지속 연결로 문제를 해결 : html 파일을 다 받을때까지 연결을 지속시킴
- HTTP/2, HTTP/3에서 더 많은 최적화가 이루어졌다.
HTTP Method
HTTP API
- Resource : 회원이라는 개념 자체가 리소스이지 회원을 조회하는것이 리소스는 아니다.
- 리소스 식별, URI 계층 구조를 활용한다 => 그럼 조회, 삭제 등의 동작은 어떻게 인식할것인지?
- 리소스와 행위를 분리 => 리소스 : URI(명사) / 행위: 메서드(동사)
HTTP 메서드
- GET, DELETE : payload X
- PUT, PATCH, POST : payload에 요청 담아서 보냄.
GET : 리소스 조회
- 서버에 전달하고 싶은 데이터는 쿼리를 통해 전달
- 메세지 바디를 사용해서 데이터를 전달할 수 있지만, 지원하지 않는 곳이 많음
POST : 요청 데이터 처리
- 대상 리소스가 리소스의 고유한 의미 체계에 따라 요청에 포함된 표현을 처리하도록 요청
- 메세지 바디를 통해 서버로 요청 데이터 전달 (페이로드)
- 메세지 바디를 통해 들어온 데이터를 처리하는 모든 기능 수행
- 응답으로 처리 결과 주소를 넘겨줌 - 주로 등록에 많이 사용, 요청 데이터 처리, 다른 메서드로 처리하기 애매한 경우 사용
예) JSON으로 조회 데이터를 넘겨야하는데 GET 메서드를 사용하기 어려운 경우
PUT : 리소스 대체 (해당 리소스 없을때 생성)
- 리소스가 있으면 대체, 없으면 생성 (쉽게 이야기해서 덮어버림)
- 즉, 리소스를 완전히 대체한다 === 전체 정보를 넘겨줘야한다. (기존 리소스 다 삭제됨) - 클라이언트가 리소스를 식별한다.
- 클라이언트가 member/100번째라고 딱 지정을해서 put의 경우는 알고있음- 하지만 post는 모름(어디에 지정될 지)
PATCH : 리소스 부분 변경
- 리소스 부분 변경 (PUT의 단점 보완)
- 지원 안되는 경우도 있음 -> 이때는 POST 사용하기
DELETE : 리소스 삭제
- 리소스 제거
OPTIONS : 대상 리소스에 대한 통신 가능 옵션 설정(CORS)
HTTP 메서드 속성
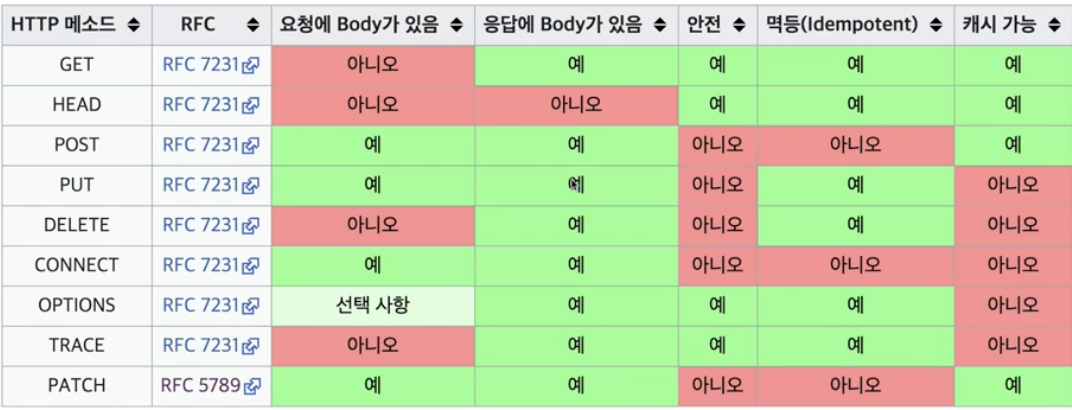
-
안전 : 호출해도 리소스를 변경하지 않는다 (GET)
- 변경이 한 번이라도 일어나면 안전하지 않음
- 계속 호출해서 로그가 쌓여 장애가 발생하는것까지는 고려하지않음
-
멱등 : idempotent
-
몇 번을 호출해도 똑같은 결과가 도출된다.
-
활용 : 자동 복구 메커니즘 (서버가 timeout 등으로 정상 응답을 못주었을때 클라이언트가 같은 요청을 다시 해도 되는가?의 판단 근거)
-
다만, 외부 요인으로 리소스가 변경되는것은 고려하지 않는다.
-
GET : 조회 결과는 항상 같다.
-
PUT : 결과를 대체하기때문에 같은 요청을 여러 번해도 결과는 같다
-
DELETE: 같은 요청을 여러번해도 삭제된 결과는 똑같다.
(post는 멱등이 아니다. 두 번 호출하면 같은 결제가 중복되어 발생한다)
-
-
캐시가능
- 응답 결과를 캐시할 수 잇는가 여부
- 똑같은 결과를 계속 요청하지않아도 됨
- GET, POST, PATCH 가능하지만 주로 GET만 캐시 사용
- POST, PATCH 본문 내용까지 캐시키로 고려해야해 구현이 어려움.
클라이언트에서 서버로 데이터 전송
데이터 전달 방식
- 쿼리 파라미터를 통한 데이터 전송
- GET
- 검색어, 정렬 필터 경우 많이 사용
- 메세지 바디를 통한 데이터 전송
- POST, PUT, PATCH
- 회원 가입, 상품 주문, 리소스 등록 및 변경
4가지 상황
- 정적 데이터 조회 : 이미지, 정적 텍스트 문서
- 동적 데이터 조회 : 주로 검색, 게시판 목록에서 정렬 필터(검색어)
- HTML FORM 데이터 전송
- GET, POST만 지원한다.
- POST 전송 저장 (리소스 변경이 발생하는 곳에 사용)
- 전송 데이터를 url encoding 처리한다 utf8형태 (abc김 -> abc%EA%B9%80)
- HTTP API 데이터 전송
- 직접 만들어서 다 넘기면된다.
- 서버 to 서버 통신 / 앱 클라이언트 / 웹 클라이언트
- AJAX 통신일때 많이 사용- POST, PUT, PATCH도 사용가능
HTTP 상태 코드
- 100 (Informational) 요청이 수신되어 처리중
- 200 (Successful) 요청 정상 처리
- 300 (Redirection) 요청을 완료하려면 추가 행동 필요
- 400 (Client Error) 클라이언트 오류, 잘못된 문법등으로 서버가 요청을 수행할 수 없음
- 500 (Server Error) 서버 오류, 서버가 정상 처리를 못함.
200 Successful

- 200 OK : 요청 성공
- 주로 많이 사용 - 201 Created : 요청이 성공해서 새로운 리소스가 생성됨
- POST의 경우 서버에서 자원을 만들고 그것을 페이로드에 싫어서 보냄 - 202 Accepted : 요청이 접수되었으나 처리가 완료되지 않음
- 요청 점수 후 1시간 후에 배치 프로세스가 요청됨 - 204 No Content : 서버가 요청을 성공적으로 수행했지만, 응답 페이로드 본문에 보낼 데이터가 없을때
- 웹 문서 편집기에서 save 버튼
300 Redirection
리다이렉션의 이해
*** Redirection : 웹 브라우저는 300번대 응답 결과에 location 헤더가 있으면 location 위치로 자동 이동을 한다.
- 영구 리다이렉션 : 특정 리소스의 URI가 영구적으로 이동 => 301, 308
- 일시 리다이렉션 : 일시적 변경 (주문 완료 후 주문 내역 화면으로 이동)
- 특수 리다이렉션 : 결과 대신 캐시를 사용
영구 리다이렉션
- 301 Moved Permanently
- 리다이렉트시 요청 메서드가 get으로 변하고 본문이 제거될 수 있음(MAY) - 308 Permanent Redirect
- 301과 기능은 같지만 리다이렉트시 요청 메서드와 본문을 유지한다.
일시적 리다이렉션
- 302 Found
- 리다이렉트시 요청 메서드가 GET으로 변하고 본문이 제거될 수 있음(MAY)- 명확하지 않음!
- 307 Temporary Redirect
- 리다이렉트시 요청 메서드와 본문 유지 (MUST NOT) - 303 See Other
- 리다이렉트시 요청 메서드가 GET으로 명확하게 변경
=> 꼭 필요한 경우 : PRG(Post Redirect GET)
- POST로 주문후에 웹 브라우저를 새로고침시 중복 주문이 될 수 있음.
- 해결하기위해 PRG 사용
400 클라이언트 에러, 500 서버 에러
400 Client Error
-
오류의 원인이 클라이언트에 있어 이미 잘못된 요청을 여러번 보내고있기때문에 똑같은 재시도는 계속 실패함
-
잘못된 문법등의 오류로 서버가 요청을 수행할 수 없음
-
400 Bad Request
- 요청 구문, 메세지 등의 오류 (API 스펙 맞지 않거나 요청 파라미터가 잘못된 경우) -
401 Unauthorized
- 인증이 되지 않았다는 오류- 응답에 WWW-Authenticate 헤더와 함께 인증 방법을 설명
*** 인증 (로그인) vs 인가(권한 부여 -> 특정 리소스에 접근 가능)
- 응답에 WWW-Authenticate 헤더와 함께 인증 방법을 설명
-
403 Forbidden
- 서버가 요청을 이해했지만 승인을 거부함- 주로 인증 자격 증명은 있지만 접근 권한이 불충분한 경우
- 어드민 등급이 아닌 사용자가 로그인해서 어드민 리소스 보려고할 때 나는 에러
-
404 Not Found
- 요청 리소스가 서버에 없음- 또는 클라이언트가 권한이 부족한 리소스에 접근할 때 해당 리소스를 숨기고 싶을 때
500 Server Error
-
서버 문제로 오류 발생
-
데이터가 복구되면 똑같은 재시도의 성공 가능성이 있음
-
500 Internet Server Error : 서버 내부 오류(거의 이경우)
-
503 Service Unavailable : 언제 복구되는지 보냄
협상 (content Negotiation)
클라이언트가 선호하는 표현 요청
- 구체적인것이 우선한다
- 우선순위가 높은것을 선택한다 (0~1 중 클수록 높은 순위)
- 구체적인 것을 기준으로 미디어 타입을 맞춘다. 1) Accept : 클라이언트가 선호하는 미디어 타입 전달
2) Accept-Charset : 클라이언트가 선호하는 문자 인코딩
3) Accept-Language : 클라이언트가 선호하는 언어
- 다중 언어 지원 서버이지만 내가 원하는 언어가 없을때 나의 우선순위가 높은 것을 선택
4) Accept-Encoding : 클라이언트가 선호하는 압축 인코딩 (utf-8)
전송 방식
- Content-Length : 길이를 정해 단순히 전송
- Content-Endcoding : 무엇으로 압축되었는지 정보 주면서 전송
- Transfer-Encoding : chunked
- 용량이 큰 경우 보내면 시간이 많이 걸리는데 쪼개서 보내면 효율적인 시간관리
- Content-Length 정보 안보냄 (애초에 모르니까)
- Content-Range : 범위를 지정해서 리소스 받음
인증
- Authorization : 클라이언트 인증 정보를 서버에 전달
- WWW-Authenticate : 리소스 접근시 필요한 인증 방법 정의
쿠키
- Set-Cookie : 서버에서 클라이언트로 쿠키 전달 (응답)
- Cookie : 클라이언트가 서버에서 받은 쿠키를 저장하고 HTTP 요청시 서버로 전달한다.
- 광고 정보 트래킹, 사용자 로그인 세션 관리 등에 사용
- 세션 쿠키 : 만료 날짜 생략시 종료시까지만 유지
- 영속 쿠키 : 만료 날짜 입력시 해당날짜까지 유지
- 쿠키는 도메인 명시 가능 (명시한 문서 기준 도메인 + 서브 도메인 포함)
문제 및 해결
1) 문제 - 모든 요청에 쿠키 정보가 자동 포함된다.
- 네트워크 트래픽 추가 유발
2) 해결 - 최소한의 정보만 사용 (세션 id, 인증 토큰)
- 서버에 전송하지않고 웹 브라우저 내부에 데이터 저장하고 싶을 때 웹 스토리지 사용
캐시
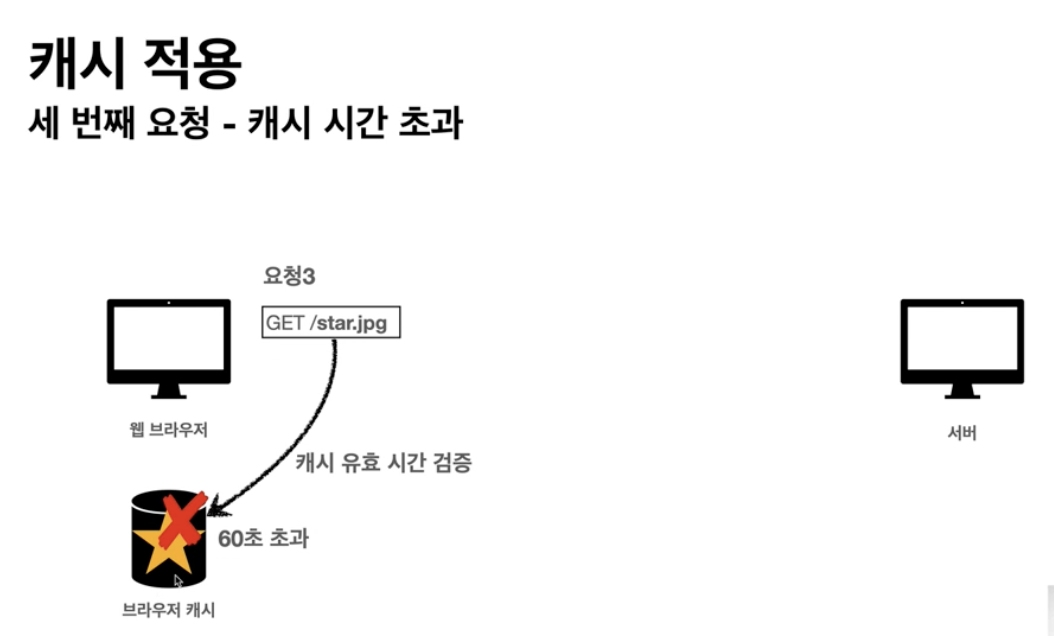
- 캐시가 없을 때
- 브라우저 로딩 속도 느리다 -> 느린 사용자 경험- 인트넷 네트워크는 매우 느리고 비싸다
- 캐시 적용
- 캐시가 유효한 시간 동안 네트워크 사용하지 않아도 됨- 빠른 사용자 경험
- 캐시 시간이 초과되었을대 응답 결과를 다시 캐시에 저장(캐시 초기화)
-> 서버를 통해 데이터를 다시 조회하고 업데이트해야한다.
프록시 캐시
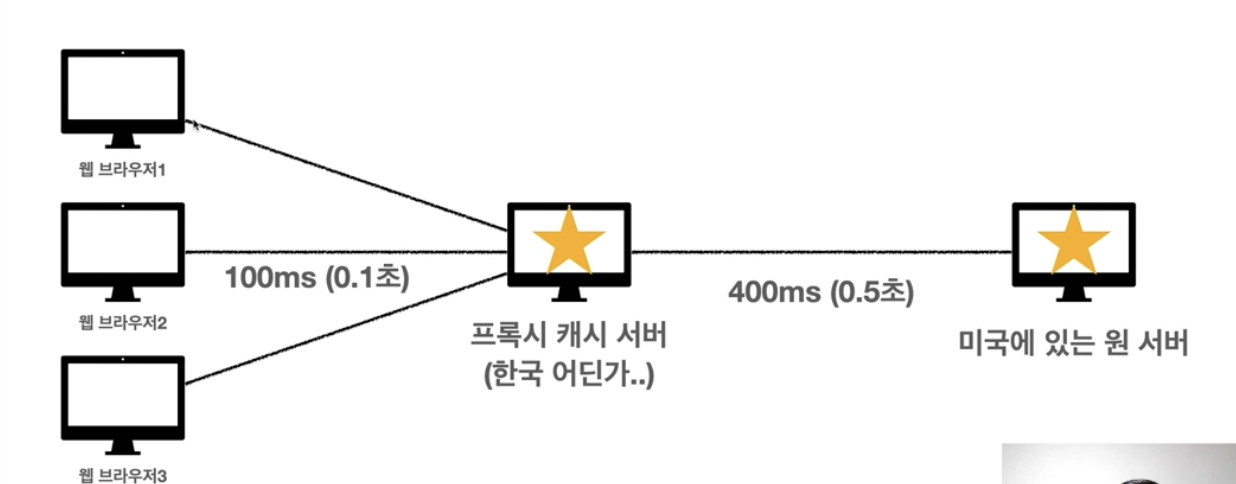
- origin 서버와 달리 중간 프록시 캐시 서버를 둠
- 최초 요청할때는 없지만 두번째부터는 빨라짐
- 프록시 캐시 서버 : 중간에 컨트롤하는 서버
Word Cited
