📐 문제 상황
이번 프로젝트에서는 "외출하기 전 체크해야 할 정보들을 한눈에!"라는 기획의도와 걸맞게 다루어야 하는 데이터들이 많았다. 다음은 정보 제공을 위해 팀이 수집한 데이터이다.
- 기온
- 강수확률
- 습도
- 바람
- 하늘상태 (맑음, 구름많음 여부)
- 미세먼지
- 코로나 확진자 수
- 자외선 지수
- 꽃가루 농도지수
- 식중독 위험지수
- 천식폐질환 지수
가장 핵심적인 문제는 "기상 데이터 테이블들을 어떻게 설계할 것인가?" 였다. 이 문제가 발생한 이유는 다음과 같다.
(코로나 확진자수 데이터는 엄밀하게 따지면 기상데이터는 아니다. 이 때문에 실제 코딩 시 변수는 TotalData로 사용하였지만, 이 글에서는 이해를 돕기 위해 기상데이터라 명명하겠다.)
- 기온, 강수확률, 코로나, 미세먼지 등 서로 다른 종류의 데이터들이 많다. 이들은 서로 다른 테이블에서 관리된다.
- 하지만 특정 쿼리로 기상 데이터 요청 시에 한 번에 내려주어야 하는 데이터이기 때문에 기온, 강수확률, 코로나, 미세먼지 등 여러 기상 데이터 테이블들간의 연관관계 설정을 잘 해주어야 한다.
- 따라서 연관관계의 기준이자 중심이 될 테이블을 설계하는 것이 핵심이다.
📄 기준 테이블 설계
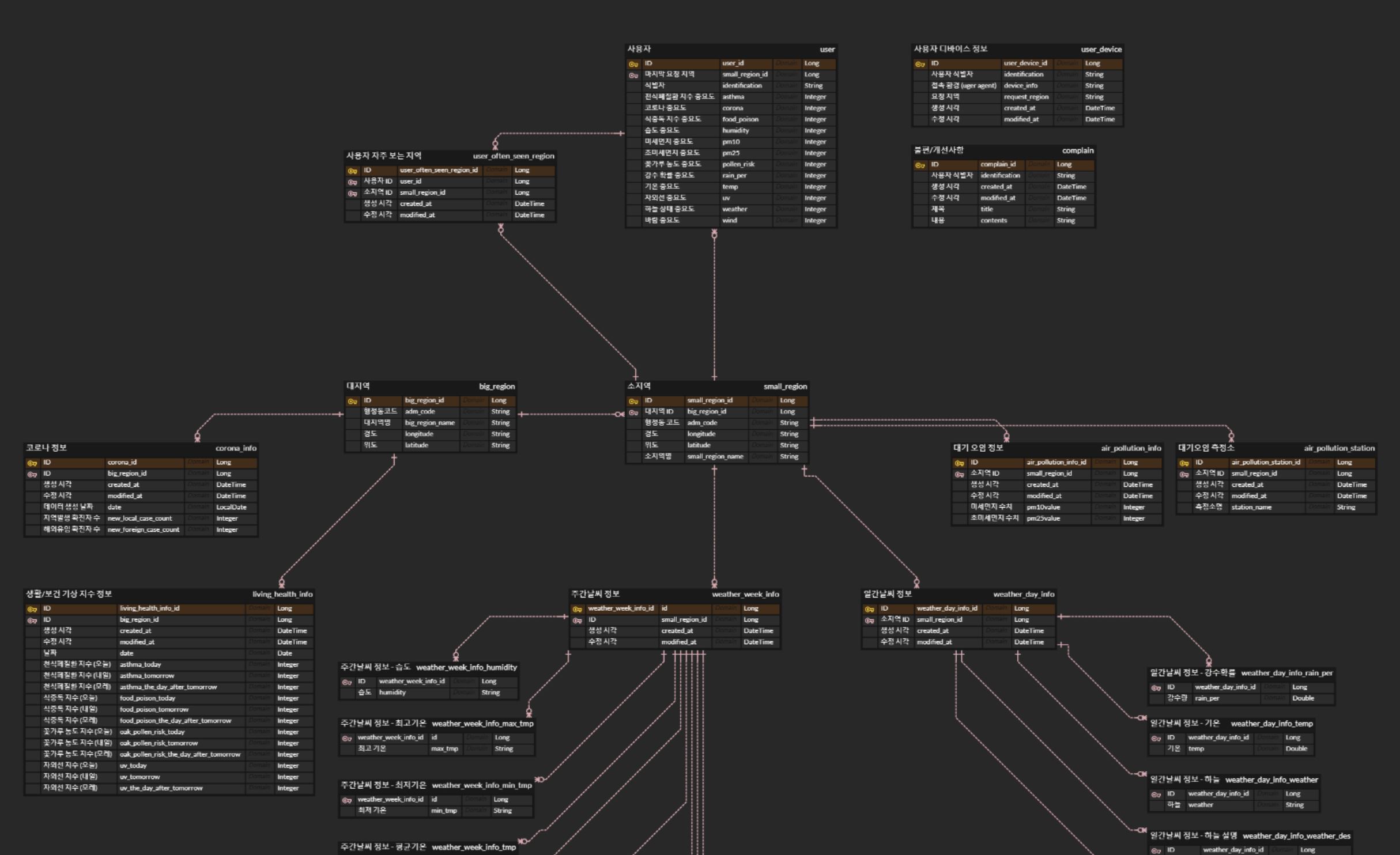
STEP 01. 지역 테이블 설계 초안
기상 데이터를 어떤 파라미터로 요청하는가? 라는 질문에서 출발했다. 기상앱에 들어가게 되면 현재 위치를 기준으로 기상 데이터를 받아온다. 위경도 값 또는 지역구 이름이 파라미터가 되는 것이다. 따라서 기상데이터 연관관계의 기준이 될 테이블을 지역(Region) 테이블로 결정하였다.
그렇다면 이 지역(Region) Table은 어떻게 생겨야 할까? 라는 질문이 꼬리를 물고 이어졌다. 가장 단순하게는 id 값과 region_name으로 구성된 지역 테이블을 만들 수 있겠다. 그리고 해당 열마다 기상 데이터들이 foreign key로 관리되면 되지 않을까란 생각을 했다.
그렇게 단숨에 짠 단순한 지역(Region) 테이블 생김새는 다음과 같다.

하지만 이렇게 단순하게 진행할 경우 기상데이터의 특성 때문에 데이터 베이스가 지저분해진다.
서울특별시, 경기도 등 특별시, 광역시, 도 단위(큰 지역단위)로 불러오는 데이터가 있고,
마포구, 양천구, 하남시, 정선군 등 일반시, 구, 군 단위(작은 지역단위)로 불러오는 데이터가 있다.
이때, 지역(Region) 테이블을 위와 같이 관리하면 작은 지역단위로 불러오는 데이터는 문제가 없다. 불러오는 데이터가 하나의 지역(Region) 테이블 행에 정확히 맵핑되기 때문이다.
예시: 위의 지역(Region) 테이블에서 작은 지역단위로 불러오는 데이터인 미세먼지 수치는 각 행이 겹치지 않게 air_pollution_id를 가진다.
다만, 큰 지역단위로 불러오는 데이터의 처리에 문제가 있었다.
예를들어, "서울특별시"에 해당하는 일일 코로나 확진자 수는 지역(Region) 테이블의 여러 행에 중복으로 맵핑되어야 한다. "서울특별시 마포구", "서울특별시 양천구" 등 모든 "서울특별시 00구" 행에 맵핑된다.
예시: 위의 지역(Region) 테이블에서 큰 지역단위로 불러오는 데이터인 코로나 확진자 수는 각 행이 동일한 coronaInfo_id를 가지는 상황이 생긴다.
물론 중복값을 넣어서 관리할 수도 있겠지만, 깔끔하지 못하다.
기준이 되는 테이블은 연관관계를 설정함에도 중요하지만, 이 값을 활용해 Open Api를 요청하는 데에도 쓰이기 때문에 기존의 단순한 지역(Region) 테이블 형태에서 발전이 필요하다.
STEP 02. 지역 테이블 설계 개선
기존 테이블에서 조금 더 사용성 및 형태가 개선된 테이블을 만들기 위해서는 다음과 같은 조건을 만족해야 한다.
- 큰 단위의 지역명과 작은 단위의 지역명이 분리되어 관리 되어야 한다.
- 분리했을 경우, 큰 단위의 지역명과 작은 단위의 지역명이 연관관계를 맺고 있어야 한다.
이 두 가지를 만족하는 지역(Region) 테이블 설계를 채택했다.
가장 큰 변화는 역시 지역(Region) 테이블을 두 개로 나눈 점이다. 큰 단위의 지역명을 관리하는 BigRegion 테이블, 작은 단위의 지역명을 관리하는 SmallRegion 테이블로 기준 테이블을 구성했다.
이렇게 테이블을 분리하며, SmallRegion이 하나의 BigRegion 객체를 가지게 맵핑하였다. 예를 들어, smallRegionName이 "마포구"인 SmallRegion 객체는 bigRegionName이 "서울특별시"인 bigRegion 객체를 foreign key로 가지도록 만들었다.
채택한 테이블 구조는 다음과 같다. 아래는 외출난이도 서비스의 실제 지역 테이블이다.
BigRegion

SmallRegion

이상으로 총 250개의 smallRegion을 서비스한다. (대한민국 전역)
주제와는 조금 벗어난 이야기지만, 지역 데이터는 서버가 시작할 때 자동으로 지역 테이블을 검사하여 지역 데이터가 DB에 있다면 데이터를 유지한다. 만약 지역 데이터가 없다면 프로젝트 디렉토리내 region.csv 파일에 존재하는 지역 데이터를 파싱해와 자동으로 DB에 업데이트 하도록 하였다.
🤔 bigRegion, smallRegion 테이블을 기준으로 기상 데이터 관리
같은 Open Api를 사용해 불러올 수 있는 데이터를 기준으로 테이블을 구성했다.
기상 데이터 테이블명은 다음과 같이 관리된다. Open Api로 불러온 정보들을 담은 엔티티 클래스는 Info로 끝나도록 통일하였다.
- airPollutionInfo - 미세먼지 수치
- coronaInfo - 일일 코로나 확진자 수
- livingHealthInfo - 자외선지수, 꽃가루농도지수, 식중독위험지수, 천식폐질환지수
- weatherDayInfo - 하루 동안의 시간별 데이터 : 기온, 강수확률, 습도, 바람, 하늘상태
- weatherWeekInfo - 주간 데이터: 기온, 강수확률, 습도, 바람, 하늘상태
- 기온 - smallRegion 단위로 요청
- 강수확률 - smallRegion 단위로 요청
- 습도 - smallRegion 단위로 요청
- 바람 - smallRegion 단위로 요청
- 하늘상태 (맑음, 구름많음 여부) - smallRegion 단위로 요청
- 미세먼지 - smallRegion 단위로 요청
- 코로나 확진자 수 - bigRegion 단위로 요청
- 자외선 지수 - bigRegion 단위로 요청
- 꽃가루 농도지수 - bigRegion 단위로 요청
- 식중독 위험지수 - bigRegion 단위로 요청
- 천식폐질환 지수 - bigRegion 단위로 요청
이제 각 테이블들은 요청 단위에 따라 각 지역 객체와 연관관계를 가지게 된다.
smallRegion 단위로 요청하는 미세먼지 수치의 entity 클래스 코드는 다음과 같다.
@Getter
@Setter
@NoArgsConstructor
@Entity
public class AirPollutionInfo extends Timestamped {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "air_pollution_id")
private Long id;
@JsonIgnore
@ManyToOne
@JoinColumn(name = "small_region_id")
private SmallRegion smallRegion;
@Column
private LocalDateTime dateTime;
@Column
private Integer pm10Value;
@Column
private Integer pm25Value;
...
}bigRegion 단위로 요청하는 코로나 일별 확진자 수 entity 클래스 코드는 다음과 같다.
@Getter
@Setter
@NoArgsConstructor
@Entity
public class CoronaInfo extends Timestamped {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "corona_id")
private Long id;
@JsonIgnore
@ManyToOne
@JoinColumn(name = "big_region_id")
private BigRegion bigRegion;
@Column
private LocalDate date;
@Column
private Integer newLocalCaseCount;
@Column
private Integer newForeignCaseCount;
...
}둘 다 @ManyToOne으로 각 데이터들의 요청 단위에 따라 BigRegion 객체와 SmallReion 객체가 잘 맵핑되어 있다. 다른 ~Info 클래스들도 전부 데이터 요청 단위에 맞게 지역 객체를 전부 맵핑해주었다.
이제 "서울시 마포구"에 해당하는 기상 데이터들이 가지런하게 중복되지 않고 정렬이 가능해졌다. Open Api 요청도 훨씬 용이해졌음은 물론이다.
다만, 여기서 왜 @OneToOne이 아닌 @ManyToOne인가?라는 의문을 제기할 수 있겠다.
이 부분은 개발이 아닌 기획 측면의 내용 변경을 통해, 처음에 아주 단순하게 제시했던 초기 Region 테이블의 @OneToOne 맵핑을 @ManyToOne으로 바꾸었다.
이유는 기존 데이터를 남겨두고 싶어서였다. @OneToOne 맵핑을 하려면 5월 2일의 마포구 미세먼지 데이터를 저장하려면 5월 1일에 불러왔던 마포구의 미세먼지 데이터를 삭제해야 한다.
물론, 삭제하고 @OneToOne으로 관리할 수도 있다. 하지만 추후 사용자 로그 분석을 통해 특정일의 요청이 다른 날보다 유의미하게 많아질 경우, 해당 날짜의 기상데이터를 확보하고 있는 것이 유저 행동 패턴을 분석하기에 용이할 것이라 판단했다.
따라서 기존에 불러온 데이터를 삭제하지 않고 저장해두기로 팀과 합의를 하였다. 그럼으로써 특정 지역구에 해당하는 데이터가 한 개가 아니게 되었다. 따라서 @ManyToOne으로 맵핑을 진행하였다.
자, 드디어 날씨앱의 메인이 되는 기상데이터 테이블 설계가 완료되었다.
그럼 Open Api를 활용해 기상 데이터를 수집하러 가볼까요~⛅⛅⛅
