
♣️ WHY AWS Database?
Amazon Database

DB를 on-premise환경에서 사용할 경우 관리 point:
- 하드웨어와 소프트웨어 설치
- DB configuration, patching, backups
- 클러스터 셋업, 고가용성을 위한 데이터 복제
- 디비 용량관리, 클러스터 스케일링
AWS RDS의 장점
open source 데이터 베이스를 관리형 데이터 베이스로 제공

- 관리의 용이성: 쉬운 배포 및 장비 소프트웨어 관리, 내장형 모니터링
- 규모 확장의 유연성: 몇 번의 클릭으로 확장 가능, 최소 다운타임으로 규모 조절
- 고가용성: 자동화된 multi-AZ 복제, 백업, 및 failover
- 높은 보안 수준: 데이터의 암호화 옵션 제공 및 각종 규제 준수
1. 관리의 용이성
- Amazon CloudWatch metrics & alarms
- Enhanced Monitoring
- 50CPU, memory, file system, 그리고 disk I/O metrics 을 접근
- 1초 단위의 모니터링 제공
- CloudWatch Logs로 Database Log를 바로 Upload
- MySQL/MariaDB RDS에서 지원
- ELK 스택을 활용한 손쉬운 시각화 가능
- Third-party monitoring 툴과 통합
- Amazon RDS Performance Insights는 database load를 시각별로 수집
- Bottleneck인 SQL을 손쉽게 판별
- Top SQL/most intensive queries
- MySQL과 PostgreSQL 엔진에서 사용 가능
2. 규모 확장의 유연성
- 트랜잭션 증가를 대비한 Scale Up
- 더 많은 데이터 저장을 위한 Scale Up
- 테스트/개발을 위한 최솨 타입 제공
3. 고가용성
- Reader 확장으로 Master 확장으로 부하 경감
- 다른 Region으로 손쉽게 데이터 이관
- 긴급 상황에서 Read Replica를 Primary로 사용
- 전체 인스턴스의 일단위 데이터 백업
- 5분 단위의 Database의 Transaction log를 저장
- 최대 35일 데이터 저장
- Standby 인스턴스에서 수행되어 데이터베이스에 최소한의 영향으로 수행
4. 높은 보안 수준
-
2 Tired 암호화
- 고객 데이터 암호화에는 Data Key를 사용
- AWS KMS master keys는 Data key를 암호화
- 모든 RDS engine에서 사용 가능
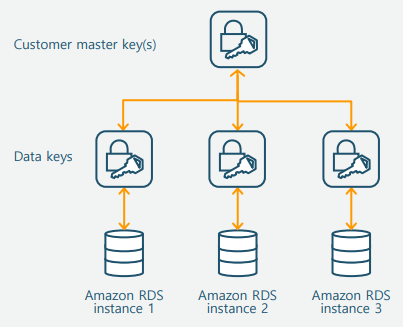
-
장점
- Data Key 노출 시 위험성 최소화
- 여러 Data Key보다 master key의 수가 적어 관리가 효율적임
- Key 관련된 작업들은 Cloudtrail로 감사 가능
🥋 Amazon Aurora
MySQL과 PostgreSQL 호환성을 제공하는 Cloud Native RDBMS 1/10 가격으로 상용 DB에 상응하는 성능과 가용성을 제공
- 고성능 및 확장성:
- 15개의 리플리카 사용 가능
- 표준 MySQL의 5배 Throughput 표준 PostgreSQL의 3배 Throughput
- 고 가용성 및 내구성:
- 3개의 AZ에 6개의 데이터 복제본 유지
- 자가 복구 스토리지 레이어
- 보안성
- VPC 네트워크 분리
- 암호화 옵션 제공
- 완전 관리형
- RDS에 의해 백업
- 소프트웨어 업데이트 등 관리
🥅 Why AWS Data Warehousing?
on-premise DW의 한계점
- 확장의 어려움
- 성능의 제약
- 고비용
Data lake architecture
- DW architecture를 확장
- 어떠한 data든 다양한 포맷으로 저장
- Exabyte 규모의 안정적 데이터 저장
- 높은 보안성, 가용성, Throughput 제공
- 여러 형태의 분석 도구를 제공
Data Warehousing: Amazon Redshift
- Leader Node :
- AWS 연결 엔드 포인트
- 메타데이터 저장
- 클러스터의 모든 쿼리 수행 관리
- Computing Node
- 로컬, 컬럼 방식 스토리지
- 병렬로 쿼리 수행
- S3 기반으로 로딩/백업/복구 수행
- H/W Optimization
- 데이터처리에 최적화
- 데이터 백업 시 전송/저장 암호화 기능 제공
- Amazon S3로 지속적인 변경 부분에 대한 자동 백업 제공
- 클러스터의 용량만큼의 백업스토리지 기본 제공
- 타 리전으로 스냅샷 비동기 복제 기능
- Streaming restore를 통해 빠르게 쿼리 제개 가능
- 디스크 장애, 노드의 복구는 자동으로 관리
Data Warehousing: Amazon Redshift Spectrum
S3의 데이터를 쿼리 형태로 바로 읽어서 볼 수 있는 기능
Data Warehousing: Amazon Redshift ML
SQL 명령문으로 ML모델을 생성하고 조회도 가능
🎲 Amazon Dynamo DB
빠르고 유연한 NoSQL database Service
Dynamo DB의 장점
- 언제나 고성능
- 수백만 TPS를 소화
- 1자리수 단위의 latency 제공
- 여러 리전 동기화
- Kinesis Data Stream을 활용한 데이터 변경 분석 가능
- 완전 관리형 - 인스턴스 Free
- Maintenance free
- 자동 Capacity 조정
- On-demand capacity mode
- Lambda, Redshift, 및 Opensearch와 통합
- 다양한 기능 제공
- ACID transactions
- KMS 암호화
- PITR 백업 복구
- NoSQL Workbench
- S3 export
- PartiQL 지원
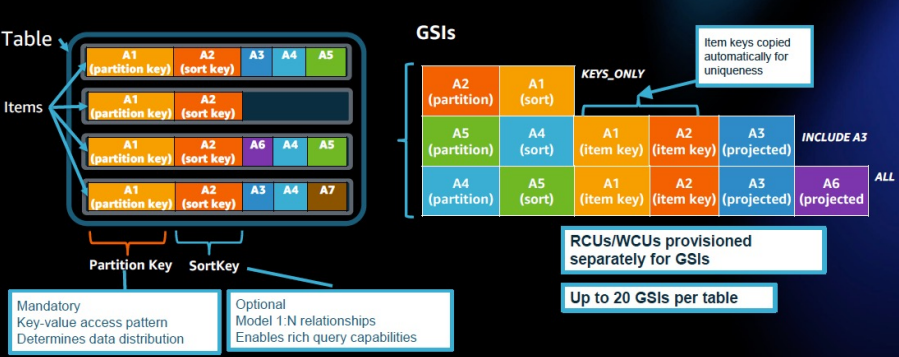
- Table 구조와 Global Secondary Index
🏊♀️ Amazon DocumentDB
Amazon DocumentDB의 장점
- 초당 수백만개의 요청 1/1000초의 지연시간
- MongoDB와 호환. 같은 코드, 드라이버 및 도구 사용
- 완전 관리형 서비스
- 보안 및 규정 준수
- 관리형 MongoDB 서비스의 2배 처리량
- AWS 서비스와 통합
- 글로벌 클러스터로 사용 가능
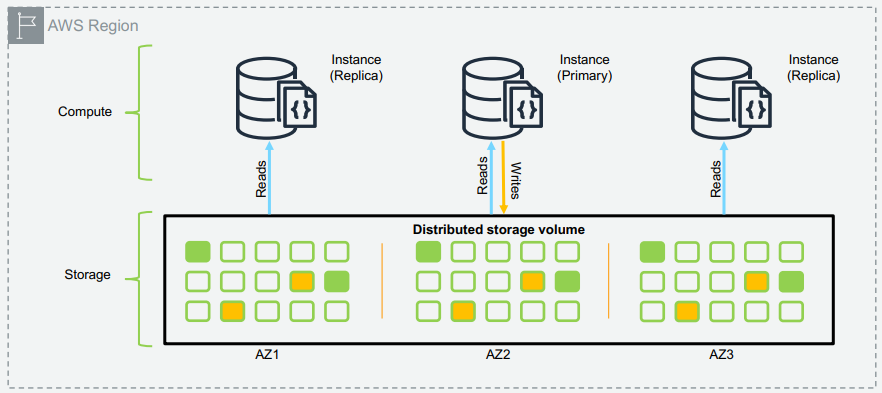
- 아키텍쳐
🏊♀️ Amazon Elastic Cache
완전 관리형 in-memory database 서비스
Amazon Elastic Cache의 장점
- 오픈소스 Redis와 Memcached를 제공
- microsecond 응답 속도의 성능 제공
- 각종 규제 준수, VPC 네트워크 격리, 암호화 옵션 제공
- Replica 및 Cluster 구성을 손쉽게 구성
Elastic Cache 사용 사례

🌴 Amazon Opensearch
Opensearch의 완전 관리형 서비스
Log분석, 어플리케이션 모니터링, Full-text 검색에 손쉽게 데이터 활용
Amazon Opensearch의 장점
- 몇번의 클릭으로 손쉽게 배포
- Logstash, Kibana를 제공하며 Elasticsearch의 표준 API 사용 가능
- VPC 네트워크 분리 및 데이터 암호화 기능 제공
- Replica Node 구성이 가능, Master HA 기능 제공

즐거움, 긍정, 열정으로 꿈을 꾸는 사람