
⛺ AutoScaling
애플리케이션 가용성을 유지하고 사용자가 정의한 조건에 따라 EC2 인스턴스를 자동으로 추가하거나 제거 할 수 있는 서비스
➡️ 장점:
- 내결함성 개선
- 애플리케이션 가용성 개선
- 비용 낮음
➡️ 작동 방식:
- Fleet 관리
- 실행되는 인스턴스의 상태 모니터링
- 손상된 인스턴스를 자동으로 교체
- 가용 영역 간에 용량 균형 조정
- 예약된 크기 조정
- Dynamic Scaling
- Predictive Scaling
➡️ Auto Scaling 요금
Amazon EC2, CloudWatch 및 사용하는 기타 AWS 리소스에 대한 서비스 요금 외에 Amazon EC2 AutoScaling 기능을 사용하는 데 따르는 추가 비용은 없음
➡️ Amazon EC2 Auto Scaling 수행 단계
- 로그인 - EC2 - 인스턴스 - 시작 템플릿 선택
- 시작 템플릿 생성 - AMI, 인스턴스 유형, Storage, NW, 보안그룹, User Data 등 지정
- Auto Scaling 그룹 생성 - 이름, 크기, 네트워크 지정
- Elastic Load Balancer 추가 - 로드 밸런서를 Auto Scaling 그룹에 연결하여, 필요에 따라 확장할 수 있는 EC2 인스턴스 전체에 애플리케이션 트래픽을 배포, 먼저 ELB 생성해야함.
- Scaling Policies 구성 - Amazon EC2 AutoScaling 그룹에 대한 조정 정책을 구성
🐳 Auto Scaling 종류

Application Auto Scaling
- Amazon Auto Scaling (AnyScale)
- Amazon EC2를 넘어서 개별 AWS 서비스에 대한 확장 가능 리소스를 자동 조정하기 위한 솔루션이 필요한 개발자와 시스템 관리자를 위한 웹 서비스
- Aurora, ECS, Dynamo DB, EMR 클러스터, Lambda, SageMaker 등 서비스에서 구현됨
- 해당 서비스 콘솔의 일부로 구현됨
- EC2 Auto Scaling과의 차이점
- No health checks: 리소스를 소유하거나 제어하지 않으므로 상태 확인 수행 안함
- Reduced feature-set: 수명 주기 후크와 같은 기능 없음
AWS Auto Scaling (관리 및 거버넌스)
- 기계학습 이용: 총 cpu 사용률 또는 네트워크 입출력과 같은 메트릭을 사용하여 리소스의 용량을 예측. 부하 예측 시, 최소 24시간 분량 데이터 필요.
EC2 Auto Scaling
- EC2 인스턴스에만 해당
- 인스턴스 또는 전체 AZ가 나빠질 때마다 자동 상태 확인 교체
- 경보 또는 조정 요청으로 자동 조정, 다양한 AZ 간의 밸런싱
- EC2 콘솔을 통해서 접근
⛵ Scaling Policies 종류
-
Manual scaling
자동 조정이 필요하지 않거나 일정한 수의 인스턴스로 용량을 유지해야 할 경우 유용 -
Scheduled scaling
예를 들어, 수요일에 용량을 늘리고 금요일에 용량을 줄이도록 일정을 구성 -
Dynamic scaling
수요 변화에 대응하여 Auto Scaling 그룹의 용량을 조정하는 방법- Target tracking scaling policies:
조정 지표를 선택하고 목표값을 설정, 목표값에 가깝게 유지
예) 그룹의 평균 총 CPU 사용량을 40%로 유지. - Step and simple scaling policies:
CloudWatch 경보에 대한 조정 지표와 임계값을 선택, 지정된 평가 기간에 임계값을 위반했을 때 Auto Scaling 그룹을
어떻게 조정할지 정의해야 함. 애플리케이션의 수요 곡선을 근접 유지.
예) 평균 CPU 사용률, ALB의 RequestCountPerTarget 지표
- Target tracking scaling policies:
-
Predictive scaling
본질적으로 대응적인 동적 스케일링만 사용하는 것에 비해 예상된 로드 전에 용량을 시작하여 더 빠르게 크기를 조정할 수 있음
➡️ Step Scaling in Action
Cooldown
- 지표의 임계값을 넘더라도 인스턴스를 생성하지 않고 기다리는 시간
- 기본 300초
Warmup
- 새로 시작된 인스턴스의 메트릭이 그룹 메트릭에 포함될 수 있는 기간
Step Scaling과 Simple Scaling 정책의 차이점
단계 조정 정책: 단순 조정 정책과 기본은 같지만, 지표 값에 따라 증감 수를 다르게 줄 수 있음.
단순 조정 정책: 지표의 임계치에 도달하는 경우, 사용자가 정한 인스턴스 수를 늘리거나 감소시키는 정책
Target Tracking:
특정 대상 값을 유지 하여 리소스 사용을 최적화 하는 확장 정책
⚽ Health Checks in Practice
EC2:
- 항상 체크 하는 상태
- Instance Status Checks와 Instance State를 사용해서 확인
ELB:
- Instance status를 로드 밸런서를 통해 확인
Custom:
- API call을 통해서 확인
Instance의 Life cycle
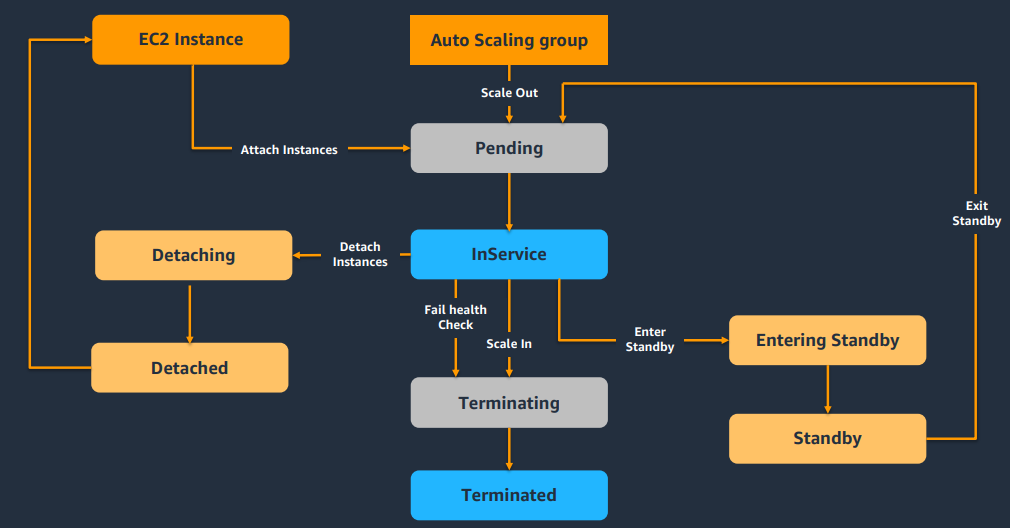
Life Cycle Hook
- Scale In/Out: In은 감소, Out은 증가를 뜻함
- 지표의 임계값에 의해, Scale In/Out이 되고 난 후 'In Service' 상태에 돌입하기 전에 사용자가 정의한 작업을 수행하는 시간을 설정하는 기능
- 기본 3600초
- 즉 인스턴스 시작/종료시 사용자가 작업을 수행 할 수 있음
- 이 시간동안 인스턴스에 설치 및 설정 등이 가능함
- CloudWatch를 사용하면 수명주기 작업이 발생시, Lamda 함수를 호출시키도록 설정 가능
ASG 수명 주기 후크의 사용 사례:
- 시작시 Amazon Elastic Compute Cloud(Amazon EC2) IP 주소 또는 ENI 할당
- DNS, 외부 모니터링 시스템, 방화벽에 새 인스턴스 등록...
- Amazon Simple Storage Service(Amazon S3) 또는 다른 시스템에서 기존 상태 로드
- 인스턴스가 종료되기 전에 로그 파일 풀다운
- 인스턴스를 종료하기 전에 인스턴스의 문제 조사
- 외부 시스템에 인스턴스 상태 유지
Receive Event Notifications
- 상태 변화에 대한 알람을 받는다
- Amazon Simple Notificaiton Service(Amazon SNS) and CloudWatch Events를 사용
EC2 AutoScaling with Spot Instance
스팟 인스턴스도 선택 가능!

즐거움, 긍정, 열정으로 꿈을 꾸는 사람