카프카의 가장 최신 버전에는 주키퍼를 제거했다고 한다.
처음에는 왜 삭제가 필요했을까? 잘 이해가 되지 않았다.
하지만, 카프카 토픽 삭제건을 분석하다가 주키퍼의 메타데이터와 브로커의 메타데이터가 일치하지 않을 수 있다는걸 알게 되었다.
그런 문제를 해결하기에 어쩌면 주키퍼를 제거할 필요가 있지 않았을까? 라는 생각이 들었고 그 이유를 좀더 알고싶어서 찾아보다가 컨플루언트에서 낸 좋은 기사를 발견했다.
공유하기 위해서 컨플루언트 기사를 한국어로 번역해 봤다.
카프카에서 주키퍼를 없애야 하는 이유
최근에, 아파치 카프카는 아파치 주키퍼를 카프카의 메타데이터를 저장하기 위해서 사용한다. 파티션의 위치 그리고 토픽의 설정 정보 같은 데이터는 카프카 밖에 주키퍼 클러스터에 따로 저장되었다. 2019년, 우리는 이런 의존성을 깨버릴 계획을 짰다 그리고 카프카 자체적으로 메타데이터를 관리 할수 있게 했다.
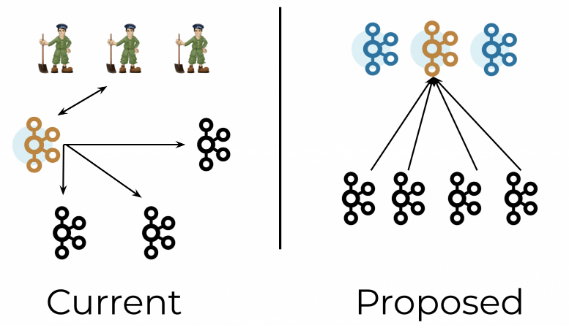
그렇다면 주키퍼의 문제점은 워였을까? 사실 주키퍼 자체의 문제가 아닌 밖에서 메타데이터를 관리한다는 컨셉 자체가 문제였다.
두개의 시스템을 사용한다는건 많은 복제를 야기했다. 결국, 카프카는 Pub/sub API가 위에 있는 복제된 분산 로그이다. 주키퍼는 filesystem API 위에 있는 복제된 분산 로그이다. 카프카와 주키퍼는 각각 그것만의 네트워크 소통 방법, 보안, 모니터링, 설정값 들이 있다. 두개의 시스템을 가지고 있는건 운영의 복잡성을 두배 정도 증가 시킨다. 이러한 상황은 불필요한 학습에 드는 시간을 증가시키고, 일부 잘못된 구성이 보안 침해를 일으킬 위험을 높힌다.
메타데이터를 외부에서 모으는것은 별로 효과적이지 못하다. 우리는 최소 세개나 종종 그 이상의 자바 프로세서를 더 실행시킨다. 사실, 우리는 종종 카프카 클러스터 만큼 많은 주키퍼 노드를 본다. 게다가, 주키퍼에 데이터는 또한 카프카 컨트롤러를 반영한다. 이 상황은 이중 캐싱을 하게 한다.
더욱이 메타데이터를 외부에 저장하면 Kafka의 확장성이 제한된다. 카프카 클러스터가 시작될때 또는 새로운 컨트롤러가 뽑힐때, 컨트롤러는 반드시 주키퍼로부터 클러스터의 모든 상태를 받아서 올려야 한다. 그러므로 메타데이터의 양이 커질수록, 이 로딩 과정은 길어진다. 이러한 상황은 카프카가 저장 할 수 있는 파티션의 개수를 제한한다.
마지막으로 메타데이터를 외부에 저장하면 컨트롤러의 in-memory 상태가 외부 상태로부터 비동기화될 수 있습니다.클러스터에 있는 컨트롤러의 실시간 시점은 ZooKeeper의 시점과 다를 수 있습니다.
아마도 마지막 부분이 내가 겪은 이슈와 일치하는듯 하다
KIP-500
Handling metadata
KIP-500은 카프카 메타데이터를 관리할 더 나은 방법을 소개한다. 주키퍼와 같은 외부 시스템이 아닌 카프카 자체에 카프카의 메타데이터를 저장하기 때문에, 이것을 "카프카 위의 카프카"라고 생각할 수 있다. KIP-500 이후에는 메타데이터는 ZooKeeper가 아닌 Kafka 내부의 파티션에 저장될 것이다.컨트롤러는 이 파티션의 리더가 될 것이다. 더이상 외부 메타데이터 관리 및 설정 시스템은 없고 카프카 자체만 있을 것이다.
우리는 메타데이터를 로그로 여길 것이다. 최신 정보가 필요한 브로커들은 오직 로그의 마지막 부분만 읽을 수 있다. 이는 최신 로그가 필요한 consumer가 로그 전체가 아니라 로그의 맨 끝 부분만 읽으면 되는 것과 유사하다. 브로커는 프로세스 재시작 후에도 메타데이터 캐시를 유지할 수 있습니다.
Controller architecture
카프카 클러스터는 클러스터 메타데이터와 파티션 리더를 관리하기 위해서 컨트롤러 노드를 선출 했다. 메타데이터와 파티션이 많아질수록, 컨트롤러의 확장성이 더 중요해진다.우리는 토픽 또는 파티션의 수에 선형적으로 비례하는 시간을 필요로 하는 작업 수를 최소화 하길 원한다.
이러한 작업 중 하나는 컨트롤러 failover이다. 최근에 카프카에 새로운 컨트롤러가 뽑힐때, 먼저 클러스터 상태 전체를 로드 해야 한다. 메타데이터가 커질수록, 이 과정은 점점 더 오래 걸린다.
반면 KIP-500 이후, 활성화된 컨트롤러가 죽으면 대체할 스탠바이 컨트롤러가 몇개 준비 되어 있다. 이 스탠바이 컨트롤러들은 메타데이터 파티션의 Raft 쿼럼에 있는 다른 노드일 뿐입니다. 이 설계는 새 컨트롤러가 선택될 때 긴 로딩 프로세스를 거치지 않아도 되도록 보장한다.
KIP-500은 토픽을 만들고 지우는게 빨라지게 한다. 최근에 픽이 만들어지거나 지울때,컨트롤러는 주키퍼로부터 클러스터 안에 있는 모든 토픽 이름의 리스트를 반드시 다시 로딩해야 한다. 주키퍼는 클러스터에서 토픽들의 구성이 변경되면 알려 주지만 어떤 토픽이 추가되거나 제거되었는지 정확하게 알려주지 않기 때문에 이 작업이 꼭 필요하다. 대조적으로, 토픽을 만들거나 삭제하는 것은 KIP-500 이후 단순히 메타데이터 파티션에 새로운 항목을 생성하는 것이다. 이 과정은 O(1) 의 연산이다.
매타데이터의 확장성은 카프카의 미래의 중점 문제 이다. 우리는 하나의 카프카 클러스터가 결국 수백만개의 파티션을 운영할수 있기를 바란다.