Codecademy [Learn Natural Language Processing]
Language Parsing
Compiling and Matching
re module 's methods...
.compile(): 정규 표현식을 컴파일컴파일한거.match(문자열): 문자열의 첫 부분부터 정규 표현식과 매치하는지를 확인.group(): to access the matched text.result.group(0)
import re
# characters are defined
character_1 = "Dorothy"
character_2 = "Henry"
# compile your regular expression here
regular_expression = re.compile("[A-Za-z]{7}")
# check for a match to character_1 here
result_1= regular_expression.match(character_1)
# store and print the matched text here
match_1 = result_1.group(0)
print(match_1)
# compile a regular expression to match a 7 character string of word characters and check for a match to character_2 here
result_2 = regular_expression.match(character_2)
print(result_2)Searching and Finding
-
.search(): 정규 표현식 전체에 대해서 문자열이 매치하는지first_match = re.search('regex pattern here', text_youre_searching_through) -
.findall(): to find all the occurrences of a word or keyword in a piece of text to determine a frequency count. 리스트를 리턴함all_occurences = re.search('regex pattern here', text_youre_searching_through)
import re
# import L. Frank Baum's The Wonderful Wizard of Oz
oz_text = open("the_wizard_of_oz_text.txt",encoding='utf-8').read().lower()
#결과
#<_sre.SRE_Match object; span=(14, 20), match='wizard'>
# search oz_text for an occurrence of 'wizard' here
found_wizard = re.search("wizard", oz_text)
print(found_wizard)
# find all the occurrences of 'lion' in oz_text here
all_lions = re.findall("lion", oz_text)
print(all_lions)
# store and print the length of all_lions here
number_lions = len(all_lions)
print(number_lions)Part-of-Speech Tagging
- 품사 태깅(pos_tag)
- process of identifying and labeling the part of speech of words
Noun
Pronoun: (her,she)
Determiner: (the)
Verb: (studying) (are,has)
Adjective: (new)
Adverb: (happily)
Preposition: (on)
Conjunction: (and)
Interjection: (Wow)
-
nltk‘s pos_tag() function 으로 자동 테깅하기
part_of_speech_tagged_sentence = pos_tag(word_sentence:토근화한단어들)
import nltk
from nltk import pos_tag
from word_tokenized_oz import word_tokenized_oz
# save and print the sentence stored at index 100 in word_tokenized_oz here
witches_fate = word_tokenized_oz [100]
print(witches_fate)
# create a list to hold part-of-speech tagged sentences here
pos_tagged_oz = []
# create a for loop through each word tokenized sentence in word_tokenized_oz here
for word in word_tokenized_oz:
pos_tagged_oz.append(pos_tag(word))
# part-of-speech tag each sentence and append to pos_tagged_oz here
# store and print the 101st part-of-speech tagged sentence here
witches_fate_pos = pos_tagged_oz[100]
print(witches_fate_pos)
#결과
#[('``', '``'), ('the', 'DT'), ('house', 'NN'), ('must', 'MD'), ('have', 'VB'), ('fallen', 'VBN'), ('on', 'IN'), ('her', 'PRP'), ('.', '.')]Introduction to Chunking
-
개체명 인식(Named Entity Recognition): 이름을 가진 개체(named entity)를 인식
-
chunking: grouping words by their part-of-speech tag
-
chunk grammar : regular expression you build to find chunks
ex)
chunk_grammar = "AN: {<JJ><NN>}"AN: 아무거나 대체가닝<JJ>: matching any adjective<NN>: matches any noun, singular or plural
-
chunkgrammer 사용 위해서는
nltk RegexpParserobject 만들고 여기에 chucnk grammer를 argument로 줘야함.chunk_parser = RegexpParser(chunk_grammar)
from nltk import RegexpParser, Tree
from pos_tagged_oz import pos_tagged_oz
# define adjective-noun chunk grammar here
chunk_grammar = "AN: {<JJ><NN>}"
# create RegexpParser object here
chunk_parser = RegexpParser(chunk_grammar)
# chunk the pos-tagged sentence at index 282 in pos_tagged_oz here
scaredy_cat = chunk_parser.parse(pos_tagged_oz[282])
print(scaredy_cat)
"""
결과
(S ``/`` where/WRB is/VBZ the/DT (AN emerald/JJ city/NN) ?/. ''/'')
"""
# pretty_print the chunked sentence here
Tree.fromstring(str(scaredy_cat)).pretty_print()
"""결과
S
______________________|__________________________
| | | | | | AN
| | | | | | _______|_____
``/`` where/WRB is/VBZ the/DT ?/. ''/'' emerald/JJ city/NN
"""Chunking Noun Pharses
- NP-chunking : noun phrase chunking.
- noun phrase : a phrase that contains a noun and operates, as a unit, as a noun.
chunk_grammar = "NP: {<DT>?<JJ>*<NN>}"
NPstands for noun phrase<DT>matches any determiner,?is an optional quantifier,
- can perform a frequency analysis and identify important, recurring noun phrases
from nltk import RegexpParser
from pos_tagged_oz import pos_tagged_oz
from np_chunk_counter import np_chunk_counter
# define noun-phrase chunk grammar here
chunk_grammar = "NP: {<DT>?<JJ>*<NN>}"
# create RegexpParser object here
chunk_parser = RegexpParser(chunk_grammar)
# create a list to hold noun-phrase chunked sentences
np_chunked_oz = list()
# create a for loop through each pos-tagged sentence in pos_tagged_oz here
for word in pos_tagged_oz:
# chunk each sentence and append to np_chunked_oz here
np_chunked_oz.append(chunk_parser.parse(word))
# store and print the most common np-chunks here
most_common_np_chunks= np_chunk_counter(np_chunked_oz )
print(most_common_np_chunks)결과:

Chunking Verb Phrases
chunk_grammar = "VP: {<VB.*><DT>?<JJ>*<NN><RB.?>?}"
<VB.*>:matching verbs of any tense
(ex. VB for present tense, VBD for past tense, or VBN for past participle)<RB.?>: matching any form of adverb
(regular RB, comparative RBR, or superlative RBS)
from nltk import RegexpParser
from pos_tagged_oz import pos_tagged_oz
from vp_chunk_counter import vp_chunk_counter
# define verb phrase chunk grammar here
chunk_grammar = "VP: {<VB.*><DT>?<JJ>*<NN><RB.?>?}"
# create RegexpParser object here
chunk_parser = RegexpParser(chunk_grammar )
# create a list to hold verb-phrase chunked sentences
vp_chunked_oz = list()
# create for loop through each pos-tagged sentence in pos_tagged_oz here
for word in pos_tagged_oz:
# chunk each sentence and append to vp_chunked_oz here
vp_chunked_oz.append(chunk_parser.parse(word))
# store and print the most common vp-chunks here
most_common_vp_chunks = vp_chunk_counter (vp_chunked_oz )
print(most_common_vp_chunks)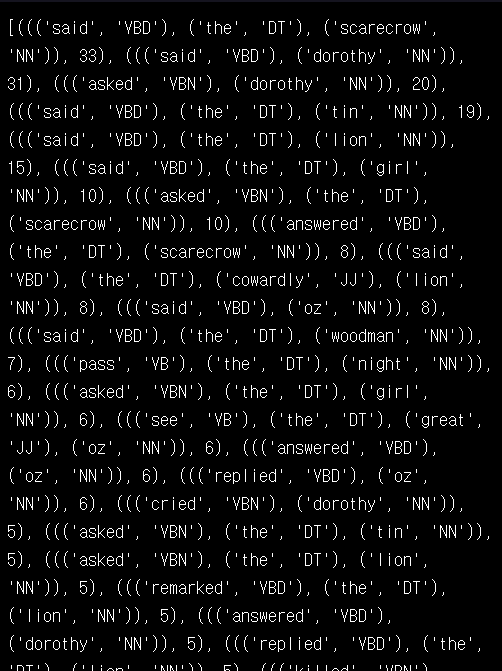
grammer "VP: {<DT>?<JJ>*<NN><VB.*><RB.?>?}" 이렇게 수정하면...

Chunk Filtering
-
Chunk filtering: lets you define what parts of speech you do not want in a chunk and remove them.
-
to chunk an entire sentence together and then indicate which parts of speech are to be filtered out
chunk_grammar = """NP: {<.*>+} }<VB.?|IN>+{"""
<.*>+: matches every part of speech in the sentence<VB.?|IN>+will filter out any verbs or prepositions
from nltk import RegexpParser, Tree
from pos_tagged_oz import pos_tagged_oz
# define chunk grammar to chunk an entire sentence together
grammar = "Chunk: {<.*>+}"
# create RegexpParser object
parser = RegexpParser(grammar)
# chunk the pos-tagged sentence at index 230 in pos_tagged_oz
chunked_dancers = parser.parse(pos_tagged_oz[230])
print(chunked_dancers)
# define noun phrase chunk grammar using chunk filtering here
chunk_grammar = """NP: {<.*>+}
}<VB.?|IN>+{"""
# create RegexpParser object here
chunk_parser = RegexpParser(chunk_grammar)
# chunk and filter the pos-tagged sentence at index 230 in pos_tagged_oz here
filtered_dancers = chunk_parser.parse(pos_tagged_oz[230])
print(filtered_dancers)
# pretty_print the chunked and filtered sentence here
Tree.fromstring(str(filtered_dancers)).pretty_print()"result"
(S
(Chunk
then/RB
she/PRP
sat/VBD
upon/IN
a/DT
settee/NN
and/CC
watched/VBD
the/DT
people/NNS
dance/NN
./.))
(S
(NP then/RB she/PRP)
sat/VBD
upon/IN
(NP a/DT settee/NN and/CC)
watched/VBD
(NP the/DT people/NNS dance/NN ./.))
S
_____________________________________________|_______________________________
| | | NP NP NP
| | | _____|_____ _______|_______ ________|________________
sat/VBD upon/IN watched/VBD then/RB she/PRP a/DT settee/NN and/CC the/DT people/NNS dance/NN ./.
Project [Discover Insights into Classic] Texts>
from nltk import pos_tag, RegexpParser
from tokenize_words import word_sentence_tokenize
from chunk_counters import np_chunk_counter, vp_chunk_counter
# import text of choice here
text = open("dorian_gray.txt",encoding='utf-8').read().lower()
# sentence and word tokenize text here
word_tokenized_text = word_sentence_tokenize(text)
# store and print any word tokenized sentence here
single_word_tokenized_sentence = word_tokenized_text[77]
print(single_word_tokenized_sentence)
# create a list to hold part-of-speech tagged sentences here
pos_tagged_text = []
# create a for loop through each word tokenized sentence here
for word_tokenized_sentence in word_tokenized_text :
# part-of-speech tag each sentence and append to list of pos-tagged sentences here
pos_tagged_text.append(pos_tag(word_tokenized_sentence))
# store and print any part-of-speech tagged sentence here
single_pos_sentence = pos_tagged_text[77]
print(single_pos_sentence)
# define noun phrase chunk grammar here
np_chunk_grammar = "NP: {<DT>?<JJ>*<NN>}"
# create noun phrase RegexpParser object here
np_chunk_parser = RegexpParser(np_chunk_grammar)
# define verb phrase chunk grammar here
vp_chunk_grammar = "VP: {<DT>?<JJ>*<NN><VB.*><RB.?>?}"
# create verb phrase RegexpParser object here
vp_chunk_parser = RegexpParser(vp_chunk_grammar)
# create a list to hold noun phrase chunked sentences and a list to hold verb phrase chunked sentences here
np_chunked_text = []
vp_chunked_text = []
# create a for loop through each pos-tagged sentence here
for pos_tagged_sentence in pos_tagged_text:
# chunk each sentence and append to lists here
np_chunked_text.append(np_chunk_parser.parse(pos_tagged_sentence))
vp_chunked_text.append(vp_chunk_parser.parse(pos_tagged_sentence))
# store and print the most common NP-chunks here
most_common_np_chunks = np_chunk_counter(np_chunked_text )
print(most_common_np_chunks)
# store and print the most common VP-chunks here
most_common_vp_chunks = vp_chunk_counter(vp_chunked_text )
print(most_common_vp_chunks)
결과
['``', 'of', 'course', 'i', 'am', 'not', 'like', 'him', '.']
[('``', '``'), ('of', 'IN'), ('course', 'NN'), ('i', 'NN'), ('am', 'VBP'), ('not', 'RB'), ('like', 'IN'), ('him', 'PRP'), ('.', '.')]
[((('i', 'NN'),), 962), ((('henry', 'NN'),), 200), ((('lord', 'NN'),), 197), ((('life', 'NN'),), 170), ((('harry', 'NN'),), 136), ((('dorian', 'JJ'), ('gray', 'NN')), 127), ((('something', 'NN'),), 126), ((('nothing', 'NN'),), 93), ((('basil', 'NN'),), 85), ((('the', 'DT'), ('world', 'NN')), 70), ((('everything', 'NN'),), 69), ((('anything', 'NN'),), 68), ((('hallward', 'NN'),), 68), ((('the', 'DT'), ('man', 'NN')), 61), ((('the', 'DT'), ('room', 'NN')), 60), ((('face', 'NN'),), 58), ((('the', 'DT'), ('door', 'NN')), 56), ((('love', 'NN'),), 55), ((('art', 'NN'),), 52), ((('course', 'NN'),), 51), ((('the', 'DT'), ('picture', 'NN')), 46), ((('the', 'DT'), ('lad', 'NN')), 45), ((('head', 'NN'),), 44), ((('round', 'NN'),), 44), ((('hand', 'NN'),), 44), ((('sibyl', 'NN'),), 41), ((('the', 'DT'), ('table', 'NN')), 40), ((('the', 'DT'), ('painter', 'NN')), 38), ((('sir', 'NN'),), 38), ((('a', 'DT'), ('moment', 'NN')), 38)]
[((('i', 'NN'), ('am', 'VBP')), 101), ((('i', 'NN'), ('was', 'VBD')), 40), ((('i', 'NN'), ('want', 'VBP')), 37), ((('i', 'NN'), ('know', 'VBP')), 33), ((('i', 'NN'), ('have', 'VBP')), 32), ((('i', 'NN'), ('do', 'VBP'), ("n't", 'RB')), 31), ((('i', 'NN'), ('had', 'VBD')), 31), ((('i', 'NN'), ('suppose', 'VBP')), 17), ((('i', 'NN'), ('think', 'VBP')), 16), ((('i', 'NN'), ('am', 'VBP'), ('not', 'RB')), 14), ((('i', 'NN'), ('thought', 'VBD')), 13), ((('i', 'NN'), ('believe', 'VBP')), 12), ((('dorian', 'JJ'), ('gray', 'NN'), ('was', 'VBD')), 11), ((('i', 'NN'), ('am', 'VBP'), ('so', 'RB')), 11), ((('henry', 'NN'), ('had', 'VBD')), 11), ((('i', 'NN'), ('did', 'VBD'), ("n't", 'RB')), 9), ((('i', 'NN'), ('met', 'VBD')), 9), ((('i', 'NN'), ('said', 'VBD')), 9), ((('i', 'NN'), ('am', 'VBP'), ('quite', 'RB')), 8), ((('i', 'NN'), ('see', 'VBP')), 8), ((('i', 'NN'), ('did', 'VBD'), ('not', 'RB')), 7), ((('i', 'NN'), ('have', 'VBP'), ('ever', 'RB')), 7), ((('life', 'NN'), ('has', 'VBZ')), 7), ((('i', 'NN'), ('did', 'VBD')), 6), ((('i', 'NN'), ('feel', 'VBP')), 6), ((('life', 'NN'), ('is', 'VBZ')), 6), ((('the', 'DT'), ('lad', 'NN'), ('was', 'VBD')), 6), ((('i', 'NN'), ('asked', 'VBD')), 6), ((('i', 'NN'), ('came', 'VBD')), 6), ((('i', 'NN'), ('felt', 'VBD')), 6)]