1. 옵티마이저와 실행계획
@@ 옵티마이저
다양한 실행방법들 중에서 최적의 실행방법을 결정하는 것
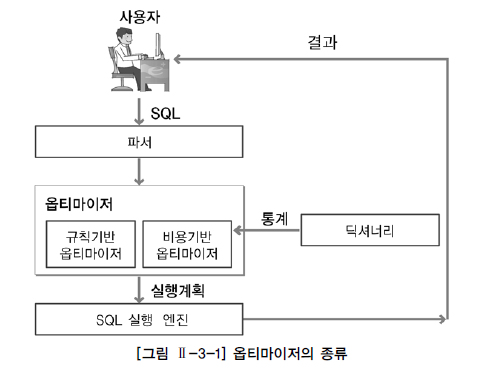
- 규칙기반 옵티마이저 : 규칙(우선순위)가지고 실행계획 생성
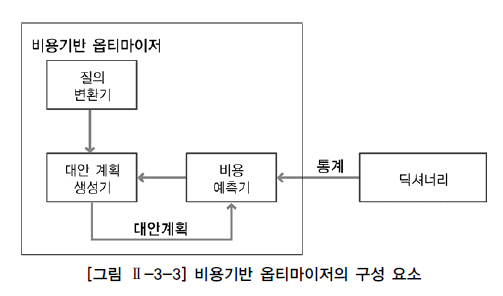
- 비용기반 옵티마이저 : SQL문 처리하는데 필요한 비용이 가장 적게
동일 SQL문도 서로 다른 실행계획이 생성될 수 있다
단점 - 한계가 있어서 실행계획 예측 및 제어가 어렵다
옵티마이저 실행계획 @@
SQL에서 요구한 사항 처리 위한 절차와 방법
실행계획 구성 요소 : 조인순서, 조인기법, 액세스기법, 최적화정보, 연산 등
동일 SQL에 대해 다양한 처리방법이 존재할 수 있지만 성능/실행 시간은 다를 수 있음.
옵티마이저는 다양한 방법 중 효율적인 방법 찾아줌.
SQL 처리 흐름

2. 인덱스 기본
인덱스 특징과 종류 @@
원하는 데이터 쉽게 찾을 수 있도록. 찾아보기.
DML은 느려질 수 있음 - 데이블 / 인덱스를 함께 변경해야해서
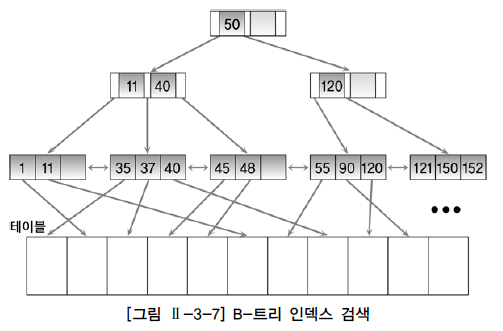
트리기반 인덱스 @@
- 가장 일반적인 인덱스: B-트리인덱스
- 리프블록 : 인덱스 구성 칼럼의 데이터 + 해당데이터 가지고 있는 행의 위치를 가리키는 레코드식별자(RID - record identifier/rowid)로 구성
- ‘=’로 검색하는 일치 검색과 ‘BETWEEN’등의 범위 검색 모두 적합함
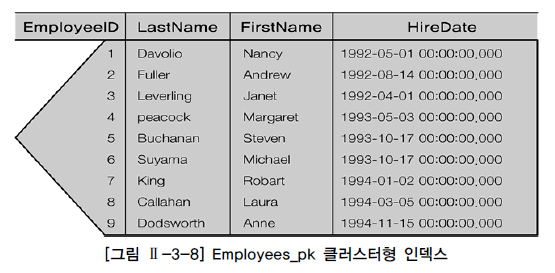
SQL Server 의 클러스터형 인덱스
- 클러스터형 / 비클러스터형 인덱스 존제
- 클러스터형의 중요성 :
- 인덱스 리프페이지가 곧 데이터페이지
- 리프페이지의 모든 로우는 인덱스키칼럼순으로 물리적 정렬되어 저장.
전체 테이블 스캔 / 인덱스 스캔 비교
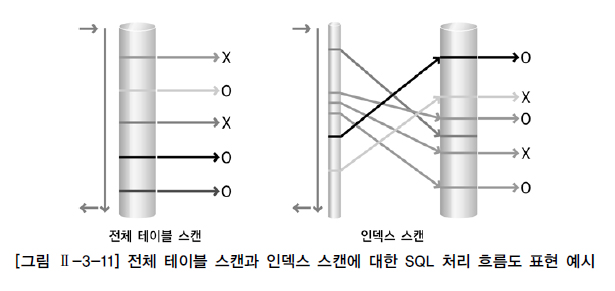
3. 조인 수행 원리 @@
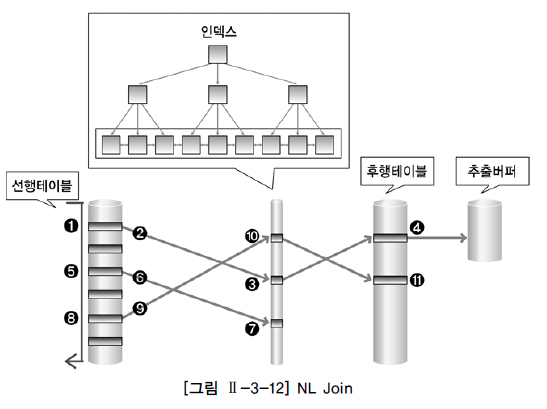
NL Join
- 프로그래밍의 중첩 반복문과 유사.
반복문 외부 테이블 = 선행 테이블 or 외부 테이블
내부 테이블 = 후행 테이블 or 내부 테이블
선행 -> 후행 순사.
결과 행의 수가 적은 테이블을 조인 순서상 선행테이블로 선택하는게 전체 일량 줄임.
조인 성공하면 바로 조인 결과를 사용자에게 보여줘서 온라인 프로그램에 적당.
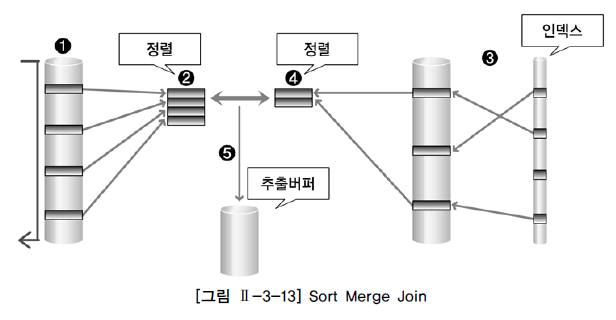
Sort Merge Join
-
스캔하는 방식으로 데이터 읽음.
조인 칼럼 인덱스 없이 사용가능 - but 성능 떨어질 수 있음. -
조인 칼럼 기준으로 정렬해서 조인 수행.
NL 조인은 랜덤 액세스 방식으로 읽지만 Sort merge는 스캔방식으로 읽음. -> 랜덤으로 하기에 부담되는 넓은 데이터 처리에 이용.
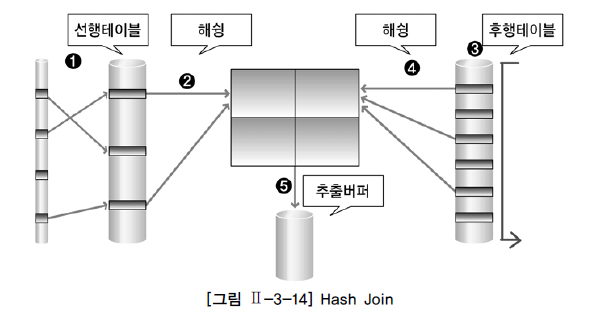
Hash Join
-
테이블의 조인 칼럼을 기준으로 해쉬 함수를 수행. 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지를 비교하면서 조인을 수행한다
-
랜덤 액세스 문제점과 sort merge join의 정렬작업 부담 문제점의 대안.
-
=로 수행하는 ㄷㅇ등저인에서만 사용가능.
-
결과 행의 수가 적은 테이블을 선행으로 하는게 좋음.

roundy