ref : 노마드 코더
파이썬 강의 - job scrapper
outline
특정 사이트(stackoverflow, indeed)에 있는 특정 검색어 관련(python) 잡 공고를 긁어와서 엑셀 시트에 저장하기
환경: repl it 활용
방법: 1. 파이썬으로 웹사이트에 접근, html 가져오기, 정보추출 - .페이지가 몇개인지 알기(페이지 당 결과를 좀 많이 설정하기 - 50개) 2.페이지 하나씩 들어가기
INDEED
사이트 url 가져오기
-
url 확인
https://www.indeed.com/jobs?q=python&limit=50
https://stackoverflow.com/jobs?q=python
-
라이브러리 임포트하기 / 패키지 사용하기
- urllib
- python requests (https://github.com/psf/requests)
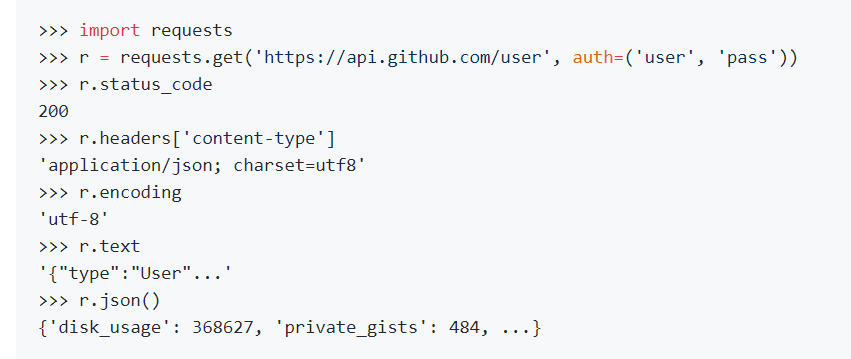
이런식으로 임포스해서 문법을 쓰면 됨. - header, text, json 가져오기 가능.
! 리플잇에서는 다른방법 필요함. -> 패키지 검색해서 add 해주고 파일에 import request 써주기.
- 데이터 가져오기
리퀘스트 문법에 따라... get으로 가져와서 변수에 저장하기 -> run 해서 에러 안나는지 확인
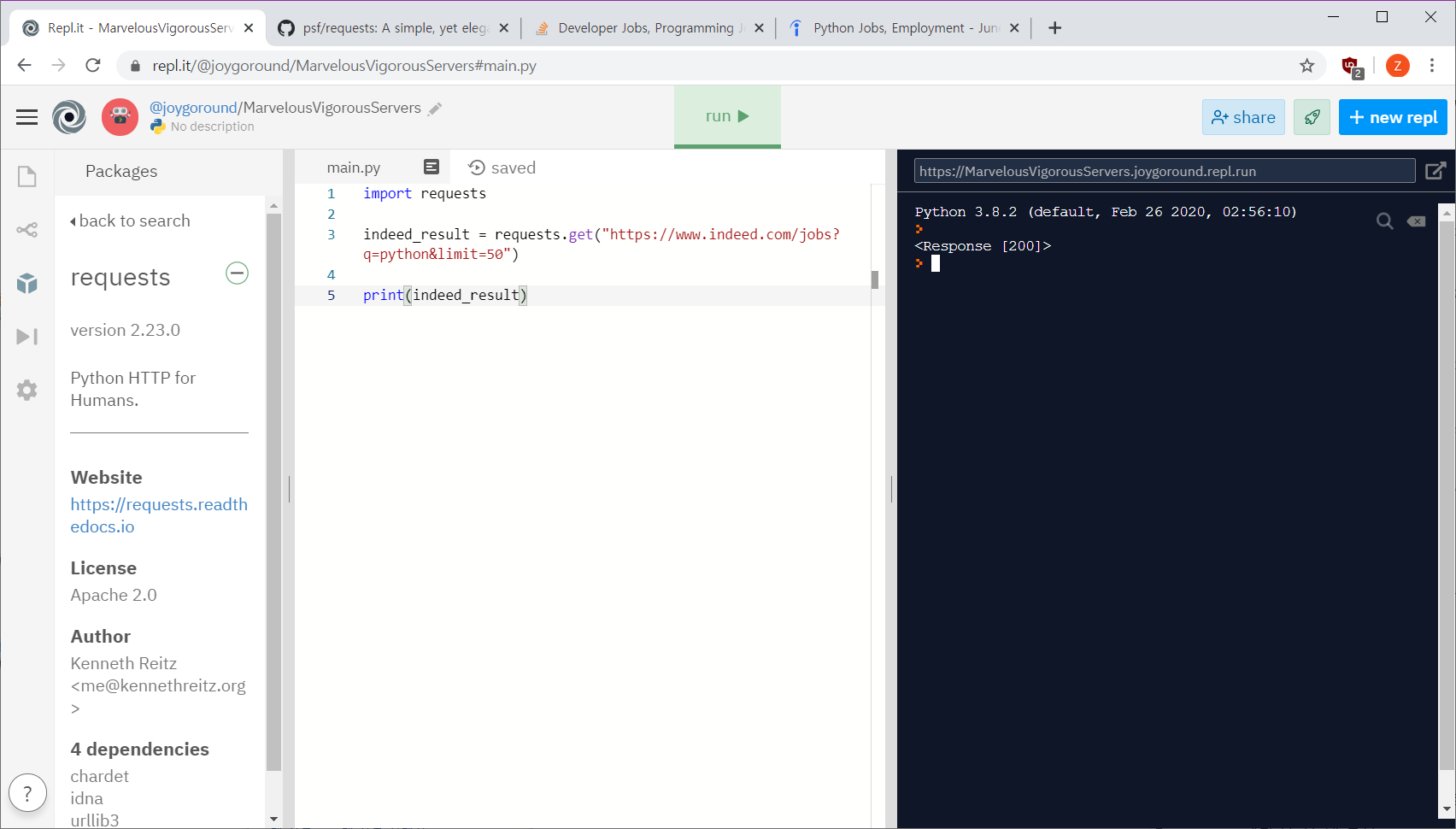
여기서requests.get()은 method로 object 안의 function 임.
페이지 수 알아내기
- text 가져오기 - BEAUTIFUL SOUP 활용
데이터를 explore
여기서 그대로 변수.text 를 해주면 모든 html을 가져옴. 이걸 trim 해야함.
리플잇 패키지에서 검색해서 addBEAUTIFUL SOUP 활용
htm에서 정보 추출할 때 아주 유용한 라이브러리
https://www.crummy.com/software/BeautifulSoup/bs4/doc/# pip install beautifulsoup4
- HTML Document 필요 : 위에서 requests로 변수.text로 가져올 수 있음
scrap대상 페이지에서 가져올 것 code확인 후 bs4 문법 사용해서 가져오기.
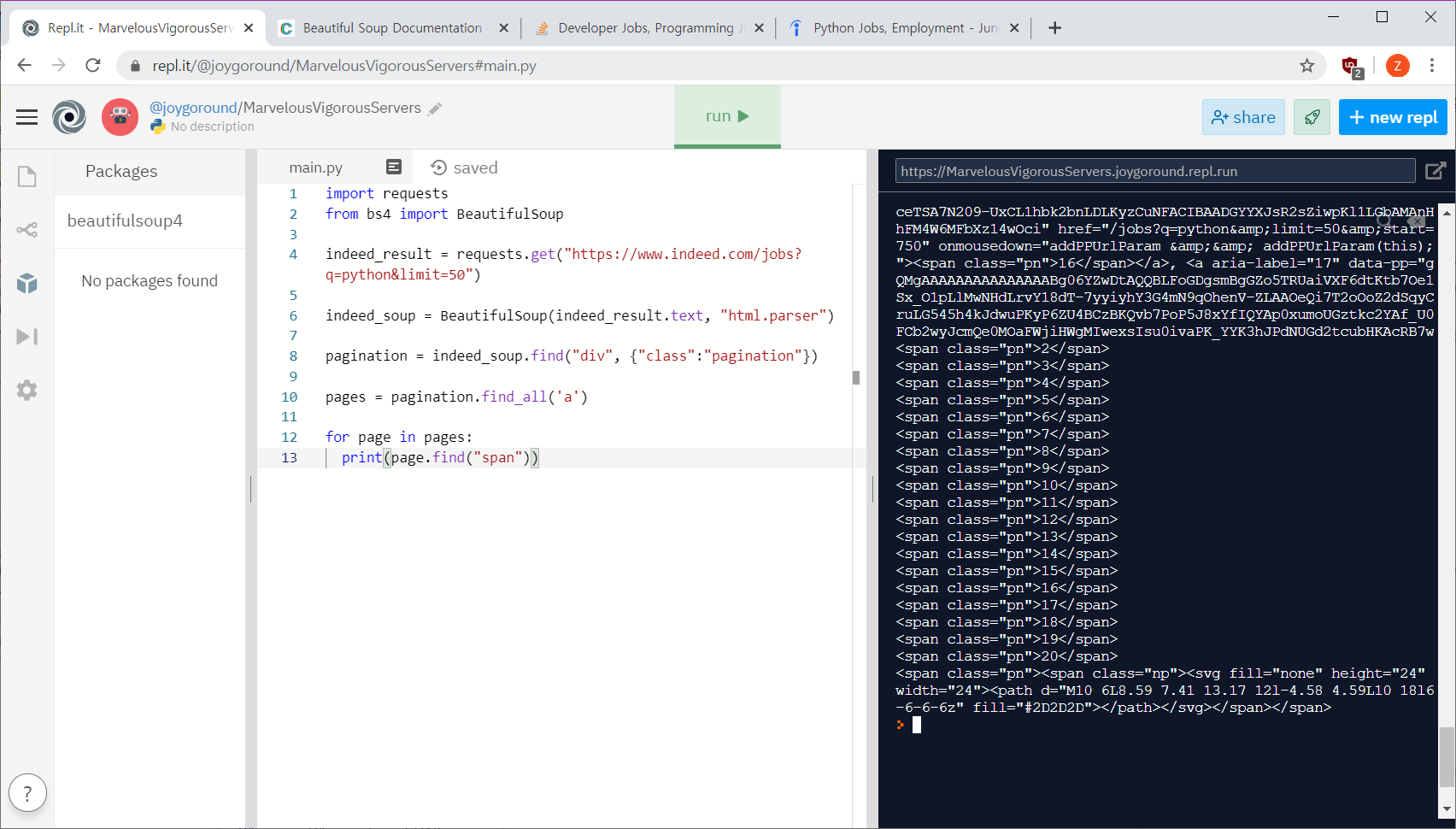
for 사용해서 빈 array에 담고 마지막 요소 제거해서 다듬기
import requests
from bs4 import BeautifulSoup
indeed_result = requests.get("https://www.indeed.com/jobs?q=python&limit=50")
indeed_soup = BeautifulSoup(indeed_result.text, "html.parser")
pagination = indeed_soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
spans = []
for link in links:
spans.append(link.find("span"))
spans = spans[:-1])여기서 문자열만 가져오기
spans.append(link.string)기능을 묶어 함수로 만들어주기
새 파일에 함수를 설정하고 기능을 다 넣어줌. 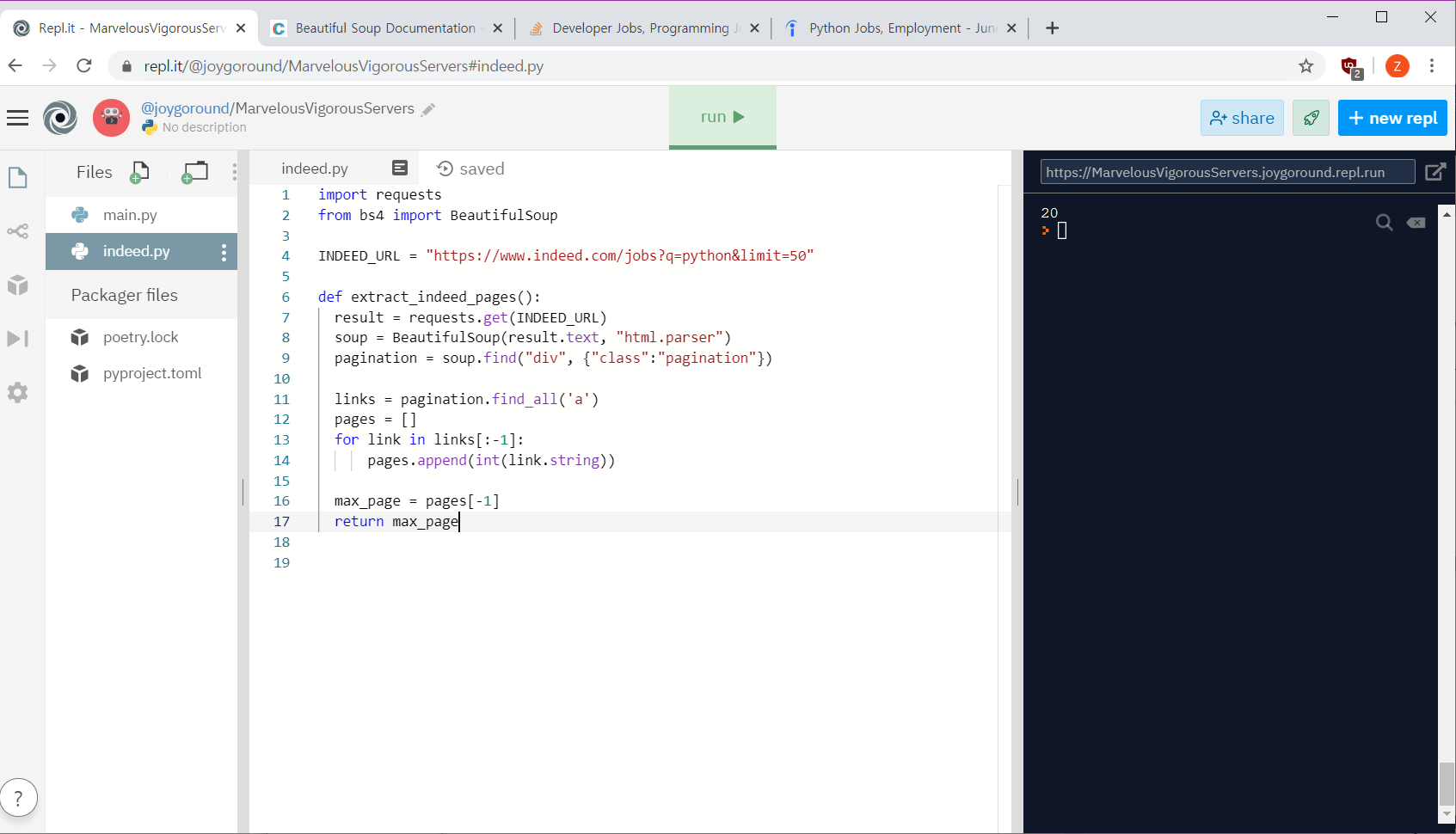
메인에서 이렇게 불러옴 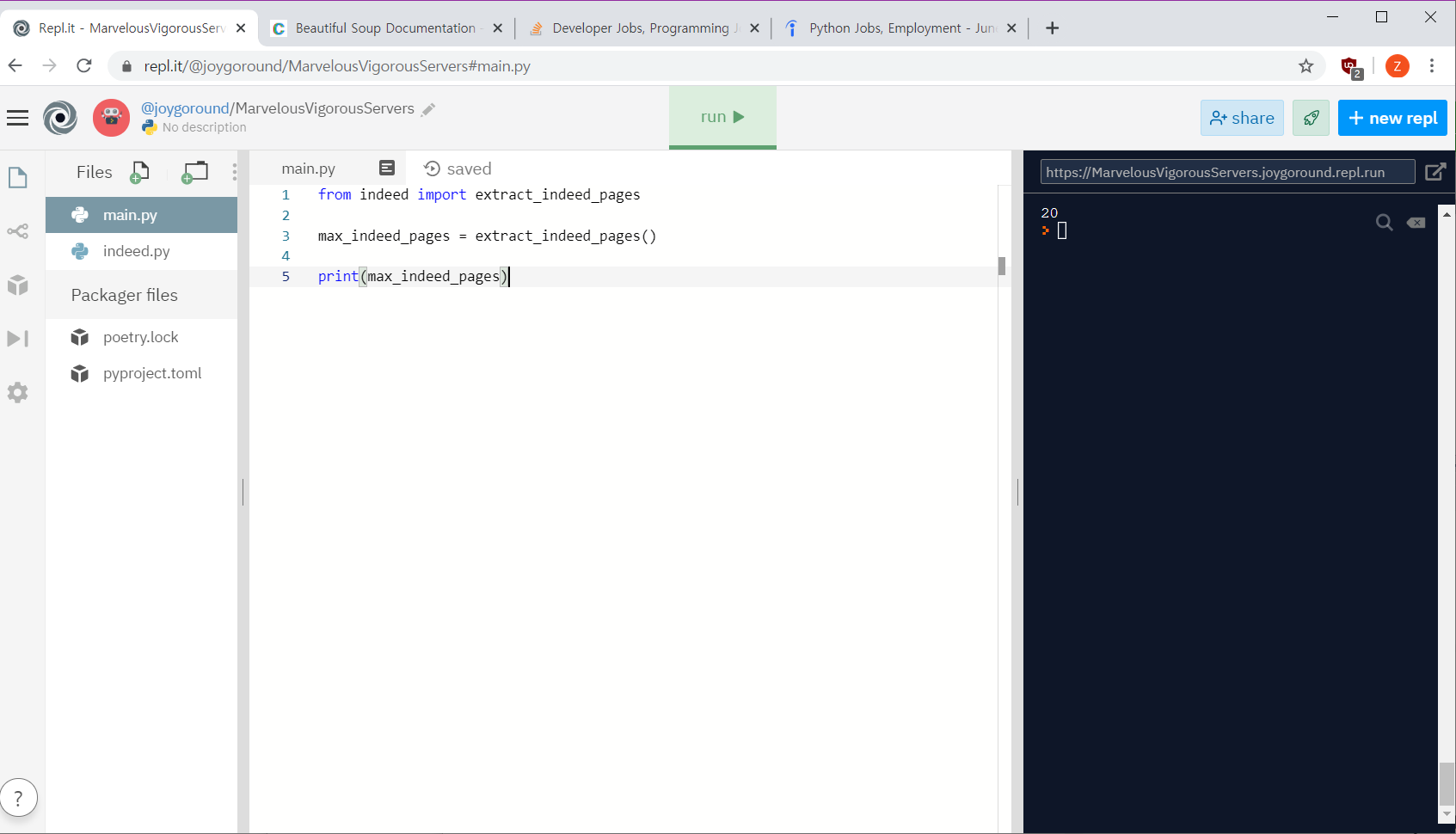
페이지 수에 따라 각 페이지 request 하기
함수로 만들기
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class":"pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_indeed_jobs(last_page):
jobs = []
for page in range(last_page):
result = requests.get(f"{URL}&start={page*LIMIT}")Extracting Title
def extract_indeed_jobs(last_page):
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={4*LIMIT}")
soup = BeautifulSoup(result.text, 'html.parser')
results = soup.find_all("div", {"class":"jobsearch-SerpJobCard"})
for result in results:
title= result.find("h2", {"class":"title"}).find("a")["title"]
return jobs회사명 가져오기
soup 사용
python strip 사용.
for result in results:
title= result.find("h2", {"class":"title"}).find("a")["title"]
company = result.find("span",{"class":"company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company=str(company.string)
company = company.strip()장소 가져오기, 마무리
indeed.py
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("h2", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
"title": title,
"company": company,
"location": location,
"link": f"https://www.indeed.com/viewjob?jk={job_id}"
}
def extract_indeed_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping page {page}")
result = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, 'html.parser')
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobsmain.py
from indeed import extract_indeed_pages, extract_indeed_jobs
last_indeed_page = extract_indeed_pages()
indeed_jobs = extract_indeed_jobs(last_indeed_page)
print(indeed_jobs)stackoverflow scrapper
import requests
from bs4 import BeautifulSoup
URL = f"https://stackoverflow.com/jobs?q=python"
def get_last_page():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pages = soup.find("div", {"class": "s-pagination"}).find_all('a')
last_page = pages[-2].get_text(strip=True)
return int(last_page)
def extract_job(html):
title = html.find("h2", {"class": "fc-black-800"}).find("a")["title"]
company, location = html.find("h3", {
"class": "fc-black-700"
}).find_all(
"span", recursive=False)
company = company.get_text(strip=True)
location = location.get_text(strip=True).strip(" \r").strip("\n")
job_id = html["data-jobid"]
return {
"title": title,
"company": company,
"location": location,
"apply_link": f"https://stackoverflow.com/jobs/{job_id}"
}
def extract_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping SO: Page {page}")
result = requests.get(f"{URL}&pg={page+1}")
soup = BeautifulSoup(result.text, 'html.parser')
results = soup.find_all("div", {"class": "-job"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs
MAIN.PY
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
so_jobs = get_so_jobs()
indeed_jobs = get_indeed_jobs()
jobs = so_jobs + indeed_jobs
print(jobs)
파일로 옮기기
csv : comma seperated value
콤마로 구분하는 테이블 확장자. 어디에서나 쓸 수 있음.
파이썬은 csv 활용하는게 이미 탑재하고 있음.
기능 구현
새파일에 새 funtion 쓰기
save.py
import csv
def save_to_file(jobs):
file = open("jobs.csv", mode="w")
writer = csv.writer(file)
writer.writerow(["title", "company", "location", "apply_link"])
for job in jobs:
writer.writerow(list(job.values()))
return main.py
from indeed import get_jobs as get_indeed_jobs
from so import get_jobs as get_so_jobs
from save import save_to_file
so_jobs = get_so_jobs()
indeed_jobs = get_indeed_jobs()
jobs = so_jobs + indeed_jobs
save_to_file(jobs)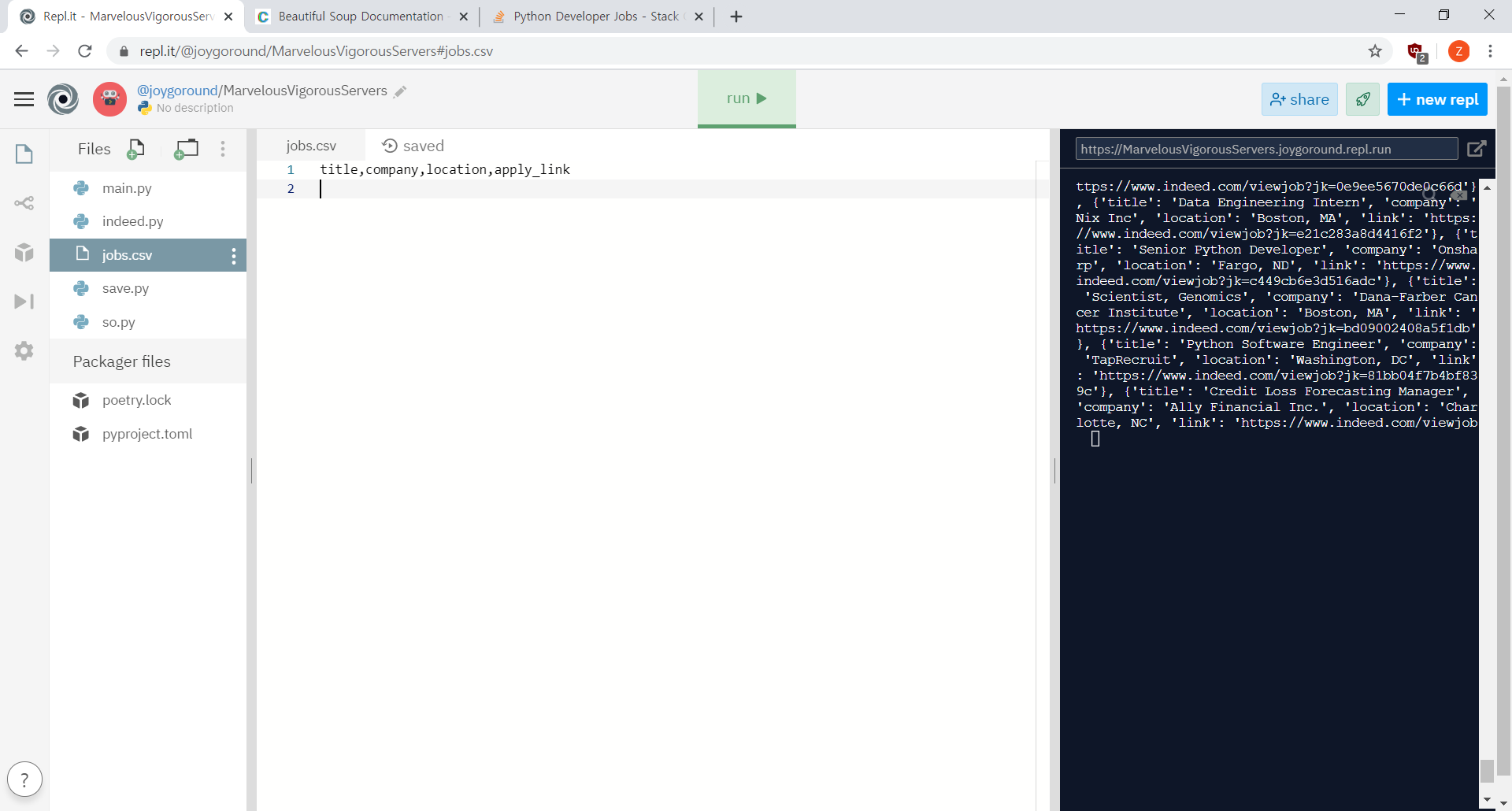
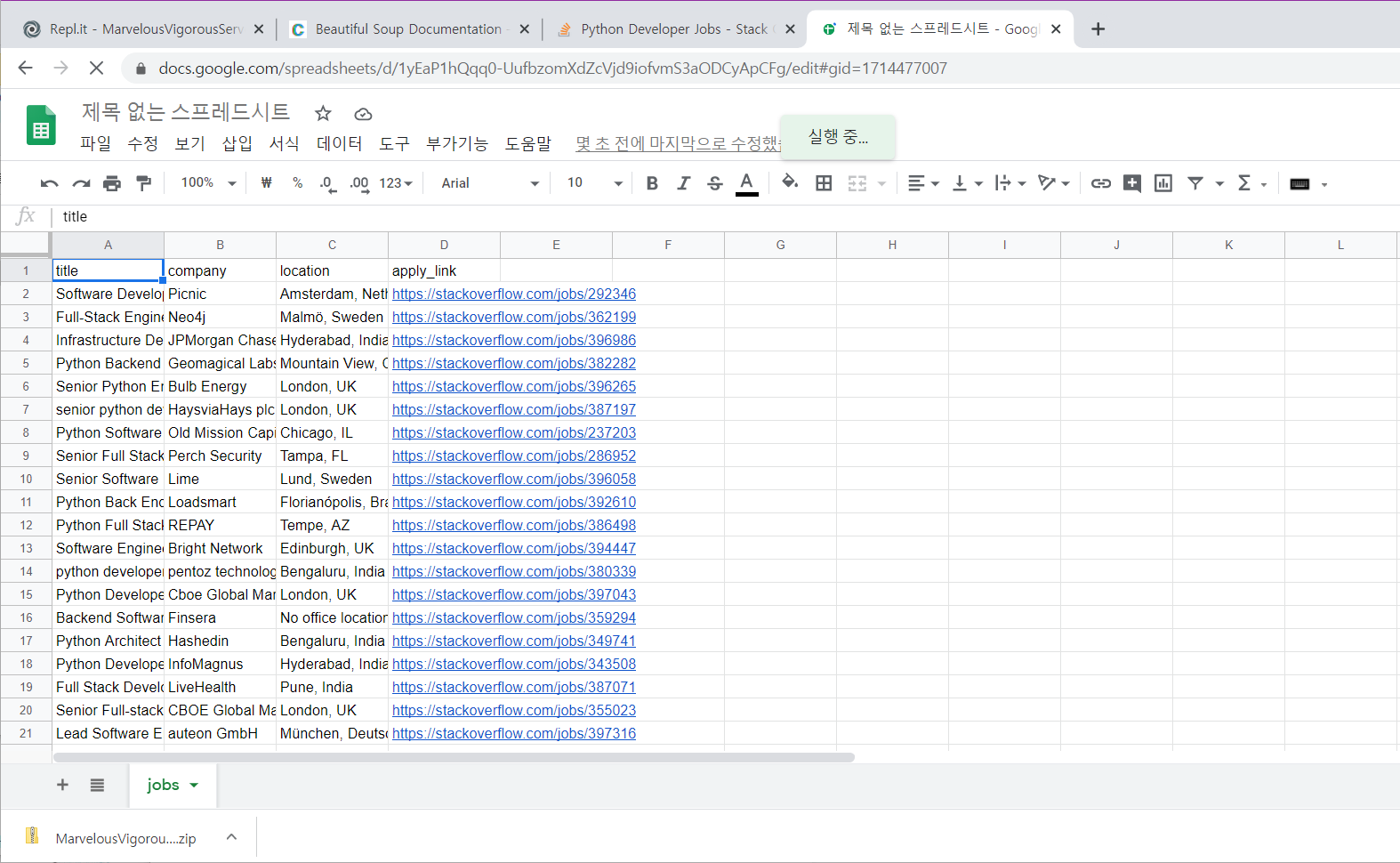
이렇게 csv 파일이 만들어짐.
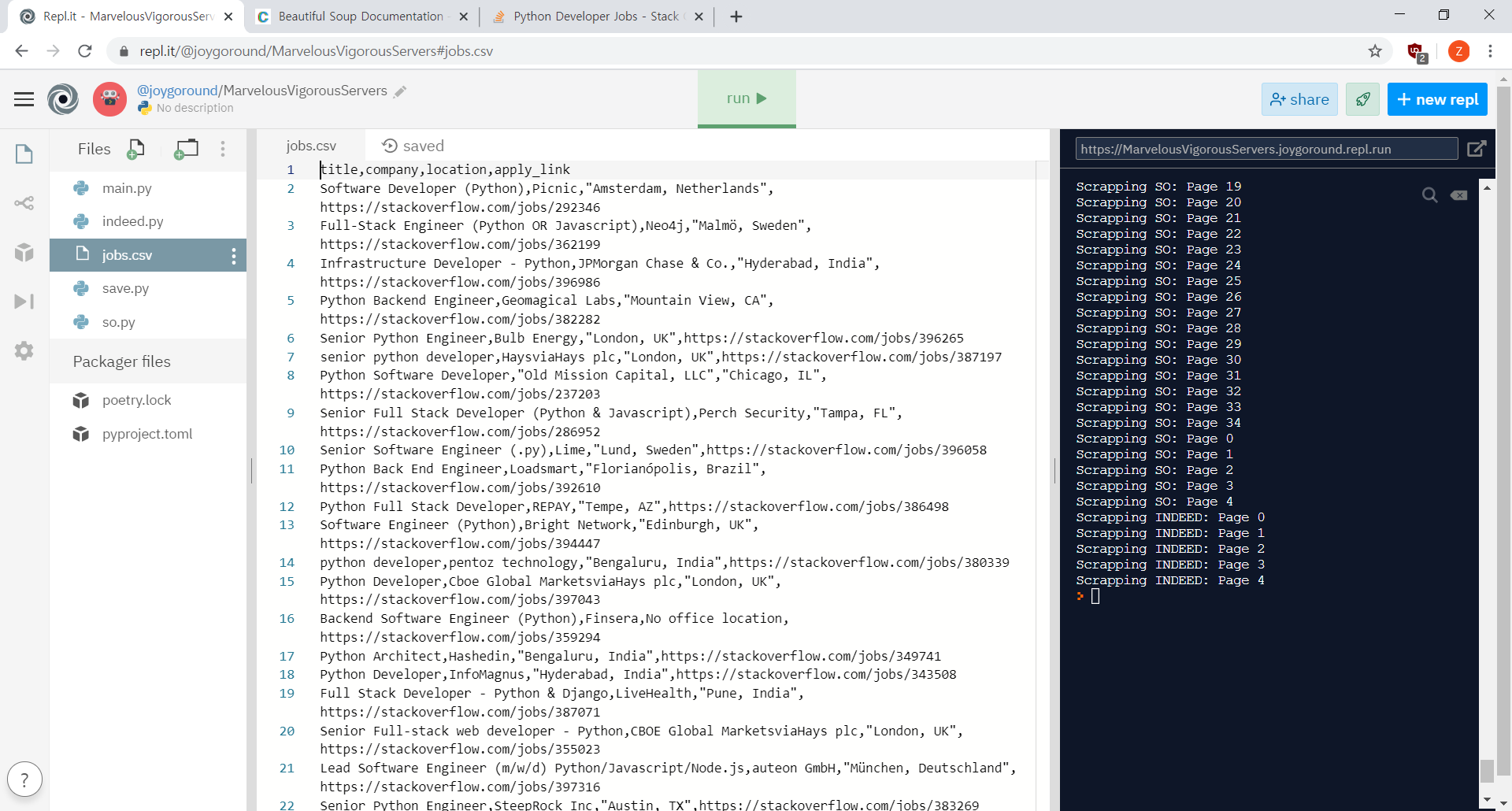
스프레드 시트에 가져와보기
repl it 이면 다운받기
스프레드시트에서 열기

roundy