1. 서비스 개요
정자 (Jeong Ja)
(’정확한 자문’)
- 목표: 일반 사용자가 법률 문서나 판례에 기반하여
정확하고 신뢰도 높은 국내 법률 상담을 받을 수 있도록 지원 - 핵심 기능:
- 법률 문서 및 판례 기반 질의응답
- AI 기반 질의 분류 및 적절한 도구 자동 호출
- 사용자 피드백 기반 반복 개선
- 스트리밍 대화 처리
- 기반 데이터: ‘최근 3년간의 법원도서관에서 제공한 판례공보’ 및 법률 문서(개인정보 보호법, 근로기준법, 주택임대차보호법)를 수집하여 벡터 데이터베이스(Pinecone)에 구축
근로기준법(법률)(제18176호)(20211119).pdf
개인정보 보호법(법률)(제19234호)(20240315).pdf
주택임대차보호법(법률)(제19356호)(20230719).pdf
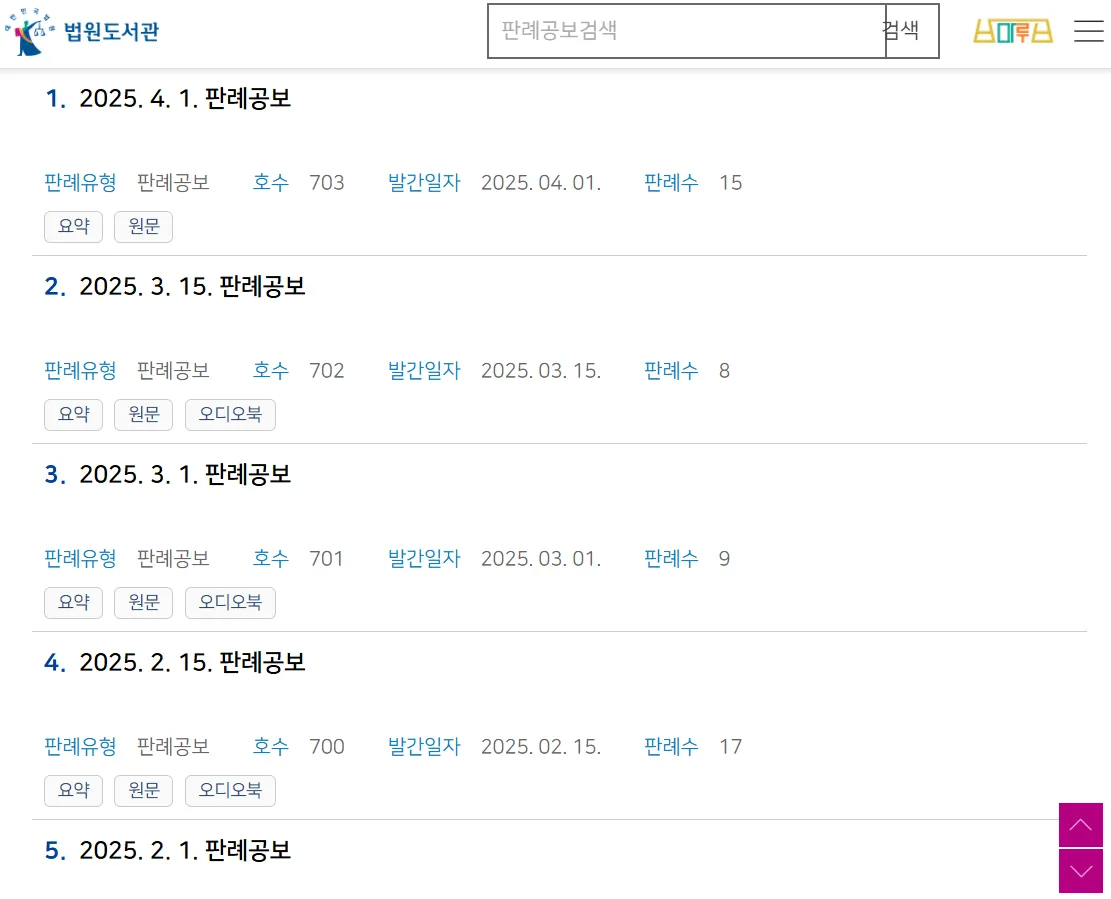
법원도서관 판례공보 페이지
2. 아키텍처 구성
2-1. 주요 아키텍처
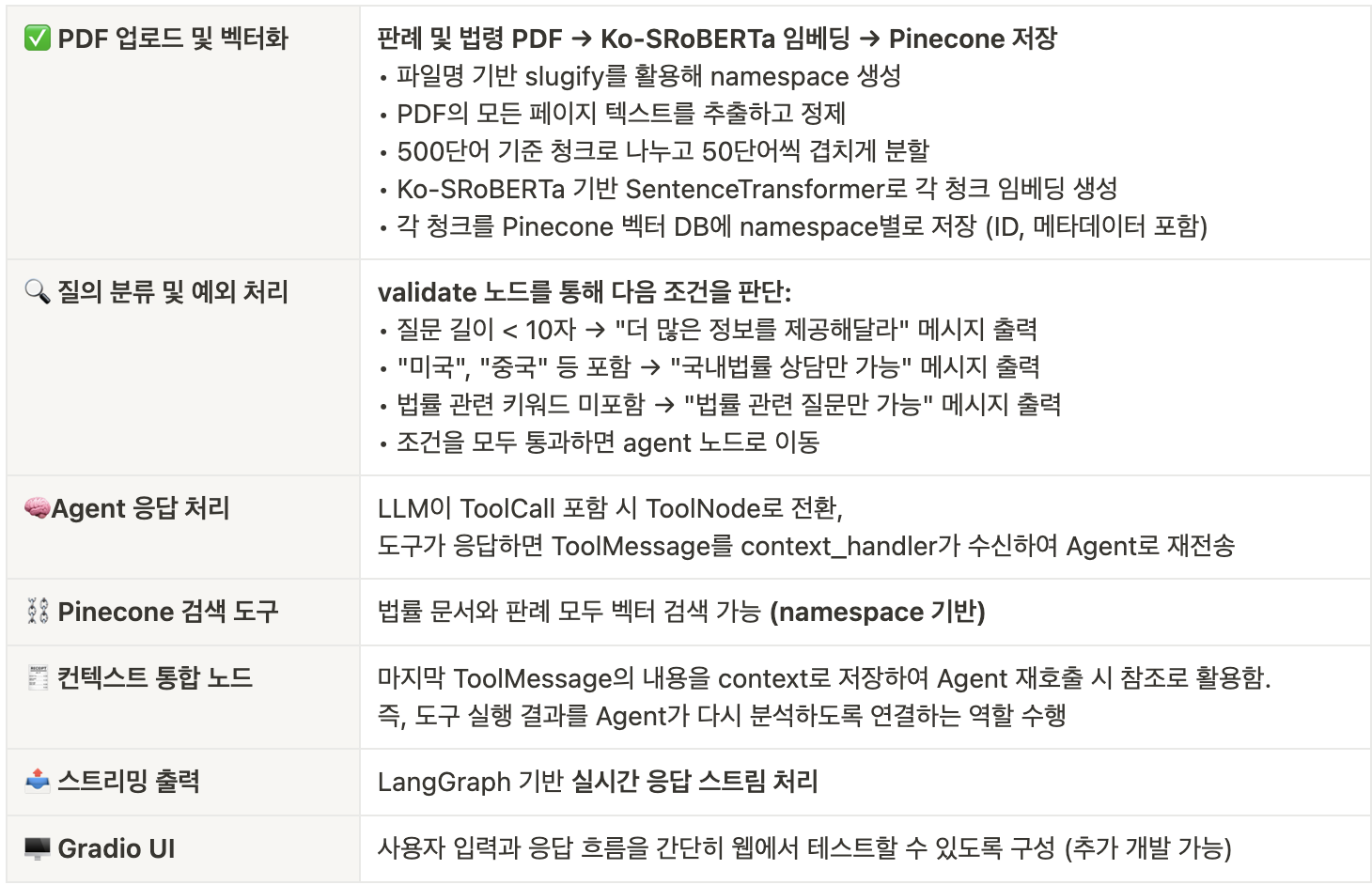
2-2. 기술 스택
- LangGraph: 멀티에이전트 그래프 처리 및 상태 관리
- Pinecone: 벡터 기반 법률 데이터베이스
- OpenAI GPT-4o: 고급 질의 이해 및 도구 호출
- SentenceTransformer (Ko-SRoBERTa): 한국어 문서 임베딩
- Gradio: 사용자용 인터페이스 (웹 기반)
2-3. LangGraph 기능

3. 아키텍처 Flow
3-1. 사용자 워크 플로우
사용자 질의가 들어오면 다음과 같은 흐름으로 처리됩니다

Langraph Workflow
- START → 사용자의 질의가 LangGraph에 입력됨
- Validator 노드에서 예외 처리 조건 확인
- 질문이 너무 짧거나 (10자 미만)
- 법률과 관련 없는 질문이거나
- 외국법 관련 질문인 경우
→ error 노드로 분기되어 안내 메시지를 생성하고 종료
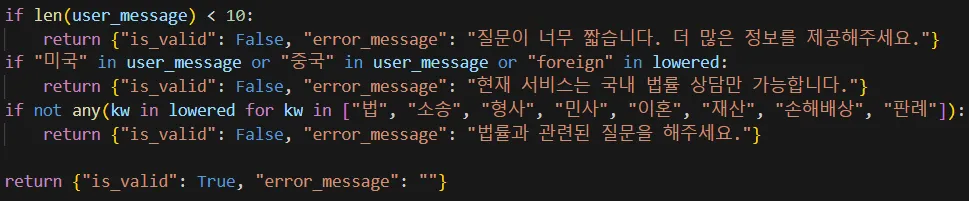
- 조건을 만족하는 유효한 질문이면 Agent 노드로 이동
- Agent Node에서 질문을 이해하고 필요한 경우 도구 호출을 위한 ToolCall을 생성
- 도구 호출이 있을 경우 ToolNode가 Pinecone에서 판례/법령 문서를 검색
- 검색 결과는 ToolMessage로 전달되며, context_handler 노드에서 해당 결과를 context로 저장
- Agent Node는 이 context를 포함하여 최종 응답을 생성
- 응답이 완료되면 END 노드로 흐름 종료
이러한 구조는 사용자의 질문을
분석 → 검증 → 벡터 검색 → ‘컨텍스트 통합’ → 답변 생성을
LangGraph 기반으로 순차적으로 처리합니다.
3-2. Agent 노드 정의
각 Agent 노드는 state: LegalState를 입력으로 받아,
특정 작업을 수행하고 상태를 갱신하여 반환합니다.
law_agent_node
기능: 문서 내 [법률 관련 정보] 섹션을 요약하여 반환합니다.
플로우:
state["context"]에서[관련 판례]이전 부분을 추출- 해당 내용을 자연스럽고 간결하게 요약 요청 (
law_prompt) - 결과는
law_output에 저장 - 메시지 스택에 응답 추가
예외 처리:
context가 없으면"법률 정보가 없습니다."반환
law_section = context.split("[관련 판례]")[0].replace("[법률 관련 정보]", "").strip()
law_prompt = f"다음 법률 정보를 자연스럽고 간결하게 정리해 주세요:\n{law_section}"case_agent_node
기능: 문서 내 [관련 판례] 섹션을 요약하여 반환합니다.
플로우:
context에서[관련 판례]이후 텍스트를 추출- 간결한 요약 요청 (
case_prompt) - 결과는
case_output에 저장 - 메시지 스택에 응답 추가
예외 처리:
[관련 판례]섹션이 없으면"관련 판례 정보가 없습니다."반환
case_section = context.split("[관련 판례]")[1].strip()
case_prompt = f"다음 판례 정보를 자연스럽고 간결하게 정리해 주세요:\n{case_section}"summary_agent_node
기능: 질문 + 법률 정보 + 판례 정보를 종합해 최종 답변을 생성합니다.
플로우:
messages[0].content로부터 질문 추출law_output과case_output을 조합- 종합적이고 자연스러운 답변 생성 (
summary_prompt) - 결과는
summary_output에 저장
summary_prompt = (
f"질문: {messages[0].content}\n"
f"법률 정보: {law_output}\n"
f"판례 정보: {case_output}\n"
f"위 정보를 바탕으로 종합적인 답변을 자연스럽게 작성해 주세요."
)4. UI 화면 구성
인터페이스 구성 설명
inputs
- gr.Textbox로 구성되어 있어, 사용자가 질문을 텍스트로 입력할 수 있습니다.
label="질문을 입력하세요": 텍스트 박스 위에 표시되는 라벨입니다.placeholder="예: 재산 분할 기준 알려줘": 사용자가 무엇을 입력할 수 있는지 힌트를 줍니다.
outputs
- 총 세 개의 Textbox로 구성되어 있으며 각각의 출력은 다음을 의미합니다:
- 법률 정보: 관련 법령이나 조항을 요약해 보여줍니다.
- 관련 판례: 법률적 판단에 참고할 수 있는 실제 사례(판례)를 제공합니다.
- 종합 답변: 위의 정보들을 바탕으로 일반인이 이해하기 쉬운 형태로 정리된 최종 답변입니다.
title & description
title="법률 상담 AI": 인터페이스 상단에 표시될 이름입니다.description="법률 관련 질문을 입력하면 법률 정보, 관련 판례, 종합 답변을 각각 제공합니다.": 어떤 기능을 하는 인터페이스인지 간략히 설명합니다.
질문 UI


답변 UI
5. Trouble Shooting
Troubleshooting
1. Chunk_size 설정의 문제
- LM이나 임베딩 모델은 길이 제한이 있음 (예: BERT 기반: 512 토큰 이하).
- 문서 전체를 한 번에 처리하면 메모리 초과, 의미 단위 파악 실패.
주요 파라미터
chunk_size=500: 한 덩어리로 자르는 최대 단어 수overlap=50: 문맥 보존을 위해 앞/뒤 덩어리 간 중첩- 처음에는
chunk_size=1000으로 시도
→ 작은 판례 파일에서는 문제 없지만, 긴 법령에서는 문맥 단절 혹은 모델 입력 제한 초과 발생. overlap없애고 처리했더니 답변에서 앞/뒤 내용 연결이 부자연스러움
→overlap=50적용해 문맥 유지.- 최종적으로 500/50 조합이 정확도, 속도, 메모리 사용 측면에서 균형이 가장 좋았음
2. Pinecone에서 text 검색 불가의 문제
발전 방향
- 검색 정확도 개선 (예: 쟁점 기반 세분 검색)
- 판례/법령 요약 고도화 (사건 개요 / 판단 이유 분리)
- Gradio 기반 사용자 UI 연동 (챗봇, 파일 업로드, 요약 다운로드)
- LangSmith 연동 통한 그래프 워크플로우 모니터링 및 추적
- 사용자 정의 문서 업로드 및 맞춤 분석 기능

안녕하세요