TRPO는 이미 리뷰를 마쳤습니다. 이번에는 PPO를 살펴보려고 합니다. PPO(Proximal Policy Optimization)의 정책 업데이트의 안정성, 이론적 근거(clip surrogate의 하한선 성질), surrogate objective 최적화의 기하학적 해석 측면에서 살펴보려고 합니다.
0. 들어가며: TRPO의 한계와 PPO의 등장
TRPO는 이론적으로 매우 강건한 알고리즘으로 monotonic improvement를 보장하지만이 구현 복잡합니다. 특히 2차 최적화, conjugate gradient, Fisher Information matrix 계산하는 과정이 만만치 않죠. 또, dropout, shared-parameter architecture에 비호환적인 특성때문에 PPO가 등장하게 되었습니다.
PPO는 TRPO의 핵심 아이디어인 정책 변화 억제(regulated update, KL divergence-related constraint)를 유지하면서, first-order method로 재설계한 알고리즘입니다.
1. 배경: 정책 경사 기반 강화학습의 일반적 구조
-
Policy Gradient 기본 수식
-
Vanilla PG 문제점:
- 이 방식은 데이터를 한 번 수집하고 나면, 그 데이터를 다시 사용하는 게 어렵습니다. 왜냐하면 정책이 업데이트되면, 이전 정책으로 모은 데이터는 지금의 정책과 분포가 다르기 때문입니다.
- 또, 한 번의 업데이트로 정책이 너무 크게 바뀌면, 새 정책이 이전보다 훨씬 더 나쁜 행동을 하게 될 수도 있어서, 학습 성능이 갑자기 망가질 수 있습니다.
- TRPO는 이를 surrogate objective 최적화와 KL constraint로 해결
2. TRPO
-
Surrogate objective:
-
Trust region constraint:
-
performance difference bound (Kakade & Langford 2002)로부터 파생됨
3. PPO: Trust Region의 근사!
-
TRPO의 hard constraint를 대체하기 위한 두 가지 접근:
-
KL penalty term 사용
→ 적절한 β 튜닝 어려움
-
Clipped surrogate objective (PPO의 주력 방식)
- 은 허용 가능한 정책 이동 범위 (e.g., 0.2)
- clip을 통한 하한선 조정 → overly optimistic update 방지
- 근방에서 1차 근사로는 CPI와 동일한 값을 가짐
-
4. 직관!: 왜 min(clipped, unclipped)가 하한선을 구성하는가
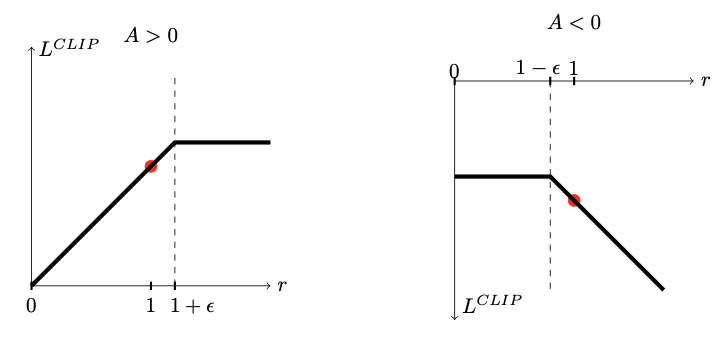
- Advantage가 양수일 때: 증가 유도, 과도하면 clip이 억제
- Advantage가 음수일 때: 감소 유도, 과도하면 clip이 억제
- 따라서 objective는 항상 conservative하게 작동 → 정책 변경을 안전한 영역에 국한
5. PPO의 학습 구조와 계산 그래프 관점
-
기존 policy gradient와 동일한 구조에서 손실 함수만 교체:
-
Clipping을 통해 surrogate gradient의 크기를 직접 제한 → implicit trust region 형성
-
여러 epoch 동안 동일 데이터에서 학습 가능 (on-policy but sample-efficient)
[1] : 정책 최적화 항 (Policy Surrogate Loss)
-
PPO의 핵심. 정책을 업데이트하되 지나친 확률 변화는 억제함.
-
수식:
- : 정책 변화의 비율
- : 이득 (advantage), 행동이 얼마나 좋았는지를 나타냄
-
의미:
- : 보통의 policy gradient 항
- clip을 통해 가 범위를 넘으면 gradient가 꺾임
- → 큰 정책 변화 방지 = 안정성 확보
-
계산 그래프 관점:
- 대부분의 gradient는 clipping 이전 경로를 따르지만, 일정 이상 변화에서는 gradient가 0으로 고정됨 (flat region)
- 이는 Trust Region을 직접 구현하지 않으면서도 비슷한 효과를 갖게 함
[2] : 상태 가치 함수 오차 (Value Function Loss)
-
상태 가치 가 실제 return을 잘 예측하게 유도
-
수식:
-
목적:
- value function이 정확해야 GAE 등 advantage 추정이 안정적임
-
계산 그래프 관점:
- 정책 네트워크와 value network가 파라미터를 공유하는 경우, 이 항은 shared parameter에 추가적인 gradient를 주게 됨
- 그로 인해 정책 학습과 가치 학습의 균형이 중요 → 가중치 사용
[3] : 엔트로피 보너스 (Entropy Bonus)
-
정책의 확률 분포 가 너무 확신을 갖지 않도록 유도
-
수식 (이산 정책의 경우):
-
목적:
- exploration 유지 → premature convergence 방지
- 특히 초기 학습 단계에서 다양한 행동 시도 유도
-
계산 그래프 관점:
- 로그 소프트맥스 구조에서 발생하는 음의 gradient는 확률을 평탄하게 유지
- 따라서 초기에는 다양하게 행동하고, 나중에는 sharpen됨
[4] 각 항의 의미적 역할
| 항목 | 목적 | Gradient 관점 | PPO에서의 역할 |
|---|---|---|---|
| 정책 업데이트 안정화 | gradient clipping by design | implicit trust region | |
| value function 학습 | shared parameter이면 영향 큼 | advantage estimator 안정화 | |
| 탐색 유지 | 확률 flattening | exploration 유도 |
6. 실험 결과 정리 및 이론적 의의
-
MuJoCo 7개 환경 실험: PPO(clip)는 거의 모든 환경에서 TRPO나 A2C보다 높은 normalized score 기록
-
Atari: PPO는 fast learning에 유리 (초기 episode reward가 빠르게 상승)
-
이론 vs 실험:
- clipped objective는 hard constraint 없이도 유사한 수렴 안정성 확보
- 특히 dropout, shared policy/value nets 같은 최신 구조와 호환성 확보
7. PPO vs TRPO: 이론 및 구현 비교
| 항목 | TRPO | PPO |
|---|---|---|
| 이론적 근거 | monotonic performance bound | surrogate 하한선 heuristic |
| 정책 이동 제어 | hard KL constraint | clipped objective or adaptive penalty |
| 최적화 방법 | 2차 (conjugate gradient) | 1차 (SGD, Adam 등) |
| 구현 난이도 | 높음 | 낮음 |
| 아키텍처 제한 | 많음 | 거의 없음 |
| 샘플 재사용 | 제한적 | 여러 epoch 가능 |
8. 결론 및 향후 고찰
-
PPO는 TRPO의 핵심 원칙을 유지하면서 "이론적 직관 + 실용성"의 좋은 절충점
-
하지만 monotonic improvement에 대한 formal한 보장은 없음 (lower bound 해석은 heuristic)
-
이후 연구들에서 PPO는 거의 default RL 알고리즘처럼 사용됨
- e.g., Dreamer, OpenAI Five, Robotics 등
