
이번 3주차에서는 간단히 파이썬 문법들을 배워보고, 파이썬을 통해 웹 크롤링을 해보았다 !
크롤링이란 ? 👾
: 웹사이트(website), 하이퍼링크(hyperlink), 데이터(data), 정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것.
또한크롤링을 위해 개발된 소프트웨어를크롤러(crawler)라고 한다.크롤러는 주어진인터넷 주소(URL)에 접근하여 관련된 URL을 찾아내고, 찾아진 URL들 속에서 또 다른하이퍼링크(hyperlink)들을 찾아 분류하고 저장하는 작업을 반복함으로써, 여러 웹페이지를 돌아다니며 어떤 데이터가 어디에 있는지색인(index)을 만들어데이터베이스(DB)에 저장하는 역할을 한다.
- 출처 : 네이버 지식백과
 3주차 숙제는 지니 뮤직 차트 크롤링하기 👾
3주차 숙제는 지니 뮤직 차트 크롤링하기 👾
 차트를 크롤링해서 위와 같은 결과를 도출하는 게 오늘 목표이다 🔥
차트를 크롤링해서 위와 같은 결과를 도출하는 게 오늘 목표이다 🔥
 가장 먼저 차트 1위부터 50위까지 나와있는 곡 리스트 데이터를 가져오기 위해 다음과 같이 곡이 있는 페이지에서 마우스 오른쪽 버튼 ➡️ 검사(inspect)를 누른 후, 곡 하나에 해당하는 코드를 찾아 선택해
가장 먼저 차트 1위부터 50위까지 나와있는 곡 리스트 데이터를 가져오기 위해 다음과 같이 곡이 있는 페이지에서 마우스 오른쪽 버튼 ➡️ 검사(inspect)를 누른 후, 곡 하나에 해당하는 코드를 찾아 선택해 'Copy Selector'를 실행하였다.
그 때 복사된 코드는 다음 사진에서 마지막 줄에 해당하는데,
 주어진 기본 코드에 적용하는 방법은 다음과 같다.
주어진 기본 코드에 적용하는 방법은 다음과 같다.
(일단 mongoDB를 사용하지 않기 때문에 Line4-6은 삭제해도 된다.)
1. 파이썬에서 유명한 requests라는 라이브러리 불러오기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)그리고 requests를 통해 데이터를 얻어올(get) url 자리에 지니 뮤직 페이지 주소를 넣어 주었다. ➡️ http에 get 요청을 한다.
2. BeautifulSoup 라이브러리를 통해 파이썬이 이해할 수 있는 객체 구조로 만들기
soup = BeautifulSoup(data.text, 'html.parser')아쉽게도 requests는 객체 구조로 변환하는 것까지는 하지 못한다고 한다. 따라서 BeautifulSoup은 html 소스코드를 가져오고, 파이썬에 내장된 'html.parser'을 이용하여 html 소스코드를 파이썬 객체로 변환할 것이다.
3. 객체들을 리스트로 반환하는 select를 이용하여 원하는 데이터 보기
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')웹페이지에서 1위 곡 뿐만 아니라 다른 곡들도 살펴보았을 때, 복사된 코드에서 공통된 부분이 있는 것을 찾을 수 있다. 그 부분을 select 해서 변수 trs에 넣어주었다. ➡️ 뒷 부분에 있던 nth-child는 구조 선택자 이다.
이제 출력을 위한 for문 작성 시작 ! ✏️
 for문을 돌 때마다 각 리스트 항목들에 대해 곡명만 추출하여 변수 title에 넣는다. 이미 trs에 넣어놓은 코드와 중복되지 않는 부분만 넣어주면 되고, 그 중 제목만 출력하기 위해
for문을 돌 때마다 각 리스트 항목들에 대해 곡명만 추출하여 변수 title에 넣는다. 이미 trs에 넣어놓은 코드와 중복되지 않는 부분만 넣어주면 되고, 그 중 제목만 출력하기 위해 .text를 사용했다.
또한 위에서 select를 사용한 것과 다르게 여기선 제목 하나만 선택하므로 select_one을 사용한다는 것도 포인트 중 하나 ! ⭐️
Run 해보면 이렇게 무지막지한 공백이 넘치는 것을 알 수 있다. 어떻게 해결해야 하지 ?
 뭐 어쩌겠는가, 또 구글링 !
뭐 어쩌겠는가, 또 구글링 !
구글링을 통해 파이썬에서 공백을 제거하는 함수 중 .strip() 함수를 사용해보았다.
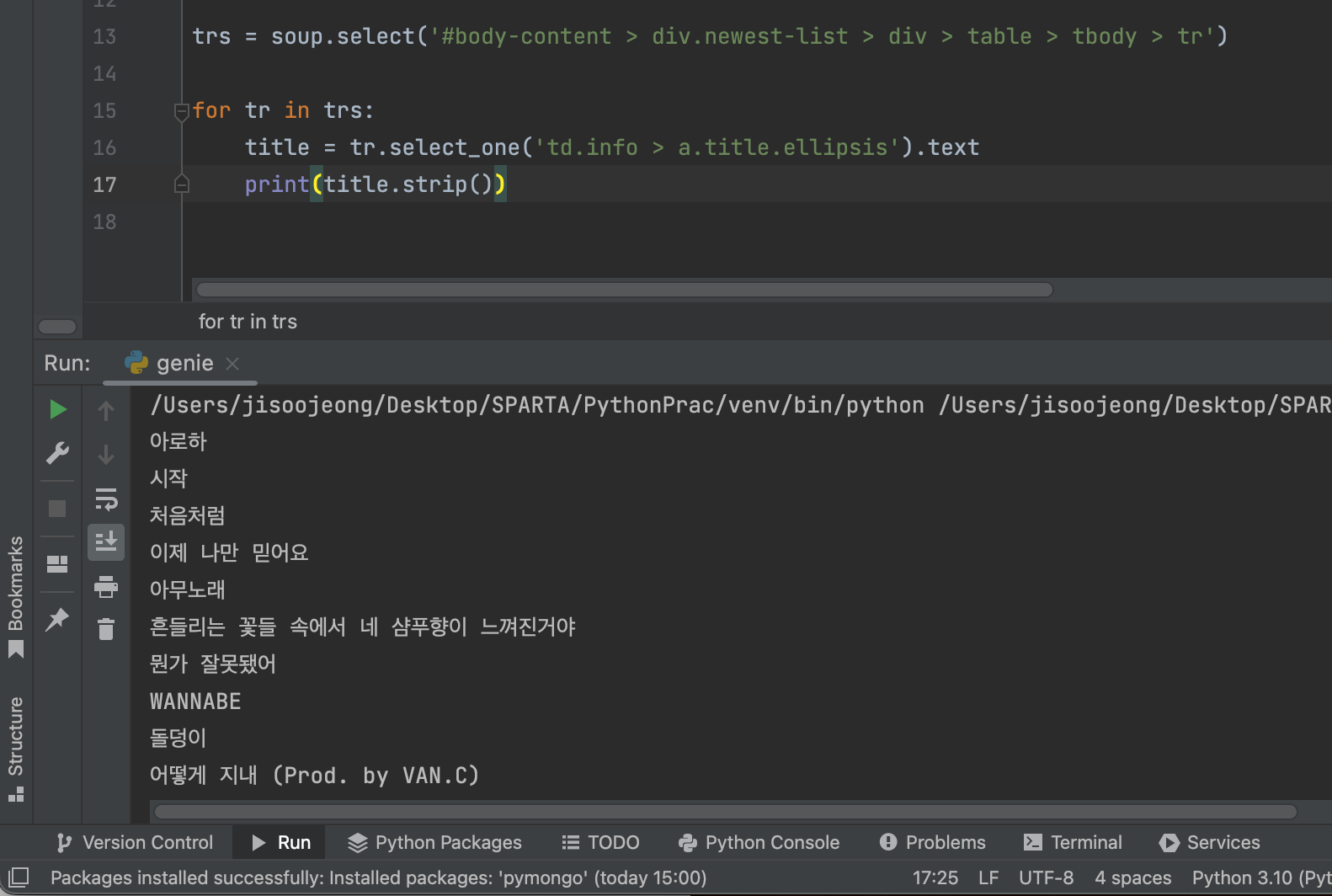 그럼 이렇게 원하는 대로 제목만 나오게 된다. ^^V
그럼 이렇게 원하는 대로 제목만 나오게 된다. ^^V
같은 방식으로 랭크도 출력해보겠다.
 여기서 문제점은 각 곡의 랭크 뿐 만이 아니라, 그 시간대에 얼마나 랭크가 오르고 떨어졌는지까지 같이 출력된다는 점이다.
여기서 문제점은 각 곡의 랭크 뿐 만이 아니라, 그 시간대에 얼마나 랭크가 오르고 떨어졌는지까지 같이 출력된다는 점이다.
 일단 숫자만 출력하기 위해 위와 같이
일단 숫자만 출력하기 위해 위와 같이 .text 를 사용하였다.
 다음으로 또 구글링 .. 랭크만 똑 ! 따내기 위해 파이썬에서 문자열을 자르는 함수를 찾아보았다.
다음으로 또 구글링 .. 랭크만 똑 ! 따내기 위해 파이썬에서 문자열을 자르는 함수를 찾아보았다.
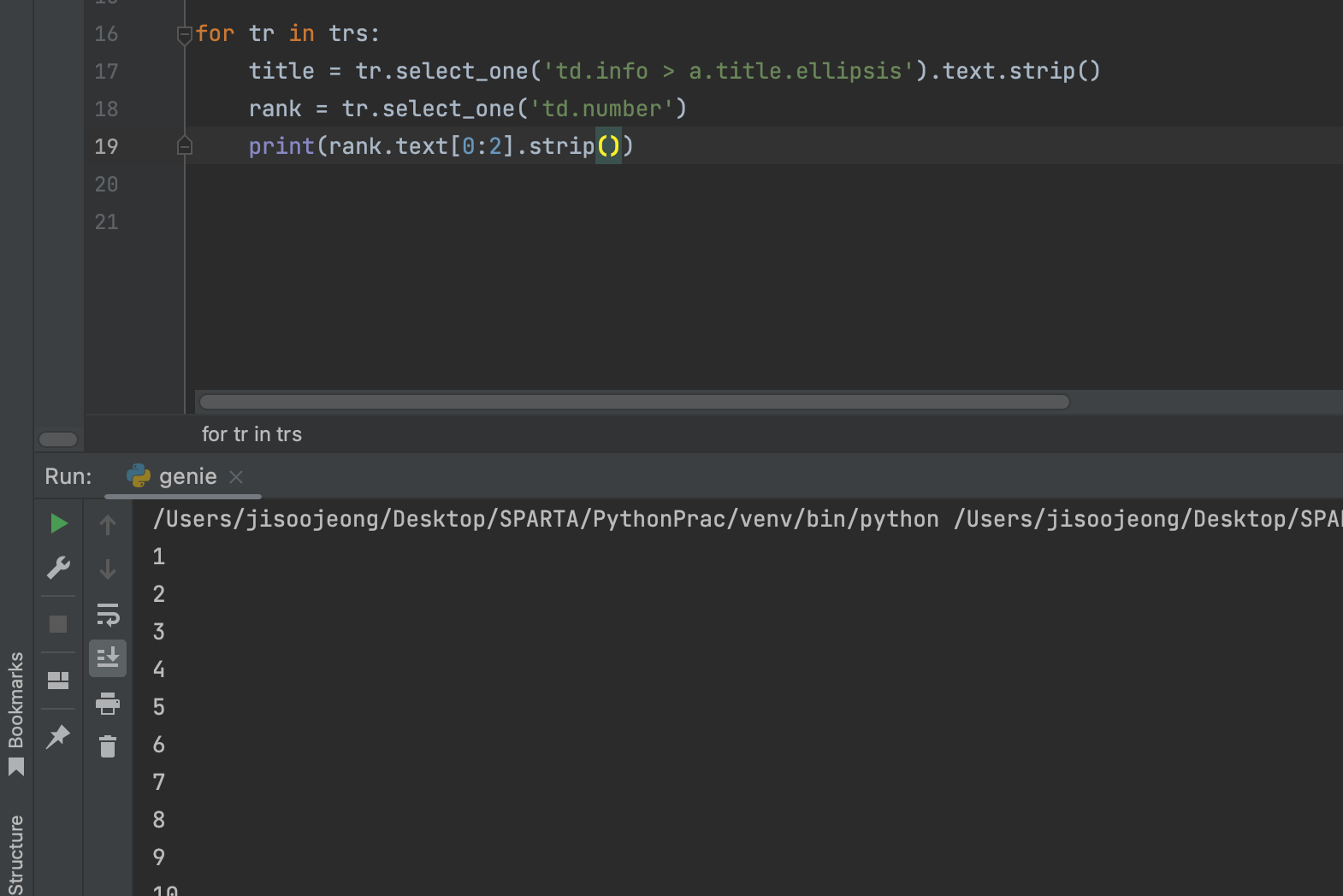 그래서 곡마다 숫자 두개만 똑 ! 따내기 위해 [0:2]를 사용했으나, 여기서 문제점은 한 자리 수는 또 공백을 동반시킨다는 점 ..
그래서 곡마다 숫자 두개만 똑 ! 따내기 위해 [0:2]를 사용했으나, 여기서 문제점은 한 자리 수는 또 공백을 동반시킨다는 점 ..
그래서 마지막으로 위에서 사용했던 .strip() 함수까지 사용했더니, 원하는대로 랭크만 나왔다 !
 같은 방식으로 가수까지 만들어준 후에 출력하면 끝 ! 그럼 처음에 목표했던 형태가 출력된다.
같은 방식으로 가수까지 만들어준 후에 출력하면 끝 ! 그럼 처음에 목표했던 형태가 출력된다.
👩🏻💻 이번 주차는 간단하게 파이썬도 다뤄보고, 이를 통해 데이터를 다루는 법과 웹 크롤링까지 해보았다. 무엇이든지 처음이 가장 어려운 법 ! 파이썬과 조금 더 친해진 느낌이 든다. 무엇보다 파이썬에 이렇게 다양한 라이브러리가 있다는 것을 또 한 번 경험하면서 마무리한다. 앞으로도 쓸 일이 많겠지 ? 👾
