캐시, 언제 도입해야 할까? — 판단 기준
캐시가 답이 되는 상황은 분명히 존재합니다. 하지만 그게 언제인지 알려면 명확한 기준이 필요합니다.
이 글에서는 캐시 도입을 결정할 때 쓰는 4가지 조건, 4가지 부적합 케이스, 그리고 실전 도입 순서를 정리해보겠습니다.
캐시가 적합한 4가지 조건
조건 1 — 읽기 빈도 >> 쓰기 빈도 (가장 흔한 시그널)
핵심 질문: "이 데이터는 얼마나 자주 읽히고, 얼마나 자주 바뀌는가?"
캐시의 가치는 같은 데이터를 반복해서 읽을 때 발생합니다.
[적합한 예시]
쇼핑몰 — 상품 상세 정보
읽기: 상품 페이지 조회 (초당 수백 회)
쓰기: 상품 정보 수정 (하루 1~2회)
→ 읽기:쓰기 = 수만:1 → 캐시 적합
서비스 공통 — 카테고리 목록, 공지사항
읽기: 모든 페이지 진입마다 조회
쓰기: 관리자가 한 달에 몇 번 수정
→ 캐시 적합
[부적합한 예시]
쇼핑몰 — 실시간 재고 수량
읽기: 상품 페이지 조회마다
쓰기: 주문 발생마다 차감
→ 읽기:쓰기 비율이 비슷 → 캐시 부적합읽기/쓰기 비율을 수치로 확인하고 싶다면:
SELECT
table_name,
rows_read,
rows_inserted + rows_updated + rows_deleted AS rows_written,
rows_read / NULLIF(rows_inserted + rows_updated + rows_deleted, 0) AS read_write_ratio
FROM information_schema.table_statistics
WHERE table_schema = 'your_database'
ORDER BY read_write_ratio DESC;
-- read_write_ratio > 10 → 캐시 효과 있음
-- read_write_ratio < 3 → 캐시 효과 미미조건 2 — DB 조회 비용이 높다
핵심 질문: "이 쿼리를 매번 실행하면 얼마나 비싼가?"
[비용이 높은 케이스 — 캐시 적합]
케이스 1: 복잡한 집계 쿼리
SELECT category_id,
COUNT(p.id) AS product_count,
AVG(p.price) AS avg_price,
SUM(CASE WHEN p.status = 'SOLD_OUT' THEN 1 ELSE 0 END) AS sold_out_count
FROM product p
GROUP BY category_id;
실행시간: 200~500ms (상품 수만 건 기준)
호출 빈도: 메인 화면 진입마다
→ 캐시 없으면 메인 화면이 느림 → 캐시 적합
케이스 2: 다중 테이블 JOIN
SELECT u.name, COUNT(o.id) AS order_count, SUM(o.amount) AS total_amount
FROM orders o
JOIN users u ON o.user_id = u.id
JOIN order_items oi ON o.id = oi.order_id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 7 DAY)
GROUP BY u.id;
실행시간: 1~3초
→ 매번 실행하면 사용자 경험 최악 → 캐시 적합
케이스 3: 외부 API 응답
결제 수단 목록, 환율 정보 등 외부 API
응답시간: 평균 300ms / 최대 2초
변경 주기: 거의 없음
→ 캐시 없으면 매번 외부 API 왕복 발생 → 캐시 적합
[비용이 낮은 케이스 — 캐시 불필요]
PK 단건 조회
SELECT * FROM product WHERE id = ?
실행시간: 1~5ms (PK 인덱스 활용)
→ 캐시 도입 비용 > 절약 효과 → 인덱스면 충분비용이 높은 쿼리는 슬로우 쿼리 로그로 먼저 확인합니다.
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 0.1; -- 100ms 이상 쿼리 수집
SELECT * FROM mysql.slow_log
ORDER BY query_time DESC
LIMIT 20;조건 3 — 결과가 자주 바뀌지 않는다 (TTL 안에 변경 가능성 낮음)
핵심 질문: "TTL이 만료되기 전에 이 데이터가 바뀔 확률은?"
데이터의 변경 주기에 따라 TTL을 설계해야 합니다.
| 데이터 유형 | 적절한 TTL |
|---|---|
| 설정값, 코드성 데이터 (카테고리, 결제 수단 종류) | 1시간 ~ 1일 |
| 사용자 프로필 기본 정보 | 10~30분 |
| 콘텐츠 메타 정보 | 5~10분 |
| 요약/집계 통계 | 1~5분 |
| 실시간 데이터 (재고, 잔액) | TTL 적용 자체가 부적합 |
[변경 주기 vs TTL 판단]
변경 주기가 1주일인 데이터에 TTL 10분 설정
→ 변경 거의 없는데 10분마다 캐시 미스 + DB 조회 반복
→ TTL을 더 길게 (1시간 이상)
변경 주기가 1분인 데이터에 TTL 10분 설정
→ 최대 10분간 stale 데이터 노출
→ TTL을 짧게 (30초 이하) or 캐시 포기조건 4 — 약간의 지연을 허용할 수 있다 (Eventual Consistency)
핵심 질문: "이 데이터가 최신값이 아니어도 비즈니스에 문제가 없는가?"
[허용 — 캐시 적합]
인기 상품 랭킹
실제: 5분 전 데이터
사용자 인식: "인기 상품 목록"이 정확히 실시간일 필요 없음
→ TTL 5분 캐시 적합
상품 리뷰 수
실제: 1분 전 데이터
사용자 인식: 리뷰 수가 1개 오차여도 무방
→ TTL 1분 캐시 적합
[불허 — 캐시 부적합]
계좌 잔액 → "방금 입금했는데 잔액이 안 바뀜" → 심각한 사용자 불신
쿠폰 사용 여부 → 이미 사용한 쿠폰을 "미사용"으로 읽음 → 중복 사용
재고 수량 → 재고 0인데 캐시에서 1개로 읽음 → 주문 오류캐시가 부적합한 4가지 케이스
케이스 1 — 실시간 정합성이 필수인 데이터
[잔액]
사용자 A: 잔액 10,000원 → 캐시(TTL 5분) → 9,000원 사용
캐시에는 여전히 10,000원 → 다시 9,000원 결제 시도
→ 실제 잔액 1,000원인데 통과 → 심각한 오류
→ 해결: 잔액 조회는 항상 DB Primary에서 직접 조회
[재고]
재고 1개 남음 → 캐시에 1개 → 동시 주문 2건
둘 다 캐시에서 1개 읽음 → 둘 다 주문 성공처리 → 재고 -1
→ 해결: 재고 확인은 DB 비관적 락으로 처리. 캐시 사용 안 함.케이스 2 — 쓰기 빈도가 높다
캐시는 무효화(invalidation) 비용이 존재합니다. 쓰기가 잦으면 캐시 히트율이 낮아져 의미가 없습니다.
히트율 = (읽기 빈도 - 무효화 횟수) / 읽기 빈도
읽기 100, 쓰기(무효화) 80 → 히트율 = 20/100 = 20% → 캐시 불필요
읽기 100, 쓰기(무효화) 5 → 히트율 = 95/100 = 95% → 캐시 효과적케이스 3 — 데이터 다양성이 높다
[개인화된 추천 목록]
사용자마다 추천이 다름 → 캐시 키 10만 개 × 1KB = 100MB (과도)
히트율: 사용자 재방문율에 따라 낮음
→ 추천 결과를 사전 계산해서 DB에 저장하는 것이 낫다
[동적 쿼리 파라미터 조합]
카테고리 × 가격대 × 정렬 × 페이지 → 조합 수: 50 × 10 × 5 × 100 = 250,000가지
대부분의 조합은 1회 조회 후 다시 안 씀 → 히트율 낮음
→ 인기 검색 조합 TOP 100만 선별 캐시하는 것이 효율적케이스 4 — 캐시 관리 비용 > 성능 이득
인덱스 하나로 해결되는 문제에 캐시를 붙이는 것이 대표적인 케이스입니다.
Before: 인덱스 없는 쿼리 → 500ms
→ 캐시 도입 고려
After: 인덱스 추가 → 2ms
→ 캐시 불필요
캐시 도입 시 추가 비용:
Redis 서버 관리 + 무효화 로직 + 정합성 모니터링
→ 이 비용이 2ms 절약 효과보다 크다캐시 도입 순서 원칙
단계 1 — 측정 먼저
측정 없이 캐시 도입하면:
개발자: "이 쿼리 느릴 것 같아서 캐시 달았어요"
실제: 이 쿼리 실행시간 5ms / 캐시 Redis 왕복 10ms
결과: 캐시가 오히려 더 느림 + 운영 복잡도만 증가APM에서 P95 응답시간이 느린 API를 먼저 찾고, 슬로우 쿼리 로그로 병목 쿼리를 확인한 뒤 캐시 대상을 선정합니다.
단계 2 — 인덱스 튜닝 → 쿼리 최적화 → 캐시 순서
캐시는 마지막 수단입니다.
문제 쿼리 (1.2초)
Step 1: EXPLAIN으로 실행계획 확인 → type: ALL (풀스캔) 발견
Step 2: 인덱스 추가 → 1.2초 → 150ms
Step 3: 쿼리 리팩토링 → 150ms → 80ms
Step 4: 80ms도 여전히 느리고 자주 호출됨 → 캐시 도입 → 2ms인덱스만으로 1.2초 → 80ms, 캐시는 80ms → 2ms.
인덱스 튜닝의 임팩트가 훨씬 컸습니다. 순서를 지키지 않으면 인덱스 문제를 영원히 모르고 지나칩니다.
단계 3 — 히트율 목표 설정 (80% 이상)
redis-cli INFO stats | grep hit
keyspace_hits: 85000
keyspace_misses: 15000
# 히트율 = 85000 / (85000 + 15000) = 85% → 적정 수준히트율이 낮다면 원인을 먼저 진단합니다.
| 원인 | 해결 |
|---|---|
| TTL이 너무 짧음 | TTL 늘리기 |
| 캐시 키 설계 문제 | 같은 데이터를 다른 키로 중복 저장하는지 확인 |
| 데이터 다양성 너무 높음 | 캐시 대상 재검토 |
| 배포 직후 Cold Start | 캐시 워밍 도입 |
단계 4 — 트레이드오프를 명시하고 결정한다
캐시 도입은 항상 읽기 성능 vs 정합성 지연의 트레이드오프입니다. 결정한 내용을 코드 주석이나 ADR로 남겨야 합니다.
// 카테고리별 통계는 최대 5분 지연될 수 있음 (TTL 기반 캐시)
// 실시간 정확도가 필요하면 캐시 무효화 이벤트 추가 필요
@Cacheable(value = "category-stats", key = "#categoryId")
public CategoryStatsResponse getCategoryStats(Long categoryId) {
return calculateStats(categoryId);
}데이터별 캐시 적합성 판단표
┌──────────────────────┬──────┬──────┬──────────┬──────┬─────────────┐
│ 데이터 │읽기 │쓰기 │지연 허용 │비용 │ 결정 │
├──────────────────────┼──────┼──────┼──────────┼──────┼─────────────┤
│ 상품 상세 정보 │ 높음 │ 낮음 │ O │ 중 │ 캐시 적합 │
│ 카테고리 목록 │ 높음 │ 낮음 │ O │ 낮 │ 캐시 적합 │
│ 집계/통계 요약 │ 높음 │ 중간 │ O │ 높 │ 캐시 적합 │
│ 재고 수량 │ 높음 │ 높음 │ X │ 중 │ 캐시 불가 │
│ 결제/주문 상태 │ 중간 │ 중간 │ X │ 낮 │ 캐시 불가 │
│ 사용자 인증 정보 │ 높음 │ 낮음 │ O │ 낮 │ 세션 캐시 │
│ 개인화 추천 목록 │ 중간 │ 낮음 │ O │ 높 │ DB 저장 권장│
└──────────────────────┴──────┴──────┴──────────┴──────┴─────────────┘캐시 계층 구조 — L1과 L2를 함께 쓰는 이유
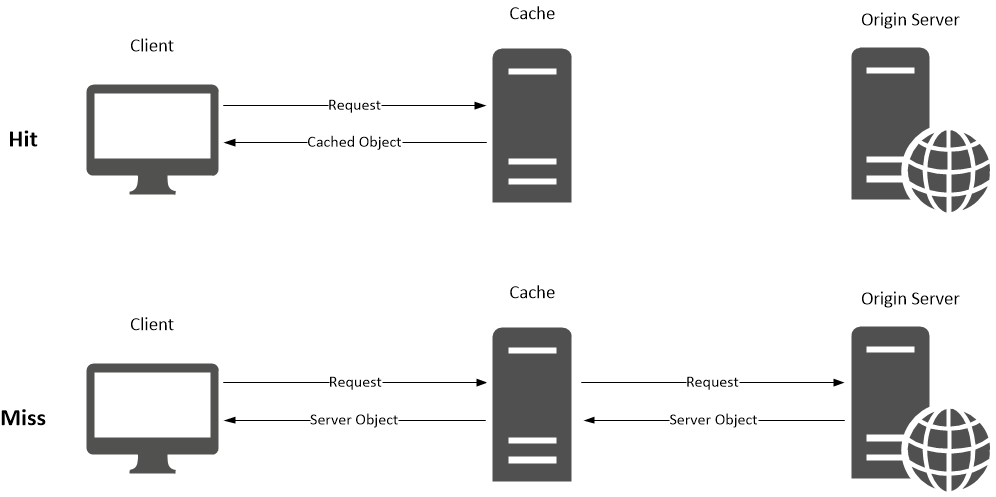
캐시를 도입하기로 결정했다면, 다음 질문은 "어느 계층에 둘 것인가" 입니다.
L1 — 로컬 캐시 (In-Process)

애플리케이션 프로세스 안(JVM 힙)에 데이터를 저장합니다. 네트워크 왕복이 없어서 나노초 단위로 응답합니다.
장점: 극한의 속도 (~100ns), 직렬화 비용 없음
단점: 서버 재시작 시 소멸 / 인스턴스 간 공유 불가
도구: Caffeine, ConcurrentHashMap
적합: 카테고리 목록, 코드성 데이터처럼 변경이 거의 없는 것한계 ① — 서버 재시작 시 캐시 소멸 (Cache Cold Start)
JVM 프로세스가 종료되면 힙이 초기화되므로 캐시도 함께 사라집니다.
배포 발생 → JVM 재시작 → 캐시 전부 소멸
→ 모든 요청이 캐시 MISS
→ DB 요청 폭증 → Connection Pool 고갈 → 타임아웃평소에는 L1 히트율 95%로 DB 요청이 50건/초였다면,
재시작 직후에는 히트율 0%로 1,000건/초가 DB로 쏟아집니다.
대응 ① 캐시 워밍업 — ApplicationReadyEvent는 Spring Boot가 완전히 기동되고 트래픽을 받기 직전에 발행됩니다. 이 시점에 주요 데이터를 미리 적재해두면 첫 요청부터 히트가 가능합니다.
@Component
@RequiredArgsConstructor
public class CacheWarmupRunner {
private final CategoryService categoryService;
@EventListener(ApplicationReadyEvent.class)
public void warmup() {
try {
categoryService.findAllCategories();
} catch (Exception e) {
log.warn("[CacheWarmup] 실패 - 계속 진행", e);
}
}
}대응 ② 롤링 / 카나리 배포 — 서버를 한 번에 전부 재시작하지 않고 순서대로 한 대씩 재시작합니다. 항상 Warm 인스턴스가 대부분의 트래픽을 소화하므로 DB 부하 폭증을 막을 수 있습니다.
한계 ② — 멀티 인스턴스 데이터 불일치
인스턴스 A 캐시: 가격 = 1,000원 ← 갱신됐지만 아직 모름
인스턴스 B 캐시: 가격 = 1,200원 ← 정상
→ 사용자 요청이 A로 라우팅 → 틀린 가격 응답L2 공유 캐시를 두거나, Redis Pub/Sub로 무효화 이벤트를 전파해 해결합니다.
L2 — 분산 캐시 (Out-of-Process)
Redis처럼 별도 서버에 캐시를 둡니다. 모든 인스턴스가 같은 캐시를 바라보므로 일관성이 보장됩니다.
장점: 인스턴스 간 공유 / 서버 재시작 후에도 유지 가능
단점: 직렬화 비용 + 네트워크 왕복 (~1ms)
도구: Redis Standalone / Sentinel / Cluster
적합: 세션, 목록 조회, 집계 결과DB 대비 10~100배 빠르지만 L1보다는 느립니다. 이 차이는 네트워크가 아니라 Redis는 key를 받으면 바로 반환하는 반면, DB는 SQL 파싱 → 실행 계획 → 인덱스 탐색까지 거쳐야 하기 때문입니다.
Redis는 RDB(스냅샷)와 AOF(명령 로그) 두 가지 영속성 옵션을 제공하지만, 캐시 용도라면 영속성을 끄는 경우도 많습니다. 재시작 후 자연스럽게 Cache Miss → DB 조회 → 캐시 재적재가 되기 때문입니다.
Caffeine을 따로 쓰는 이유
Redis만 쓰면 안 될까요? 단순히 무겁다거나 빠르다는 이유 때문만은 아닙니다.
Caffeine → 힙 메모리 참조 한 번 → ~100ns / 직렬화 없음
Redis → 직렬화 + TCP 송신 + 처리 + TCP 수신 + 역직렬화 → ~1ms초당 수만 건의 읽기 요청에서 1ms가 쌓이면 Redis 자체가 병목이 됩니다. Caffeine이 앞단에서 대부분을 처리해주면 Redis 부하를 크게 줄일 수 있고, Redis 장애 시 Caffeine이 버퍼 역할도 합니다.
요청
↓
L1 (Caffeine) — 히트 시 즉시 반환 (~100ns)
↓ 미스
L2 (Redis) — 히트 시 반환 + L1에도 적재 (~1ms)
↓ 미스
DB — 조회 후 L2 저장 → L1 저장 (~10ms)단, 데이터 변경 시 L1과 L2를 모두 무효화해야 하고, 멀티 인스턴스 환경의 L1 불일치는 Pub/Sub 브로드캐스트나 짧은 TTL로 제어합니다.
L1은 "빠르게", L2는 "공유하며" — 두 계층을 목적에 맞게 조합하는 것이 실무 캐시 설계의 핵심입니다.
마무리
캐시 도입 기준을 한 줄로 정리하면:
"자주 읽히고, DB 조회 비용이 크고, 잘 안 바뀌고, 약간 오래된 값이어도 괜찮은" 데이터에만 씁니다.
도입 전에는 반드시 측정부터, 인덱스와 쿼리 최적화를 먼저 시도한 뒤, 여전히 느릴 때 마지막 수단으로 사용합니다.
캐시는 성능 문제의 최종 해결사가 아니라, 진단을 마친 뒤 선택하는 도구입니다.
읽어주셔서 감사합니다. 틀린 내용이나 보완할 부분이 있으면 댓글로 알려주세요 🙏
