[Paper] Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems
Code as Agent Harness: 앞으로의 AI Agent는 모델보다 Harness가 중요해질지도 모른다
1. 논문 개요
최근 Claude Code, OpenHands, Codex 같은 Coding Agent들을 사용해 보면 흥미로운 사실을 발견할 수 있다.
놀랍게도 같은 LLM을 사용하더라도 Agent의 성능 차이는 매우 크게 나타난다.
어떤 시스템은 몇 분 만에 컨텍스트를 잃어버리고 작업에 실패한다. 반면 어떤 시스템은 수 시간 동안 Repository를 탐색하고, 테스트를 반복하고, 실패를 복구하며 작업을 완성한다.
왜 이런 차이가 발생할까?
우리는 보통 Agent의 성능이 모델에 의해 결정된다고 생각한다. 더 좋은 모델, 더 긴 Context Window, 더 강력한 추론 능력이 좋은 Agent를 만든다고 믿는다.
하지만 이 논문은 전혀 다른 답을 제시한다.
Agent의 성능을 결정하는 것은 모델만이 아니라 Harness다.
그리고 앞으로의 Agent 경쟁은 Model Engineering보다 Harness Engineering에서 벌어질 가능성이 높다고 주장한다.
이번 논문은 이러한 관점을 Code as Agent Harness라는 개념으로 정리한다. 저자들은 코드를 단순한 생성 결과물이 아니라 Agent가 추론하고 행동하며 상태를 관리하는 실행 기반(Runtime Substrate)으로 바라봐야 한다고 설명한다.
한마디로 요약하면 다음과 같다.
Agent는 더 이상 하나의 모델이 아니라, 코드 위에서 동작하는 실행 시스템이다.
2. 문제 정의
현재 대부분의 Agent 연구는 여전히 모델 중심(Model-Centric) 관점을 가지고 있다.
성능을 높이기 위해 더 좋은 모델을 만들고, 더 복잡한 추론 기법을 적용하는 데 집중한다.
하지만 실제 Agent는 단순히 답변을 생성하는 시스템이 아니다.
Agent는 현재 상태를 확인하고, 계획을 세우고, 도구를 사용하고, 실행 결과를 검증한 뒤 다시 행동을 수정하는 과정을 반복한다.
Plan → Execute → Verify → Update State → Replan즉 Agent는 본질적으로 하나의 폐루프(Closed Loop) 시스템이다.
이 과정에서 중요한 것은 모델의 추론 능력만이 아니다.
- 현재 상태를 어디에 저장할 것인가?
- 실패한 작업을 어떻게 복구할 것인가?
- 어떤 정보를 장기적으로 기억할 것인가?
- 여러 Agent는 어떻게 협업할 것인가?
- 실행 결과는 어떻게 검증할 것인가?
이러한 문제는 모델의 문제가 아니라 Runtime의 문제다.
논문은 이러한 Runtime 전체를 Harness라고 정의한다.
3. 기존 연구의 한계
초기 Agent 연구는 대부분 Prompt Engineering 중심으로 발전했다.
Chain of Thought(CoT), ReAct, Reflexion 같은 기법들은 모델 내부의 추론 능력을 향상시키는 데 초점을 맞췄다.
하지만 이러한 접근에는 몇 가지 한계가 존재한다.
-
상태가 지속되지 않는다.
모든 정보가 Prompt 안에 존재하기 때문에 Context Window를 벗어나면 기억이 사라진다. -
검증이 어렵다.
모델이 "정답이다"라고 말하는 것과 실제로 정답인 것은 전혀 다른 문제다. -
장기 작업에 취약하다.
작업이 길어질수록 컨텍스트는 복잡해지고 상태 관리 비용은 증가한다. -
멀티에이전트 확장이 어렵다.
여러 Agent를 추가하더라도 서로 다른 상태를 바라본다면 협업은 실패할 수밖에 없다.
결국 Agent의 성능을 결정하는 것은 단순히 모델의 지능이 아니라, 실행 과정 전체를 관리하는 시스템이라는 사실이 드러나기 시작했다.
4. 이 논문의 핵심 주장
이 논문이 전달하는 메시지는 생각보다 단순하다.
기존에는 Agent 성능을 모델 성능의 함수로 바라봤다.
좋은 Agent = 좋은 LLM하지만 저자들은 이 관점이 더 이상 맞지 않는다고 주장한다.
실제 Agent 시스템은 단순히 답변을 생성하는 모델이 아니라,
- 상태를 저장하고
- 도구를 사용하고
- 코드를 실행하고
- 결과를 검증하고
- 실패를 복구하는
하나의 Runtime System에 가깝다.
같은 Claude 모델을 사용하더라도,
- 어떤 시스템은 장기 작업을 수행하지 못하고
- 어떤 시스템은 수 시간 동안 작업을 이어가며
- 어떤 시스템은 실패 후 복구할 수 있고
- 어떤 시스템은 상태를 잃어버린다
이 차이는 모델보다 Runtime 구조에서 발생한다.
논문은 이를 Harness라는 개념으로 설명한다.
Agent = LLM + Harness이것이 논문 전체를 관통하는 핵심 아이디어다.
5. 제안 방법
논문은 Code as Agent Harness를 세 개의 계층으로 설명한다.
5.1 Harness Interface
가장 아래 계층은 Agent와 환경을 연결하는 인터페이스다.
여기서 코드는 세 가지 역할을 수행한다.
Code for Reasoning
코드를 통해 추론을 외부화한다.
예를 들어 계산 문제를 풀 때 모델이 직접 계산하는 대신 Python 코드를 생성하고 실행해 결과를 검증할 수 있다.
Code for Acting
코드는 Agent의 의도를 실제 행동으로 변환한다.
로봇 제어, GUI 조작, API 호출, 운영체제 명령 실행 등이 여기에 해당한다.
Code for Environment Modeling
코드는 환경 상태를 표현하는 수단이 된다.
Repository, Test, Execution Log, Simulator 등이 모두 Agent가 현재 상황을 이해하기 위한 환경 모델 역할을 수행한다.
즉 논문은 코드가 단순한 산출물이 아니라 Agent와 세상을 연결하는 인터페이스라고 설명한다.
5.2 Harness Mechanisms
두 번째 계층은 Agent가 장기간 안정적으로 동작하도록 만드는 메커니즘이다.
논문은 이를 다섯 가지 요소로 설명한다.
- Planning
- Memory
- Tool Use
- Control
- Optimization
특히 흥미로운 점은 Agent를 한 번에 정답을 생성하는 시스템이 아니라 지속적으로 수정하는 시스템으로 본다는 것이다.
Plan
↓
Execute
↓
Verify
↓
Repair
↓
Execute최근 Coding Agent들이 강력한 성능을 보이는 이유도 여기에 있다.
좋은 Agent는 처음부터 정답을 만드는 Agent가 아니라, 실패를 빠르게 발견하고 수정할 수 있는 Agent다.
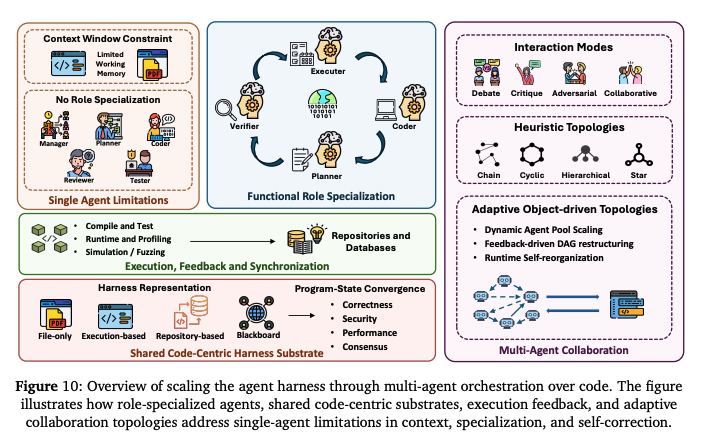
5.3 Scaling the Harness
세 번째 계층은 멀티에이전트 환경이다.
논문은 미래의 Agent 시스템이 단일 모델이 아니라 여러 역할을 가진 Agent 집단으로 발전할 것이라고 전망한다.
예를 들어
- Manager
- Planner
- Coder
- Reviewer
- Tester
와 같은 역할이 존재할 수 있다.
하지만 논문이 강조하는 것은 Agent 수가 아니다.
중요한 것은 모든 Agent가 공유하는 상태 공간이다.
Repository, Memory, Test 결과, 실행 로그와 같은 정보가 공유될 때 비로소 협업이 가능하다.
논문은 이를 Harness Scaling이라고 부른다.
즉, Multi-Agent의 핵심은 Agent를 늘리는 것이 아니라 Shared State를 확장하는 것이다.
6. 논문이 발견한 패턴
이 논문은 새로운 모델이나 알고리즘을 제안하는 연구라기보다 Survey 성격이 강하다.
하지만 다양한 최신 Agent 시스템을 분석하면서 매우 흥미로운 패턴을 발견한다.
최근 성공적인 Agent 시스템들은 모두 비슷한 방향으로 진화하고 있다.
초기의 연구는 더 많은 Agent를 추가하거나 더 큰 모델을 사용하는 데 집중했다.
반면 최근 시스템들은 다음 요소를 중심으로 설계된다.
- Shared Repository
- Long-Term Memory
- Execution Feedback
- Verification Loop
- State Synchronization
흥미로운 점은 성능 향상의 원인이 Agent 수 증가 자체가 아니라는 것이다.
Agent가 몇 명이냐보다 중요한 것은 Agent들이 어떤 상태를 공유하고, 어떤 방식으로 실행 결과를 검증하며, 어떻게 실패를 복구하는가이다.
즉 Agent를 늘리는 것보다 Agent들이 공유하는 Runtime을 만드는 것이 더 중요해지고 있다.
논문은 이러한 흐름을 통해 앞으로의 Agent 발전 방향이 Model Scaling에서 Harness Scaling으로 이동할 것이라고 주장한다.
7. 논문의 기여점
이 논문의 가장 큰 기여는 새로운 알고리즘이 아니다.
오히려 Agent를 바라보는 관점을 재정의했다는 점에 있다.
-
코드를 단순한 생성 결과물이 아니라 Agent Runtime의 핵심 구성요소로 정의했다.
-
Agent 시스템을 Harness Interface, Harness Mechanisms, Scaling Harness라는 구조로 체계화했다.
-
Multi-Agent 문제를 Shared State 관점에서 해석했다.
-
Coding Agent뿐 아니라 GUI Agent, OS Agent, Robotics Agent까지 설명할 수 있는 통합 프레임워크를 제안했다.
-
Harness Engineering이라는 새로운 연구 방향을 정리했다.
8. 한계점
다만 몇 가지 한계도 존재한다.
우선 Survey 논문 특성상 정량적 검증이 부족하다.
Harness가 중요하다는 주장은 설득력이 있지만 이를 객관적으로 측정할 평가 체계는 아직 부족하다.
또한 Shared State, Semantic Verification, Self-Evolving Harness 같은 개념들은 흥미롭지만 여전히 연구 단계에 머물러 있다.
멀티에이전트 환경에서 상태를 어떻게 동기화하고 충돌을 해결할 것인지 역시 앞으로 해결해야 할 중요한 과제다.
결국 이 논문은 완성된 해답이라기보다 앞으로 연구가 나아가야 할 방향을 제시하는 로드맵에 가깝다.
9. 정리 및 느낀 점
그동안 AI 연구는 주로 "어떻게 더 똑똑한 모델을 만들 것인가?"에 집중해왔다. 이후 Prompt Engineering이 등장하면서 모델의 능력을 더 잘 끌어내는 방법이 중요해졌고, 최근에는 Agent Engineering이라는 새로운 흐름이 나타나고 있다.
앞으로 Agent의 경쟁력은 모델 선택보다도
- 상태를 어떻게 저장하는가
- 실행을 어떻게 검증하는가
- 실패를 어떻게 복구하는가
- 여러 Agent를 어떻게 협업시키는가
와 같은 Harness 설계에서 나올 가능성이 높다.
실제로 최근 Claude Code, OpenHands, Cursor와 같은 시스템들이 보여주는 성능 향상 역시 모델 자체의 발전만으로 설명하기 어렵다. 코드를 실행하고, 결과를 검증하며, 상태를 유지하고, 실패를 수정하는 Runtime 구조가 Agent의 성능을 크게 좌우하고 있다.
그리고 개인적으로는 이 논문의 가장 중요한 메시지도 여기에 있다고 생각한다.
앞으로의 Agent 경쟁은 더 좋은 모델을 만드는 경쟁이 아니라, 더 좋은 Harness를 설계하는 경쟁이 될 수 있다.
(지금은 Harenss가 중요해지고 있지만, 이게 최종일지 아닐지는 아무도 모름.)
