https://arxiv.org/pdf/2503.10150
1. 들어가며
Retrieval-Augmented Generation (RAG)은 LLM의 환각(hallucination)을 줄이고, 도메인 특화 문제 해결 능력을 높여주는 대표적인 기법이다. 하지만 기존 RAG는 두 가지 큰 한계가 있다.
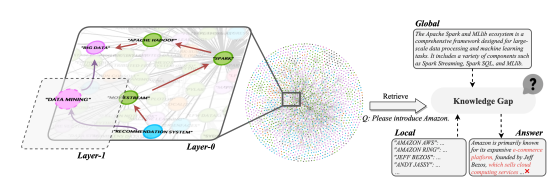
- Sematic gap in graph: 의미적으로 가까운 entity들이 KG에서는 멀리 떨어져 있어, 검색과 추론이 어렵다.
- Knowledge gap: local knowledge와 global knowledge가 따로 작동하면서, 둘 사이에 불일치가 발생한다.
HiRAG(Hierarchical RAG)는 이 두 문제를 계층적 인덱싱(HiIndex)과 3단계 검색(HiRetrieval)으로 해결한다.
2. 기존 연구의 한계
- GraphRAG: Leiden 알고리즘 기반 community 검색 → structural proximity만 반영, semantic similarity 부족.
- KAG: 계층적 표현은 있지만 human-annotated schema에 의존 → 확장성 낮음.
- LightRAG: local & global knowledge를 모두 사용하지만, knowledge gap 무시 → 불완전한 답변 발생.
즉, 지금까지의 방법들은 멀리 떨어진 semantic neighbors와 local-global 불일치를 해결하지 못함
3. HiRAG의 핵심 아이디어
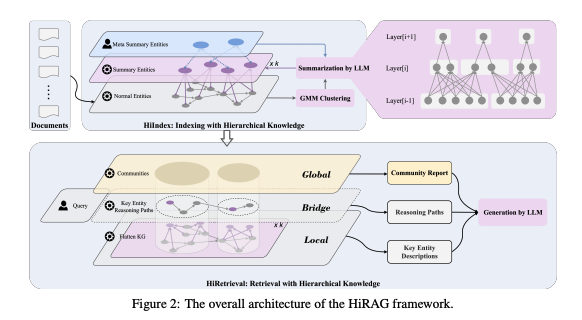
3.1 HiIndex (Hierarchical Indexing)
- 평면적(flat) KG 대신 계층적 KG를 구축.
- 각 레이어에서 entity embeddings를 클러스터링하고, LLM으로 summary entities를 생성.
- 예:
BIG DATA와RECOMMENDATION SYSTEM이 상위 레이어의DATA MININGSummary entity로 묶이며 의미적 연결 강화.
공식 예시
기본 KG 에서 시작해, 상위 레이어로 갈수록 entity set 와 relation set 가 확장된다.
3.2 HiRetrieval (Hierarchical Retrieval)
답변을 위해 3단계 지식을 함께 검색:
- Local: 쿼리와 가장 가까운 entity 설명
- Global: 관련 community report
- Bridge: local과 global을 잇는 shortest path 기반 reasoning path
Bridge는 특히 중요하다. 실험에 따르면, bridge knowledge가 없을 경우 모든 데이터셋에서 성능이 크게 떨어졌다.
4. 실험 결과
4.1 Query-Focused Summarization (QFS)
- UltraDomain 벤치마크 (Mix, CS, Legal, Agriculture dataset) 사용.
- 평가 기준: Comprehensiveness, Empowerment, Diversity, Overall quality.
- GPT-4o evaluator 기준, HiRAG의 win rate는 대부분 60~90% 이상으로 모든 baseline을 압도.
4.2 Multi-Hop QA (MHQA)
- 2WikiMultiHopQA, HotpotQA에서 EM, F1 모두 최고 성능 기록.
- 최신 baseline(HippoRAG2)보다도 더 우월.
4.3 Efficiency
- Indexing 비용: Mix dataset 기준 약 $7.55 (offline 과정).
- Retrieval 비용: KAG, LightRAG은 검색 시에도 토큰 비용 발생, 반면 HiRAG은 추가 토큰 비용 0.
5. 심화 포인트
5.1 계층 수 결정
-
cluster Sparsity (CSi) 지표 도입:
-
희소도가 더 이상 개선되지 않으면 계층 생성 중단 (𝜖=5% 기준).
5.2 Bridge Knowledge Coverage
- Bridge knowledge는 local knowledge의 64~83%, global knowledge의 38~53%를 포괄.
- 지역–전역 간 간극을 효과적으로 메워줌.
5.3 사례 연구
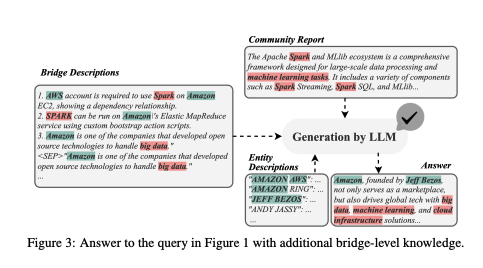
- 쿼리:
"Amazon을 소개해주세요." - Local: 자회사, 경영징 등 entity 중심 정보.
- Global: 빅데이터, 클라우드 컴퓨팅 같은 기술적 측명.
- Bridge: 두 층위 연결 → Amazon을
“전자상거래 기업이자 클라우드 제공자”로 올바르게 설명.
- 쿼리:
"당뇨병 합병증 관리 핵심은?" - Local: HbA1c, Metformin, SGLT2 inhibitor, 혈압조절, LDL 목표…
- Global:
Community: Cardiometabolic care
Report: 당뇨 관리는 혈당·혈압·지질의 다요인 관리가 표준이며… - Bridge:
(HbA1c control) -[reduces]-> (Microvascular complications)
(SGLT2 inhibitor) -[benefits]-> (Heart Failure)
(Statin) -[reduces]-> (ASCVD risk)
6. 한계와 향후 과제
- 비용: indexing시 토큰 소모와 시간 지연이 큼. (병렬화로 완화 가능)
- 검색 모듈: 현재는 LLM 기반 가중치에 의존함 ranking → 더 정교한 메커니즘 필요.
7. 정리 (Takeaways)
- HiRAG = Hierarchical KG + Bridge Retrieval
- 의미적으로 가까운 entity를 더 잘 연결하고, local-global gap을 해소.
- 결과적으로 더 정확하고 일관된 답변을 생성.
- 특히 법률, 과학, 기술 문서 같은 대규모 지식 환경에서 유용.

끄적끄적