SQL 시작하기
SQL이란?
- 우선 데이터 베이스란 여러 사람이 공유해 사용할 목적으로 통합하여 관리되는 데이터의 모음으로 MriaDB, Amazon Redshift, Oracle DB 등 많은 종류가 있음
- SQL(Structured Query Language)이란 데이터 베이스에 접근하고 조작하기 위한 표준 언어
테이블의 구조 알아보기
- DESC 'Table명' : table에 대한 정보(desc는 내림차순이라는 의미도 있음)
테이블에서 데이터 검색하기
-
관계형 데이터베이스: 하나 이상의 테이블로 이루어지며 서로 연결된 데이터를 가지고 있음, SQL을 통해 제어 가능
-
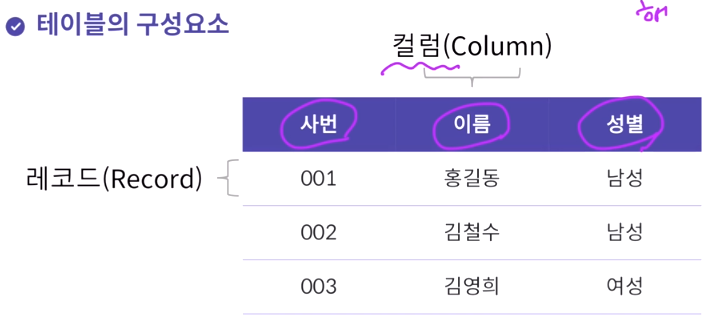
테이블의 구성요소: 컬럼과 레코드로 구성된 표, 모든 테이블은 고유의 이름으로 구분
-
SELECT로 검색
-SELECT *은 모든 데이터(테이블 용량이 5GB가 넘으면 멈춤)
-select distinct 제목, 저자 : 한 쪽 컬럼에 중복값이 있어도 다른 쪽 컬럼의 값이 다르면 다르게 취급(A가 쓴 어린왕자와 B가 쓴 어린왕자를 다르게 취급)
조건을 추가하여 검색하기
select * from book where title = '돈키호테'
여러 개의 조건을 추가하기
-
select * from score where korean >= 90 or math>80 -
기타연산자
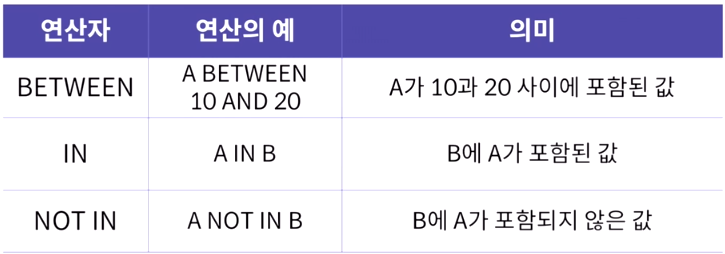 BETWEEN에서 10과 20도 포함임
BETWEEN에서 10과 20도 포함임 -
여러개의 or은 in을 사용할 수 있음
select * from book where title = 'hi' or title = 'bye' or title = 'hello'; => select * from book where title in ('hi', 'bye', 'hello');
데이터를 제어하는 DML
테이블에서 유사한 값 찾기
- Like
select * from book where title like '어린왕자'; // where title like '%왕자'; 왕자로 끝나는 거 검색 // where title like '%린왕%'; 중간에 린왕이 들어가는 거 검색
데이터 정렬하기
- order by
select * from score order by math desc // 기본은 오름차순(ASC), DESC 사용하면 내림차순
테이블에 데이터 삽입하기
- insert
 컬럼을 적지 않아도 되지만 그러면 값을 순서대로 입력해줘야함
컬럼을 적지 않아도 되지만 그러면 값을 순서대로 입력해줘야함
테이블에 데이터 수정하기
- update

테이블에 데이터 삭제하기
- delete
 where 조건문이 없으면 book 테이블의 모든 데이터 삭제
where 조건문이 없으면 book 테이블의 모든 데이터 삭제
SQL과 함수
- count : 데이터 개수를 가져오는 내장함수로 NULL은 제외
select count(id) from book;
limit

sum & avg
-
sum : 지정한 컬럼들의 값을 모두 더하여 총점을 구해주는 내장함수
select sum(math) from score; -
avg
select avg(math) from score;
max & min
-
max : 숫자형만이 아니라 문자형도 가능
select max(korean) from score; -
min
select min(korean) from score;
다수의 테이블 제어하기
데이터 그룹 짓기
select user_id, count(*) from rental group by user_id;
데이터 그룹에 조건 적용하기
select user_id, count(*) from rental group by user_id having count(user_id) >= 2;
두개의 테이블에서 조회하기
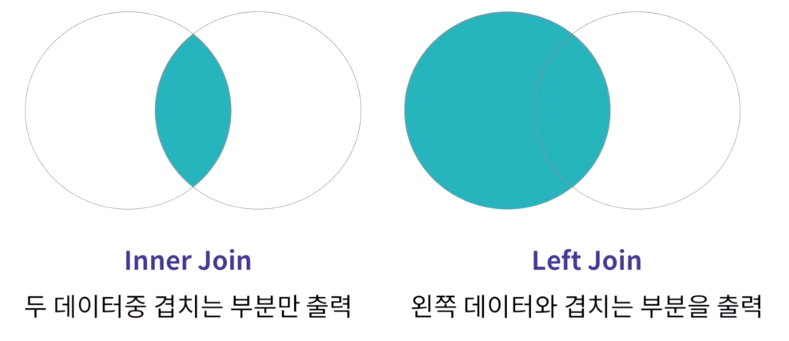
- INNER JOIN
select * from rental inner join user; // inner join '연결할 테이블'
조건을 적용해 두개의 테이블 조회하기
- INNER JOIN / ON
select * from rental inner join user // user 테이블과 inner join on user.id = rental.user_id // user 테이블의 id와 rental 테이블의 user_id가 같은 애들끼리
LEFT JOIN
-
왼쪽 테이블의 모든 값을 포함하여 연결하기
select * from rental left join user on user.id = rental.user_id // user 테이블을 모두 출력하되 // 모든 user 테이블의 user_id와 rental테이블의 id가 겹치도록 합친다. -
inner join vs left join
RIGHT JOIN
- 오른쪽 테이블의 모든 값을 포함하여 연결하기
select * from user right join rental on user.id = rental.user_id // 중심이 되어야 할 테이블이 right join 뒤에 나와야함
서브쿼리
서브쿼리
- 하나의 쿼리 안에 포함된 또 하나의 쿼리
- 메인쿼리가 서브쿼리를 포함하는 종속적인 관계
- 특징
- 알려지지 않은 기준을 이용한 검색에 유용
- 메인쿼리가 실행되기 이전에 한 번만 실행
- 한 문장에서 여러번 사용 가능
//기존 방법 select * from employee where 급여 > 2500; // 2500이 elice의 급여 //서브쿼리 사용 select * from employee where 급여 > (select 급여 from employee where 이름 = 'elice'); // elice의 급여를 몰라도 elice의 급여보다 높은 급여 찾기 가능
- 사용시 주의사항
- 서브쿼리는 반드시 괄호와 함께 사용되어야 한다.
- 서브쿼리 안에서 order by 절은 사용할 수 없다.
- 서브쿼리는 연산자의 오른쪽에 사용되어야 한다.
- 서브쿼리는 오로지 SELECT문으로만 작성할 수 있다.
반환에 따른 분류
- 단일행 서브쿼리 : 서브쿼리의 조회 결과가 1개의 행만 나오는 서브쿼리
- 단일행 서브쿼리 연산자: <>(같지 않다)
- 다중행 서브쿼리 : 서브쿼리가 결과를 2개 이상 반환하고, 이 결과를 메인쿼리로 전달하는 쿼리
select * from employee where 급여 in (select max(급여) from employee group by 부서번호); - 다중행 연산자 : in(하나라도 만족하면 반환), any(하나라도 만족하면 반환, 비교 연산 가능), all(모두 만족하면 반환, 비교 연산 가능)
- <any : 최대값, >any : 최소값, >all : 최대값, <all : 최소값
위치에 따른 분류
- 스칼라 서브쿼리 : SELECT절에서 사용하는 서브쿼리, 스칼라 서브쿼리는 오직 한 행만 반환, 마치 JOIN을 사용한 것과 같은 결과를 나타냄(데이터가 많을 때 join보다 계산 속도가 빠름)
select students.name, ( select math from middle_test as m where m.student_id = students.student_id) as middle_avg from students;
