위 블로그 내용은 아래의 유튜브 및 블로그 글을 참고했습니다.
- https://nlpinkorean.github.io/illustrated-transformer/
- @adityathiruvengadam/transformer-architecture-attention-is-all-you-need
- https://sonsnotation.blogspot.com/2020/11/10-3-transformer-model.html
Transformer Algorithm이 나타난 배경부터 설명하고자 함
1. Seq2Seq | RNN, LSTM, GRU
- 문장의 모든 단어가 축약된 Context Vector를 사용하여 end가 나올 때까지 번역을 진행, 이를 Seq2Seq라 부름
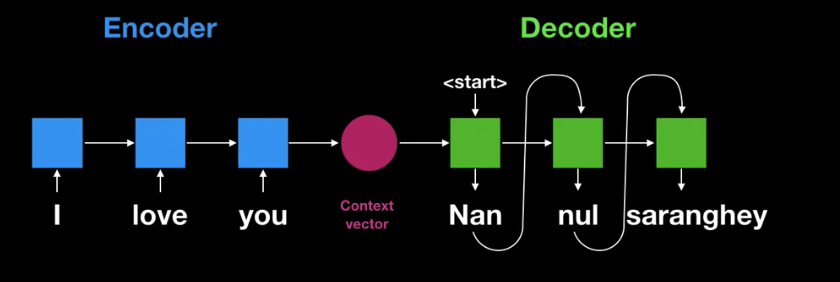
- 그러나 Encoder Decoder 구조 문제가 한가지 존재함, Fixed Size
- Context vector는 고정된 사이즈의 벡터이기 때문에 input 단어의 사이즈가 클 경우에는 모든 정보를 함축하기에는 문제가 있음
- 이를 극복하기 위해 Attention Mechanism을 사용함
2. Attention + Seq2Seq
- Seq2Seq와 같이 인코더에서 나온 마지막 State(Context Vector)를 사용하는 것이 아닌 RNN셀에서 나온 각 각의 인코더 state를 활용하여 Decoder에서 다양한 Context Vector를 만들어서 번역하는 것
- RNN Decoder는 end 시그널이 나올때까지 진행됨
- 문맥 벡터가 고정된 크기이기 때문에 문장이 길 경우 해당 문맥벡터에 모든 정보를 넣지 못해서 번역이 망가짐
- 해당 문제를 해결하기 위해 Attention이 나타남
- Attention은 고정된 문백 벡터가 아닌 Encoder의 모든 상태값을 사용하기 때문에(각 State 별로 Context Vector를 생성) 긴 문장의 번역 성능이 좋아짐
- 또한 Encoder 내 모든 state에서 집중해야하는 단어들에만 집중하게 만드는 mechanism 설계가 가능함
- 그러나 Attention + Seq2Seq은 Encoder와 Decoder의 성능을 높였지만 느리다는 단점이 있었음
- 그 결과 RNN, CNN을 제외한 Attention만으로도 중요한 정보를 찾아내서 단어를 인코딩할 수 있지 않을까 생각함
- 그 결과로 나온 것이 Attention is all you need, Transformer
3. Transformer
- 기존 Encoder, Decoder를 발전시킨 딥러닝 모델이지만, RNN 및 CNN을 사용하지 않는다는 것이 차이점
- RNN을 사용하지 않고, Parallelization(병렬화)를 사용해 빠른 계산이 가능
- RNN은 단어를 하나씩 받아서 변환하여서 디코더로 넣는 반면 Transformer는 일을 한번에 처리함
- RNN의 순차적인 계산은 Transformer에서 단순 행렬곱으로 한번에 처리할 수 있음
- Transformer에서도 번역은 start로 시작해서 end로 끝나
- 자연어처리에서 RNN을 많이 사용하는 이유는 단어의 위치와 순서정보를 이용하는 것이 중요하기 때문
- Encoding 안에는 여러개의 Encoder이 있고, Decoding 안에는
3-1. Encoder
- Multihead Self-Attention과 Feed Forward Neural Network 두개의 sub-layer로 구성되어있음
- Multihead Self-Attention은 Encoder Self-Attention이라고도 부름
- 인코더 이미지, 단어를 워드임베딩화
- 포지셔널 인코딩을 적용
- Multihead Attention에 입력
- 그 결과를 모두 이어 붙여서 또다른 행렬과 곱함
- 처음 워드임베딩과 동일한 차원으로 출력되어야 하기 때문
- ????? 각 각의 벡터는 fc로 들어가서 입력과 동일한 사이즈의 벡터를 출력할 것
- 출력 벡터 차원의 크기는 워드임베딩과 차원이 같음
- 워드 임베딩에 포지셔널 임베딩 더해줬지만 딥러닝으로 backpropagation하다보면 이 포지셔널 인코딩 값이 손실될 수 있음
- 이를 보완하기 위해 Residual Connection으로 입력된 값을 다시 한번 더해줌
- Residual Connection 뒤에는 Layer Normalization 사용해서 학습의 효율을 증진시킴
- 즉, Encoder 내의 Sub-Layer가 Residual Connection으로 연결되어있으며, 그 후에는 Layer Normalization 과정을 거침
Encoder에서 중요하게 생각해야 하는 부분
- 입력 벡터와 output 벡터의 차원이 같다
- 이 말은 즉, 인코더 레이어를 여러개 붙여서 사용할 수 있다는 것
- 실제 Transformer Encoder는 같은 Encoding 레이어를 6개 붙여서 사용하고 있음
- 각 인코더 레이어들은 서로의 모델 파라미터(가중치)를 동일하게 하지 않고 따로 학습시킴
- Transformer Encoder의 최종 출력값은 6번째 Encoding 레이어의 출력값
3-1-1. Embedding
- Embedding 알고리즘을 이용해 입력단어를 vector로 변환
- Embedding하는 이유는 input data를 vector화 시키기 위함
- 각 단어들은 크기 512의 벡터 하나로 embedded됨
- 벡터 리스트의 사이즈는 hyperparameter로 자체 설정 가능함
- simply하게는 학습 데이터셋에서 가장 긴 문장의 길이로 세팅
3-1-2. Positional Encoding
- RNN이 없는 Transformer는 단어위치 정보를 어떻게 사용할까
- Encoder, Decoder 입력값마다 상대적인 위치정보를 더해주는 기술인 Positional Encoding 사용
- Transformer를 사용하지 않을 경우 I study at school 이라는 문장을 encoder에 넣을 때 I에는 001을 더해줬고 study에는 010, at에는 011, - school에는 100을 더해줌
- Transformer는 bit적 Positional Encoding이 아닌 sin과 cos function을 사용한 Positional Encoding을 사용
- 즉, Embedding값에 Positional Encoding 벡터를 더하는 것
- Positional Encoding 벡터들을 단어들의 embedding에 추가하는 것이 Query/Key/Value 벡터들로 나중에 투영되었을 때 단어들 간의 거리를 늘리는 역할을 함
- sin, cos function의 사용 장점은 항상 positional encoding의 값이 -1 < <1 사이의 값이 나온다는 것
- 학습된 문장보다 더 긴 문장이 test로 들어와도 positional encoding이 에러를 일으키지 않음
* sin과 cos을 이용한 Positional Encoding 값 제공 Method
- Positional Encoding 값을 더하여 위치 정보 값을 제공함
- 즉, 문장 단어의 나열을 왼 to 오 로 가정했을 때 오른쪽에 있는 단어일수록 큰 Positional Encoding 값을 지정함

- Positional Encoding 값은 sin과 cos를 이용하는데 그 식은 아래와 같음
- 단어 위치 pos와 각 단어의 벡터의 Index i가 주어졌을 때 Positional Encoding(PE)값을 구하는 방법
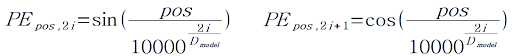
- 아래 이미지와 같이 10진법의 수를 2진법으로 표현했을 때(2진수의 자리수로 10차원을 나타냈을 때) 작은 수는 앞부분에만 1의 값을 갖고 있고 큰 수는 뒷 부분에도 1의 값을 갖고 있음
- 즉, 큰 값을 가질수록(Position이 뒷부분일수록) 큰 Positional Encoding 값을 가짐
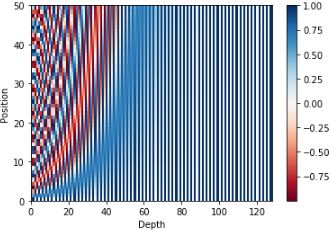
- 아래 Plot은 126차원으로 Embedding된 단어 vector를 Position Encoding 시킨 결과

3-1-3. Multihead Self Attention(Encoder Self-Attention)
- 워드 임베딩한 이후에는 벡터의 형태를 input으로 받음
- Encoder가 하나의 단어를 encode하기 위해서 입력내의 다른 단어들과의 관계를 확인하는 과정
- Self-Attention은 입력 문장 내의 다른 위치에 있는 단어들을 보고 거기서 힌트를 받아 현재 타겟 위치의 단어를 더 잘 encoding함
1) 1st Process
- Encoder에 입력된 벡터들로부터 Wq, Wk, Wv 행렬과 곱해짐으로써 각 단어에 대한 Query, Key, Value 3개의 벡터를 생성
- x1 * WQ(weight 행렬) = q1(현재 단어와 연관된 query 벡터)
- 행렬은 행렬끼리 곱해질 수 있기 때문에 각 문장에 있는 단어들의 Q, K, V는 한번에 계산됨
- Q, K, V(벡터의 형태)만 있으면 Self Attention 수행이 가능함
- 실제로는 Self Attention에서 Q, K, V 벡터들은 하나의 행렬 X로 쌓아 올리고 학습할 weight 행렬들인 Wq, Wk, Wv와 곱하는 것(설명은 벡터로 진행)
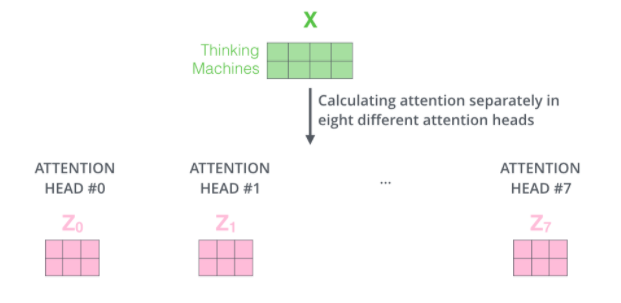
- 8개의 Multi head attention를 이용하기 때문에 각 head에서 각 각 Q, K, V 행렬을 가짐
- 각 head의 weight는 다르기 때문에 8개의 서로 다른 Z행렬을 얻음
- 행렬 X의 각 행은 입력 문장의 각 단어에 해당함
2. 2nd Process
- 한 단어와 입력 문장 속의 다른 모든 단어들에 대해서 각각 점수를 계산
- 해당 점수는 현재 위치의 이 단어를 encode 할 때 다른 단어들에 대해서 얼마나 집중을 해야 할지를 결정
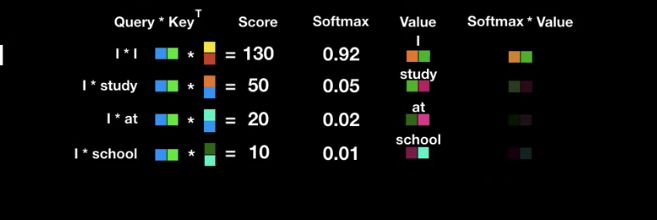
- 현재 단어의 Query vector와 점수를 매기려 하는 다른 위치에 있는 단어의 Key vector의 내적으로 계산
- Query와 Key를 곱한것을 Attention Score라 칭함
- Query와 Key가 둘 다 벡터이기 때문에 dot product으로 곱하면 그 값은 숫자로 나옴
- 숫자가 높을수록 단어간 연관성이 높다는 것
- 현재위치의 단어가 당연하게도 가장 높은 값을 가지는 것을 확인할 수 있음
3. 3nd Process
- Key vector의 차원이 늘어날수록 dot product 계산시 값이 증대되는 문제가 일어나기 때문에 이를 보완하기 위해 Scaling 진행
- 그리고 그 값을 Key vector 차원수의 sqrt 값으로 나눔
- 논문에서는 Key vector 차원수가 64이기 때문에 8로 나눔
- 그 결과 더 안정적인 Gradient를 얻게 됨
- softmax 적용()하여 값들을 모두 양수로 만든 후 그 합을 1로 만듦
- softmax 결과값은 Key 값에 해당하는 단어가 현재 단어에 어느정도 연관성이 있는지를 나타냄
- Multihead Attention의 계산 복잡도를 낮추기 위해서는 Q, K, V 벡터는 기존의 벡터보다 작은 사이즈여야 함(논문에서는 input vector의 크기가 512, 새로운 vector의 크기가 64)

4. 4th Process
- 입력 단어의 value 벡터에 해당 점수를 곱함
- 집중을 하고 싶은 관련이 있는 단어들은 남겨두고, 관련이 없는 단어들은 같은 작은 점수값들이기 때문에 곱하여 없애버리기 위함
- 아까 들었던 예시를 기준으로 하면, I와 I는 92%, I와 study는 5%, at은 2%, school은 1%의 연관성이 있다 나옴 -> 각 %를 각 value에 곱해주면 연관성이 없는 value는 값이 희미해짐 -> 최종값 softmax * value의 값을 모두 더해줌 -> 이 최종 벡터는 단순히 단어 하나 I가 아닌 문장 속에서 I가 지닌 전체적인 의미를 가진 벡터라고 간주할 수 있음
5. 5th Process
- Weighted Value(softmax값 * value값) 벡터들을 다 합함
- 해당 값이 현재 위치(단어)에 대한 Self Attention Layer의 출력이 됨
- 8개의 Multi head attention를 이용하기 때문에 각 head에서 각 각 Q, K, V 행렬을 가짐
- 각 head의 weight는 다르기 때문에 8개의 서로 다른 Z행렬을 얻음
- 이렇게 얻은 결과는 바로 Feed Forward에 보낼 수가 없음
- Feed Forward에서는 한개의 행렬만을 input으로 받기 때문에
- 그래서 또 하나의 행렬 weight인 W0을 곱해서 하나의 결과값을 얻음
- 결과값을 Position wise Feed Forward의 input으로 넣음

Feed Forward
- Self Attention의 output을 input으로 받아 각 위치의 단어마다 독립적으로 적용되 출력을 생성
3-2. Decoder
- Encoder와 유사하게 생김
- Encoder와 같이 Decoding Layer 6개로 이뤄져 있음
- 논문에서는 Encoding Layer와 Decoding Layer의 숫자를 동일하게 만들었지만 굳이 맞추어야 할 필요는 없어 보임
- attention 병렬처리 사용
- Decoder Layer는 Multihead Attention Layer(Encoder Self-Attention), Position wise Feed Forward, Residual Connection으로 이루어진 Encoder Layer와 구성이 비슷하지만 차이점이 존재
- Decoder Layer는
1) Masked Multihead Self-Attention(Masked Decoder Self-Attention)
2)Multihead Attention(Encoder-Decoder Attention)
3)Position wise Feed Forward
4)Residual Connection - Decoder의 Multihead attention은 Masked Multihead Attention
- Masked라는 것은 지금까지 출력된 값들에만 Attention을 적용하기 위해 붙여진 이름
- Decoding을 할 때 미래의 단어에 Attention을 적용하지 않기 위함
- 다음은 Multihead Attention(Encoder-Decoder Attention)
- Encoder처럼 Query, Key, Value로 연산하는데, Encoder Multihead Attention과의 차이점이 존재
- Decoder는 현재 Decoder의 입력값을 Query로 사용하고, Encoder의 최종 출력값을 Key와 Value로 사용한다는 점
- 즉, Decoder의 현재 상태를 Q로, Encoder 출력값에서 중요한 정보를 Key와 Value로 획득해서 Decoder의 다음 단어에 가장 적합한 단어를 출력하는 과정
- 그리고 Position wise Feed Forward Layer로 최종값을 벡터로 출력
- 해당 벡터를 실제 단어로 출력하기 위해서 Linear Layer와 Softmax Layer를 사용
- Linear Layer는 Softmax에 들어갈 logit을 생성
- Softmax는 모델이 알고있는 모든 단어들에 대한 확률을 출력, 그리고 가장 높은 확률을 지닌 값이 다음 단어로 예측되는것
- Transformer는 최종 단계에도 Label Smoothing이라는 기술을 사용해서 모델의 퍼포먼스를 한단계 업그레이드 시킴
- 보통 딥러닝 모델을 Softmax로 학습할 경우 Label을 onehot encoding으로 전환시키는데 Transformer는 onehot이 아닌 0과 1에 가깝지만 극단이 아닌 그 사이의 값으로 나타냄
- 즉, 0또는 1이 아닌 정답은 1에 가까운 값, 오답은 0에 가까운 값으로 변화를 주는 기술을 label smoothing이라 일컬음
- 이는 모델학습시에 학습 데이터에 치중하지 않도록 보완하는 과정
- 학습데이터가 깔끔하고 label값이 깔끔할 경우 label smoothing은 도움이 되지 않을 수도 있지만 Label이 noisy한 경우 즉, 같은 입력값인데 다른 출력값이 학습 데이터에 많을 경우 Labeling Smoothing은 큰 도움이 됨
- 같은 데이터에 상이한 label이 있을 경우 모델 파라미터가 커졌다가 작아졌다가 반복학습하는 과정에서 좋은 결과가 나오지 않을테니까
- 예시) thank you -> 번역 -> 1. 고마워 2. 감사합니다 레이블이 2개. 잘못된 것은 아니지만 원핫인코딩을 두 레이블에 적용하게 되면 고마워와 감사합니다 두 레이블은 온전히 상이한 값. 그래서 학습이 잘 되지 않음. 이럴 경우 label smoothing을 적용하면 두 레이블이 조금이라도 가까운 벡터값이 되고 softmax 출력값과 label 값의 차이가 줄어들것이기 때문에 더 나은 방법이라 말하는 것

:)