Keda 공식 홈페이지
Keda 구성 시 참고 주소
과연 kubernetes에서 제공해주는 기본 hpa 말고 개발환경에 맞는 pod 오토스케일링은 안되는 걸까? 라는 호기심으로 시작하여 알아보니 prometheus와 연동하여 prometheus의 지표를 사용하여 오토스케일링 하는 방법이 있어 적용하는 과정입니다 !
Keda란?
- Kubernetes 이벤트 기반 기반 자동 확장 솔루션입니다.
- Kubernetes-based Event Driven Autoscaler
- 모든 K8S에 설치할 수 있으며 HPA(Horizontal Pod Autoscaler)와 같은 표준 쿠버네티스 구성 요소와 함께 작동 할 수 있습니다.
- Kubernetes 클러스터에 KEDA를 설치하면 두 개의 컨테이너가 실행 됩니다.
- Keda-operator
- 배포, 상태 저장 집합 또는 롤아웃을 0에서 이벤트 없이 0으로 확장하는 것 ( 사용 X )
- keda-operator-metrics-apiserver
- Keda-operator
- KEDA는 큐 길이 또는 스트림 지연과 같은 풍부한 이벤트 데이터를 HPA에 노출하여 스케일 아웃을 유도하는 Kubernetes 메트릭 서버 역할을 합니다.
- 메트릭 제공은 두번째 컨테이너인 keda-operator-metrics-apiserver의 기본 역할입니다.
- CNCF 제단과 MS의 공동 개발
Keda 특징
- 간편한 자동 확장
- Kubernetes의 모든 워크로드에 풍부한 확장성 제공 무리
- 이벤트 기반
- 이벤트 기반 애플리케이션을 지능적으로 확장
- 내장 스케일러
- 다양한 클라우드 플랫폼, 데이터베이스, 메시징 시스템, 원격 측정 시스템, CICD 등을 위한 50개 이상의 내장 스케일러 카탈로그
- 여러 워크로드 유형
- /scale 하위 리소스가 있는 배포, 작업 및 사용자 지정 리소스와 같은 다양한 워크로드 유형 지원
- 환경 영향 감소
- 워크로드 스케줄링 및 0으로 확장을 최적화하여 지속 가능한 플랫폼 구축
- 확장 가능
- 직접 가져오거나 커뮤니티에서 관리하는 스케일러 사용
- 공급업체 불가지론
- 다양한 클라우드 제공업체 및 제품 전반에 걸친 트리거 지원
- Azure,aws 기능 지원
KEDA 기반으로 확장 할 수 있는 이벤트 소스 중 Prometheus랑 연동하여 스케일
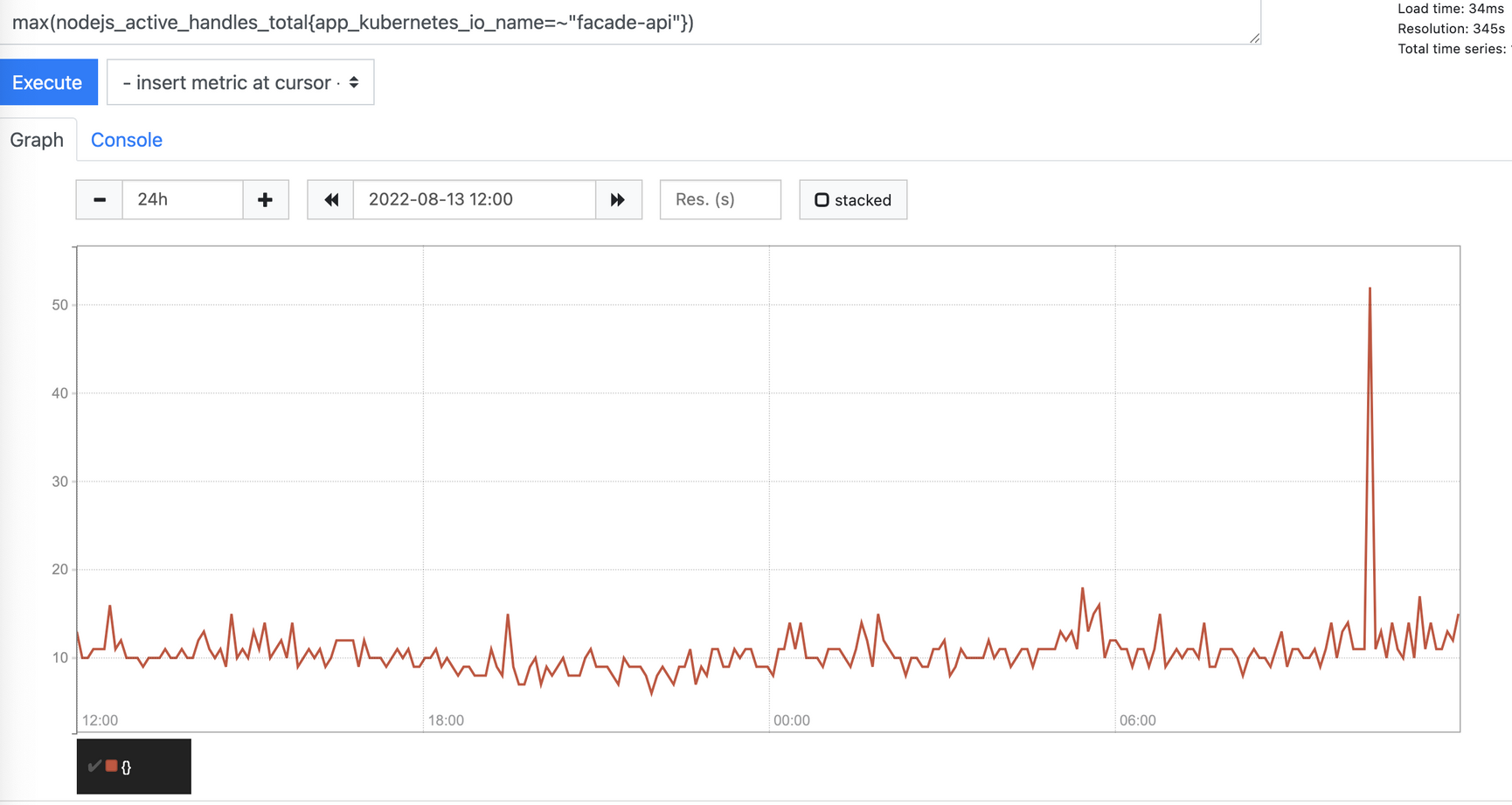
ex) Facade API, node.js 등 CPU와 Memory 지표를 가지고 스케일이 어려운 상황이므로 Prometheus랑 연동하여 스케일
사용목적
- AWS 환경에서 낮은 버전의 Kubernetesd에서의 오토스케일링 문제 해결을 위한 Keda 서비스 도입
- 오토스크일링을 더욱더 세분화해서 하기위해서
- 프로매태우스랑 Keda와 연동하여 생성
- node.js 개발 특성상 CPU,Memory 등 리소스들을 효율적으로 사용하기 때문에 기존 kubernetes에서 지원하는 horizon 지표인 cpu, memory 등으로 스케일링 불가
- prometheus 지표를 활용하여 효율적인 오토스케일링을 위한 작업
설치
- 설치는 helm을 이용하여 keda 설치
helm 설치 가이드
helm으로 설치
~~helm 설치 (mac-os)
$ brew install helm~~
스크립트로 helm 설치
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
$ chmod 700 get_helm.sh
$ ./get_helm.sh
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm repo update
~~# keda를 설치할 namespace 생성
$ kubectl create namespace keda
$ helm install keda kedacore/keda --namespace keda~~
keda 삭제 시 주의사항
scaleobject를 제외하고 패키지만 삭제 시 불필요한 scaleobject들이 남아있어 리소스를 먼저 삭제 후
keda 삭제
for i in $(kubectl get scaledobjects -oname);
do kubectl patch $i -p '{"metadata":{"finalizers":null}}' --type=merge
done
for i in $(kubectl get scaledjobs -oname);
do kubectl patch $i -p '{"metadata":{"finalizers":null}}' --type=merge
doneKeda-helm-repo 받기
$ helm pull keda kedacore/keda
$ tar xvf ~
$ cd kedaPrometheus의 매트릭을 이용하는 scale 예시 yaml
apiVersion: v1
kind: Secret
metadata:
name: keda-prom-secret
namespace: default
data:
username: "dXNlcm5hbWUK" # Must be base64
password: "cGFzc3dvcmQK" # Must be base64
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-prom-creds
namespace: default
spec:
secretTargetRef:
- parameter: username
name: keda-prom-secret
key: username
- parameter: password
name: keda-prom-secret
key: password
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: facade-api
namespace: ns
spec:
pollingInterval: 60
minReplicaCount: 1
maxReplicaCount: 10
scaleTargetRef:
name: facade-api
triggers:
- type: prometheus
metadata:
serverAddress:
metricName: http_requests_total
threshold: '60'
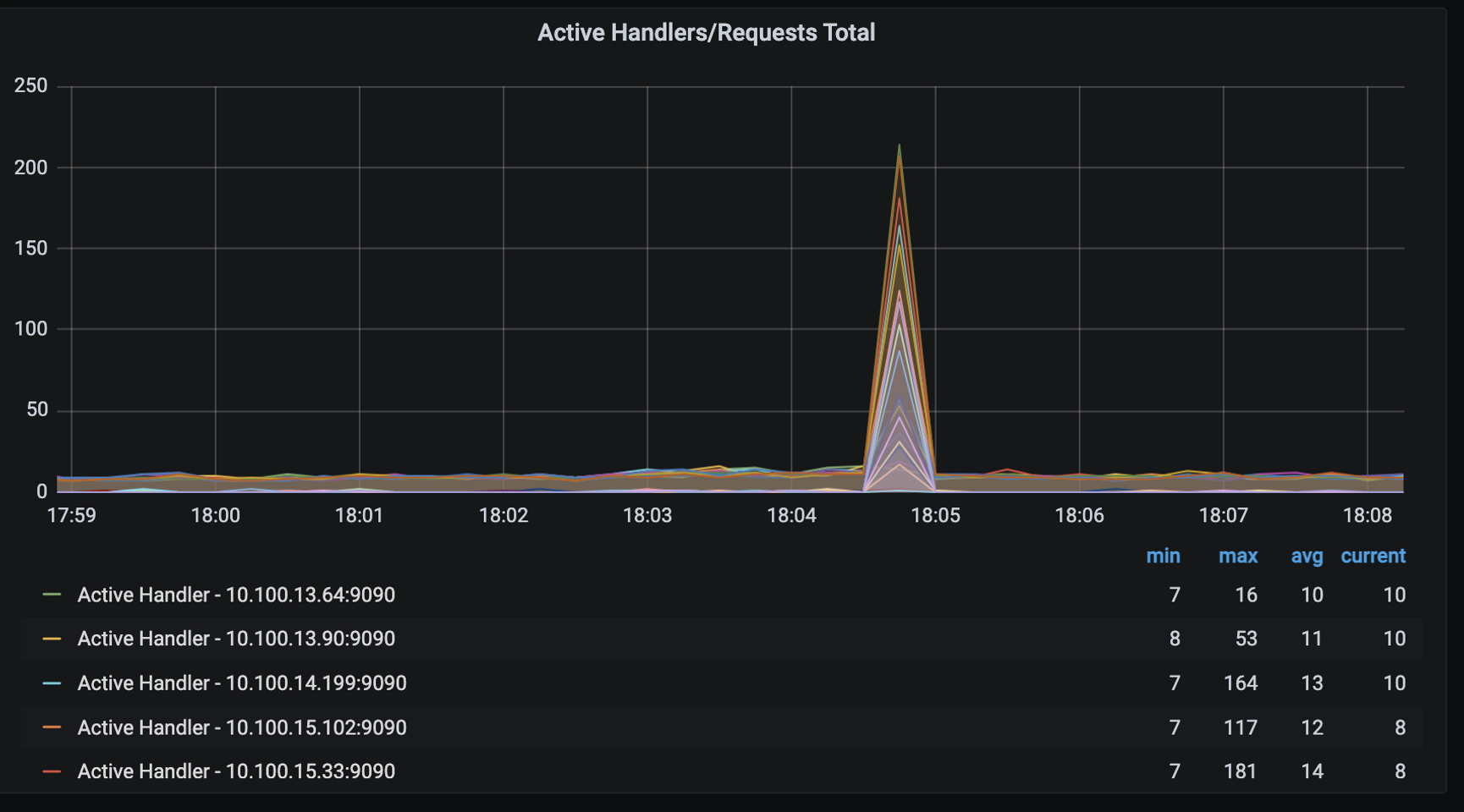
query: max(nodejs_active_handles_total{app_kubernetes_io_name=~"facade-api"})
# sum(rate(http_requests_total{deployment="my-deployment"}[2m]))
# authModes: "basic"
# authenticationRef:
# name: keda-prom-creds매개변수 목록
- serverAddress
- 프로메테우스의 주소
- metricName
- external.metrics.k8s.io API에서 메트릭을 식별하기 위한 이름. 둘 이상의 트리거를 사용하는 경우 모두 metricName이 고유해야함
- query
- 실행할 쿼리
- threshold
- 확장을 시작할 값 (소수점 설정도 가능)
- activationThreshold
- 스케일러를 활성화하기 위한 목표 값
- pollingInterval
- 각 트리거를 확인하는 간격. 기본으로 default 30초마다 모든 sclaedobject에서 각 트리거 소스를 확인
- 현재 구조상 짧은 시간에 급격하게 오르는 스파이크 현상에 대비하여 pollingInterval을 설정하여 불필요한 오토스케일링 작업을 방지
실제 사용할 코드
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: api
namespace: [오토스케일을 설정하고 싶은 리소스가 존재하는 ns에 설정]
spec:
pollingInterval: 60 # 초 단위
minReplicaCount: 1
maxReplicaCount: 10
scaleTargetRef:
name: facade-api
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus.[prometheus가 설치된 ns].svc.cluster.local:9090
metricName: nodejs_active_handles_total
threshold: '60'
query: max(nodejs_active_handles_total{app_kubernetes_io_name=~"facade-api"})
# sum(rate(http_requests_total{deployment="my-deployment"}[2m]))
# authModes: "basic"
# authenticationRef:
# name: keda-prom-creds
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
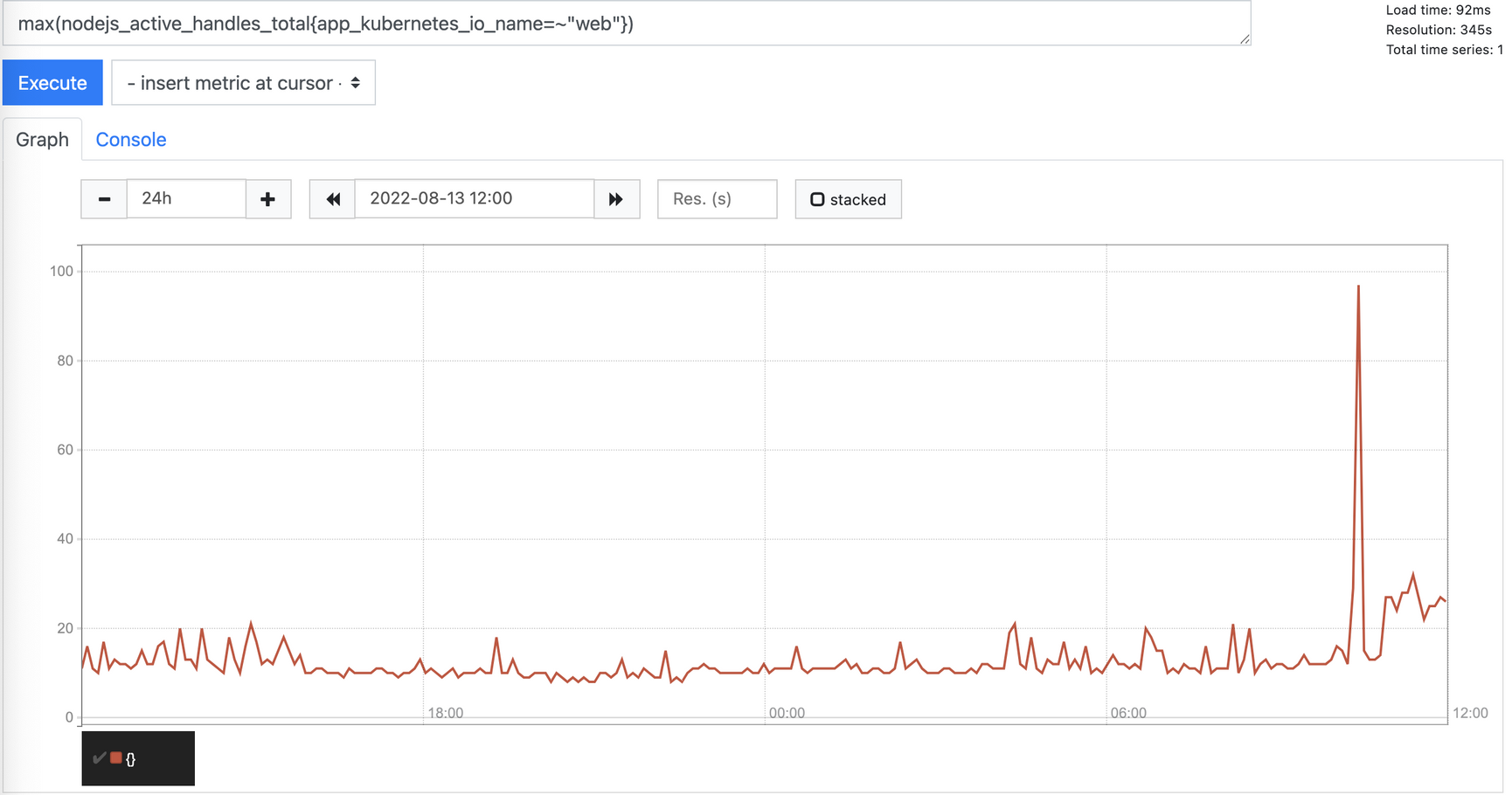
name: web
namespace: [오토스케일을 설정하고 싶은 리소스가 존재하는 ns에 설정]
spec:
pollingInterval: 60
minReplicaCount: 2
maxReplicaCount: 10
scaleTargetRef:
name: web
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus.[prometheus가 설치된 ns].svc.cluster.local:9090
metricName: nodejs_active_handles_total_web
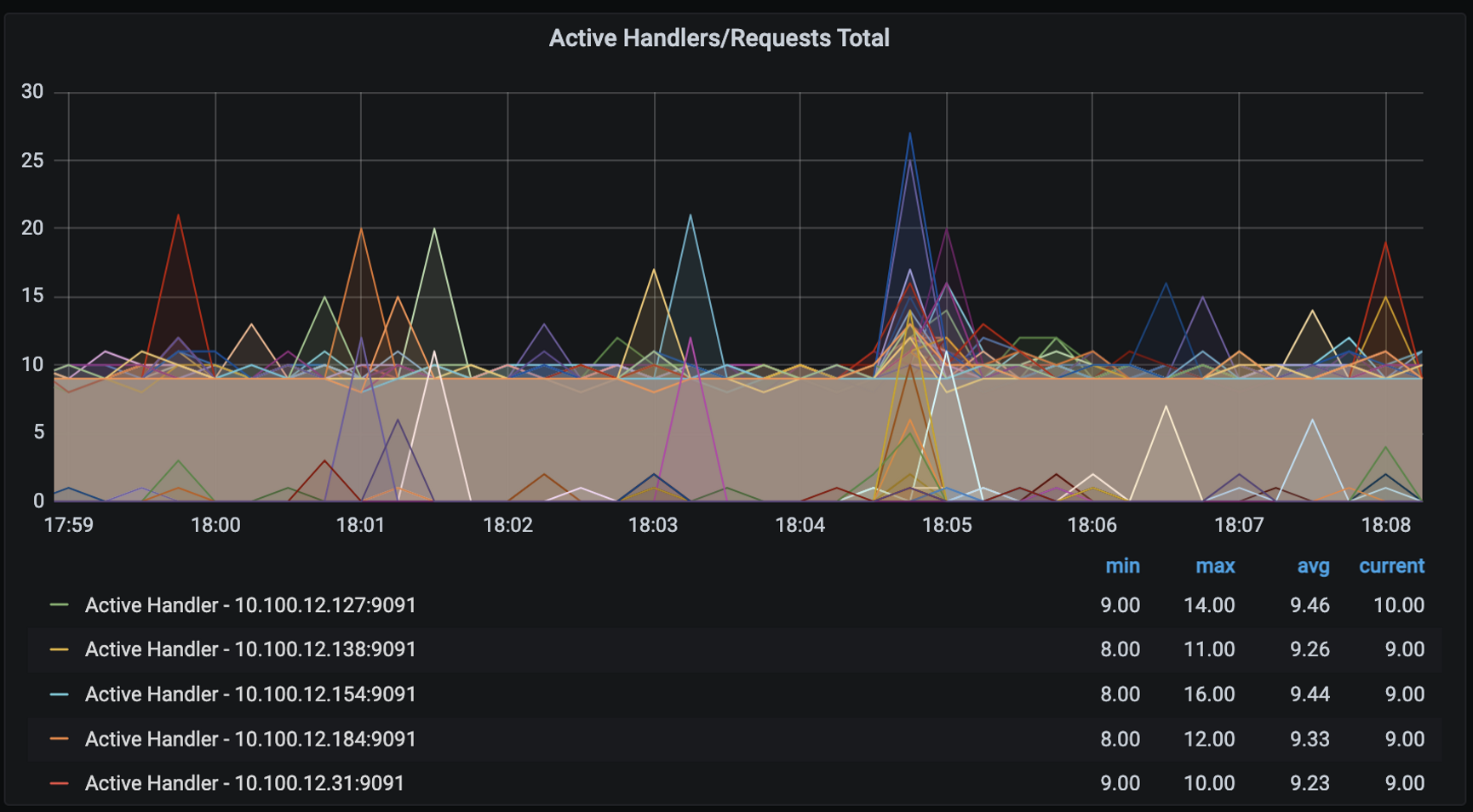
threshold: '40'
query: max(nodejs_active_handles_total{app_kubernetes_io_name=~"web"})측정항목의 쿼리 값
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/YOUR_NAMESPACE/YOUR_METRIC_NAME"
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/[namespace]/nodejs_active_handles_total_web"
여러 ScaledObject가 동일한 메트릭 이름을 가질 때 메트릭을 얻는 방법
kubectl get scaledobject SCALEDOBJECT_NAME -n NAMESPACE -o jsonpath={.metadata.labels}
kubectl get scaledobject web -n NAMESPACE -o jsonpath={.metadata.labels}
kubectl get scaledobject facade-api -n NAMESPACE -o jsonpath={.metadata.labels}
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/sample-ns/s1-rabbitmq-queueName2?labelSelector=scaledobject.keda.sh%2Fname%3D{ScaledObjectName}"
Facade
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/[namespace]/s0-prometheus-nodejs_active_handles_total?labelSelector=scaledobject.keda.sh%2Fname%3Dfacade-api"
Web
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/[namespace]/s0-prometheus-nodejs_active_handles_total_web?labelSelector=scaledobject.keda.sh%2Fname%3Dweb"1차 TEST
TEST - 방법
부하TEST를 하기에는 추가적인 비용이 발생하므로 threshold의 값을 임의로 낮추어서 test 진행
- threshold: 40 → threshold: 3
TEST part.1 - 순서
-
threshold: 40 → threshold: 3


-
interval이 걸려 있으므로 1분 대기
-
5/3 hpa가 동작 (1분 소요)
-
deployment 상태도 1

-
5/3 이므로 hpa 스케일링 시작
-
deploy에서 pod 개수가 순차적으로 증가하는 모습


-
web의 pod 수가 [1 → 2] , [2 → 3] 증가 후 hpa에서 자원들이 안정화 된 모습 - 1667m/3

-
threshold: 3 → threshold: 40으로 늘려 준 뒤

정상적으로 pod들도 내려간 모습
2차 TEST
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: web
namespace: [오토스케일을 설정하고 싶은 리소스가 존재하는 ns에 설정]
spec:
pollingInterval: 60
minReplicaCount: 1
maxReplicaCount: 10
scaleTargetRef:
name: web
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus.[prometheus가 설치된 ns].svc.cluster.local:9090
metricName: nodejs_active_handles_total_web
threshold: '20' # 수치를 낮춰서 진행
query: max(nodejs_active_handles_total{app_kubernetes_io_name=~"web"})
#sum(rate(http_requests_total{deployment="my-deployment"}[2m]))
# authModes: "basic"
# authenticationRef:
# name: keda-prom-credsTEST part.2 - 순서
-
threshold: 40 → threshold: 20
- MINPODS → 1
- MAXPODS → 10

-
interval이 걸려 있으므로 1분 대기
-
ngrinder를 활용하여 부하진행

- nGrinder configuration
- Agent: 8
- Vuser per agent: 20
- Script: frontend/main_stress.groovy
- Target Host: [target-url]
- Duration: 00:02:00 (HH:MM:SS)
- nGrinder configuration
-
5/20 hpa가 동작 (1분 소요)
-
deployment 상태도 1
-
209/20 이므로 hpa 스케일링 시작

![kubectl get hpa -n [namespace] -w 시 web의 TARGETS = 209
prometheus = 209
동일한 쿼리 사용 확인](https://s3-us-west-2.amazonaws.com/secure.notion-static.com/42421f41-24c2-4786-9f6b-41ef6630c9b1/Untitled.png)
kubectl get hpa -n [namespace] -w 시 web의 TARGETS = 209
prometheus = 209
동일한 쿼리 사용 확인![kubectl get hpa -n [namespace] -w 시 TARGETS = 97
prometheus = 97
동일한 쿼리 사용 확인](https://s3-us-west-2.amazonaws.com/secure.notion-static.com/5a776755-446d-48ed-a269-45bf59d2fb1a/Untitled.png)
kubectl get hpa -n [namespace] -w 시 TARGETS = 97
prometheus = 97
동일한 쿼리 사용 확인- 정상적으로 부하를 걸기 전 TARGETS 5/20
- 부하 진행 중 facade-api가 97/60으로 오토스케일링 중 replicas 1 → 2 로 증가
- web 209/20 이므로 오토스케일링 증가 replicas 1 → 4 로 증가
-
deploy에서 pod 개수가 순차적으로 증가하는 모습

-
web의 pod 수가 [1 → 10] 증가 후 hpa에서 자원들이 안정화 된 모습 - 500m/20
- 동일하게 facade-api도 감소한 모습

-
test 마무리 부하 test 종료시 5/20 안정적이므로 rplicas가 내려간 모습
interval 1분으로 인하여 1분이 지난 뒤 감소한 모습 정상적으로 pod들도 내려간 모습
