
키워드
In-memoryDB : 모든 데이터를 메모리에 저장하고 조회하는 인메모리 데이터베이스
NoSQL : Not Only SQL, RDBMS가 갖고 있는 특성뿐만 아니라, 다른 특성들을 부가적으로 지원한다
싱글 스레드 : 하나의 트랜잭션은 하나의 명령만 실행
cache : 한 번 읽어온 데이터를 임의의 공간에 저장하여, 다음에 읽을 때는 빠르게 결과값을 받을 수 있도록 도와주는 공간
영속성 : 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성
global cache : 여러 서버에서 Cache Server에 접근하여 사용하는 캐시
local cache : Local 장비 내에서만 사용 되는 캐시, Local 장비의 Resource를 이용한다 (Memory, Disk)
트랜잭션 : 쪼갤 수 없는 업무 처리의 최소 단위
Redis
✔ Redis란?
redis는 오픈소스로서 데이터베이스(NOSQL DBMS)로 분류가 되기도 하고 Memcached와 같이 인메모리 솔루션으로 분류되기도 한다.
성능은 memcached에 버금가면서 다양한 데이터 구조체를 지원함으로써 Message Queue, Shared memory, Remote Dictionary 용도로도 사용될 수 있으며, 이런 이유로 인스타그램, 네이버 재팬의 LINE 메신져 서비스, StackOverflow,Blizzard,digg 등 여러 소셜 서비스에 널리 사용되고 있다.
✔️ NoSQL 관점
NoSQL관점에서 봤을 때 redis는 가장 단순한 키-밸류 타입을 사용하고 있다. 데이터 모델은 복잡할수록 성능이 떨어지므로 redis는 단순한 구조를 통해 높은 성능을 보장한다고 할 수 있다.
NoSQL에는 다양한 제품이 있지만 이 중, redis가 주목받는 이유는 다음과 같다.
- 데이터 저장소로 가장 입/출력이 빠른 메모리를 채택
- 단순한 구조의 데이터 모델인 키- 밸류 방식을 통해 빠른 속도를 보장
- 캐시 및 데이터스토어에 유리
- 다양한 API지원
✔️ 캐싱 솔루션 관점
redis, memcached, 구아바 라이브러리등 인메모리 캐시방식을 적용한 제품 중 redis는 global cache 방식을 채택하였다. global cache 방식은 네트워크 트래픽이 발생하기 때문에 java heap영역에서 조회되는 local cache의 성능이 더 낫지만, WAS 인스턴스가 증가할 경우엔 캐시에 저장되는 데이터 크기가 커질수록 redis 방식이 더 유리하다.
redis는 급격한 사용자가 집중되는 상황이나 대규모의 확장이 예정되어 있는 환경에 적합하다. global cache 방식이 적용되어 was 인스턴스 확장에는 유리하지만 cache 및 redis 세션 등 관리 포인트가 늘어난다는 단점이 존재한다.
✔ NoSQL과 Redis
✔️ 사례로 보는 NoSQL로써의 Redis
사용자 증가로 인한 서비스 중단의 원인이 DB 서버일때, 너무 많은 SQL 문 처리 요청을 받아 MySQL이 동시에 처리할 수 있는 한계치를 넘어섰고 그로 인해 응답시간이 길어질 수 있다. MySQL 서버의 응답시간 지연이 발생하여 톰캣 서버에서 DB 서버로의 네트워크 연결이 모두 끊어졌다. 이런 상황은 어떻게 대처해야 할까?
2가지의 방안이 있다.
1.서비스를 멈추고 단일 서버의 성능을 증가시켜서 더 많은 요청을 처리하는 방법을 스케일 업이라고 한다.
-> 통상적으로 스케일 업을 적용하면 서비스의 중단이나 추가 하드웨어 비용이 발생한다.
2.서비스를 멈추고 새로운 서버에 기존 서버의 데이터를 옮겨 다시 새롭게 서비스를 시작한다.
-> 서비스 중지 상태에서 데이터를 옮기고 데이터를 정리하느라 많은 시간소요
이에 반해서 대부분의 NoSQL은 처음부터 스케일 아웃을 염두에 두고 설계되었기 때문에 데이터의 증가나 요청량이 증가하더라도 동일하거나 비슷한 사양의 새로운 하드웨어를 추가하면 대응이 가능하다. 데이터가 적거나 또는 요청량이 적을때는 일반 RDBMS를 사용하더라도 서비스를 제공하는데 문제가 없다. 하지만 데이터 증가량을 측정하기 불가능하거나 서비스 요청량의 증가를 예측하기 어려운 상황에서는 NoSQL을 저장소로 사용하는 것이 현명한 선택이 될것이다.
멤캐시드와 레디스를 같은 캐시 캐시 시스템으로서 동등한 위치에서 비교하게 된것은 레디스가 멤캐시드와 동일한 기능을 제공하면서 영속성, 다양한 데이터 구조와 같은 부가적인 기능을 지원하기 때문이다. 또한 특정한 조건에서는 멤캐시드에 비해서 더 나은 성능을 보여주기도 한다. 이와 같은 이유로 레디스는 멤캐시드를 대체하는 솔루션으로 주목 받았다.
레디스는 모든 데이터를 메모리에 저장하고 조회한다. 즉, 인메모리 데이터베이스 솔루션이다. 빠른 성능은 레디스의 특징 중 일부분에 지나지 않는다. 다른 인메모리 솔루션들과의 차이점 중 가장 특별한 점은 레디스의 '다양한 자료구조'다.
✔️ Key/Value Store
특정 키 값에 값을 저장하는 구조로 되어 있고 기본적인 PUT/ GET Operation을 지원한다. 단, 이 모든 데이터는 메모리에 저장되고 이로 인해 매우 빠른 write/read 속도를 보장한다. 그래서 전체 저장 가능한 데이터 용량은 물리적인 메모리 크기를 넘어설 수 있다(물론 OS의 disk swapping 영역 등을 사용해 확장은 가능하겠지만 성능이 급격하게 떨어지기 때문에 의미가 없다). 데이터 액세스는 메모리에서 일어나지만 서버 재시작(server restart)과 같이 서버가 내려갔다가 올라오는 상황에 데이터의 저장을 보장하기 위해 디스크를 persistence store로 사용한다.
✔️ 레디스의 데이터타입
모든 데이터를 메모리에 저장하고 조회하기때문에 빠른 Read, Write 속도를 보장하고 또 다양한 자료구조를 지원한다는 점이다.
📑 Redis가 지원하는 데이터 형식
String, List, Set, Sorted Set, Hash
| 메소드명 | 반환 오퍼레이션 | Redis 자료구조 |
|---|---|---|
opsForValue() | ValueOperations | String |
opsForList() | ListOperations | List |
opsForSet() | SetOperations | Set |
opsForZSet() | ZSetOperations | Sorted Set |
opsForHash() | HashOperations | Hash |
다양한 자료구조를 지원하게 되면 개발의 편의성이 좋아지고 난이도가 낮아진다.

예를들어 어떤 데이터를 정렬을 해야하는 상황이 있을 때 DBMS를 이용한다면 DB에 데이터를 저장하고 -> 저장된 데이터를 정렬하여 -> 다시 읽어오는 과정은 디스크에 직접 접근을 해야하기 때문에 시간이 더 걸린다는 단점이 있다. 이 때 In Memory 데이터베이스인 Redis를 이용하고 레디스에서 제공하는 Sorted Set이라는 자료구조를 사용하면 더 빠르고 간단하게 데이터를 정렬할 수 있다.
✔ 싱글 스레드 기반의 Redis
Redis 4.0 부터 4개의 스레드로 동작합니다. 메인스레드 1개, 시스템 명령들을 처리하는 thread 3개
메인스레드에서 사용자 명령어를 처리하기에 싱글 스레드로 동작한다고 이해하면 됩니다.
싱글 스레드로 동작하고 해시 기반의 get/set 을 지원하기에 Redis 의 주요 기능들이 O(1) 시간복잡도로 빠르게 처리되며, 데이터를 일관성있게 유지할 수 있습니다.
(자주 비교되는 맴캐쉬드는 멀티 스레드 지원)
Keys(저장된 모든키를 보여주는 명령어)나 flushall(모든 데이터 삭제)등의 명령어를 사용할 때, 맴캐쉬드의 경우 1ms정도 소요되지만 레디스의 경우 100만건의 데이터 기준 1초로 엄청난 속도 차이가 있다.
-> 많은 키(100,000,000,000개) 건 적은 키(1개) 건 스키마가 많건 적건 동일한 시간이 사용된다.
✔️싱글 스레드 기반의 Redis 주의사항
주의해야할 점은 redis 는 single thread 기반이기에 시간이 오래 걸리는 명령어를 사용할 경우 뒤에 있는 명령어들은 기다려야하므로 성능에 영향을 줄 수 있습니다.
✔ 서버 복제 지원
Master - slave 구조로, 여러개의 복제본을 만들 수 있다. 데이터베이스 읽기를 확장할 수 있기 때문에 높은 가용성(오랜 시간동안 고장나지 않음) 클러스터를 제공한다.
✔ 트랜젝션
트렌잭션이란.. 트랜잭션으로 묶게 되면 트랜잭션 내부에서 하나의 로직이 실패하여 오류가 나게되면 모두 취소시키며 그렇지 않으면 모두 성공시키는 것이다. Redis는 이 트랜잭션 기능을 지원한다.
✔ Pub / Sub messaging
Publish(발행)과 Sub(구독)방식의 메시지를 패턴 검색이 가능하다. 따라서 높은 성능을 요구하는 채팅, 실시간 스트리밍, SNS 피드 그리고 서버상호통신에 사용할 수 있다.
메시지들을 queue로 관리하지 않고, publish 하는 시점 기준으로 미리 subscribe 등록 대기 중인 클라이언트들을 대상으로만 메시지를 전달한다.
✔ 위치기반 데이터 타입 지원
Redis는 실시간 위치기반데이터를 지원한다. 두 위치의 거리를 찾거나, 사이에 있는 요소 찾기등의 작업을 수행할 수 있다.
면접 예상 질문
Q1. RDBMS, NOSQL 차이점
- RDBMS, NOSQL 차이점
- RDBMS
RDBMS는 관계형 데이터베이스 관리 시스템으로서, 구성된 테이블끼리 관계를 맺고 모여있는 집합체입니다. 테이블 형식으로 속성, 값으로 이루어져 있습니다. 트랜잭션 처리가 가능하고, 스키마를 미리 정의해 줘야해서 테이블 생성문으로 정의해줍니다.
CREATE TABLE member(
id int not null auto_increment primary key,
name varchar(10) nut null,
password varchar(12) not null,
reg_date datetime not null
);- NOSQL
NoSQL은 테이블 간의 관계를 정의하지 않고 key-value로 이루어져있습니다. 정해진 스키마가 없고 데이터의 입출이 자유로워서 대용량 데이터를 저장하는데 용이합니다. 몽고디비, 레디스 등이 있습니다.
오토 샤딩 기능이 있어서 대용량 데이터를 자동으로 분산 처리합니다. (RDB도 비슷한 기능인 클러스터링이 있지만 설정이 복잡)
명확한 스키마가 필요하고, 데이터 중복을 허용하지 않는 경우 RDBMS를 사용합니다. 반대로 정확한 데이터 구조가 있지 않고 데이터가 확장이 될 수 있는 경우 NoSql을 사용합니다.
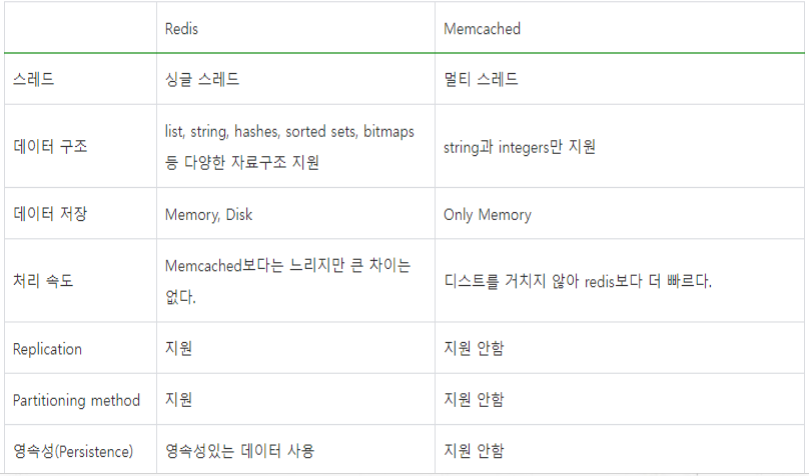
Q2. Memcached vs Redis
맴캐쉬드는 명료하고 단순함을 위하여 개발된 반면,
레디스는 다양한 용도에 효과적으로 사용할 수 있도록 많은 특징을 가지고 개발되었다.
Q3. Redis는 왜 사용해야할까?
Redis는 아직도 활발하게 현재 시장에서 많이 사용되고 있습니다.
기본적으로 서비스 환경에서는 확장성을 고려해서 Redis를 사용하는 것이 일반적으로 좋아 보입니다.
- 보다 광범위한 데이터 구조 및 스트림 처리 기능에 대한 액세스가 필요합니다.
- 키와 값을 제자리에서 수정하고 변경할 수 있는 기능이 필요합니다.
- 사용자 지정 데이터 제거 정책이 필요합니다. (예: 시스템의 메모리가 부족하더라도 키를 더 긴 TTL로 유지해야 함)
- 백업 및 웜 재시작을 위해 데이터를 디스크에 유지해야 합니다.
- 복제본 및 클러스터링을 통해 애플리케이션의 높은 가용성 또는 확장성을 확보해야 합니다.
참고 문헌
[데이터베이스] Redis란?
Redis 레디스 특징, 장단점, Memcached와 redis 비교
[Redis] 이것이 레디스다(1) - NoSQL
주목받는 NoSQL & Cache 솔루션 : Redis
캐시(Cache) Local Cache & Global Cache
레디스는 언제 어떻게 사용하면 좋을까
